Der Autor hat Software in the Public Interest ausgewählt, um eine Spende als Teil von https://do.co/w4do zu erhalten -cta [Write for DOnations] Programm.
Einführung
Der Elastic Stack - früher als ELK Stack bezeichnet - ist eine Sammlung von Open-Source-Software, die von Elastic erstellt wurde und das Suchen, Analysieren und Visualisieren von Protokollen ermöglicht, die von einer beliebigen Quelle in erstellt wurden ein beliebiges Format, eine als zentralisierte Protokollierung bekannte Praxis. Die zentrale Protokollierung kann sehr nützlich sein, wenn Sie versuchen, Probleme mit Ihren Servern oder Anwendungen zu identifizieren, da Sie alle Ihre Protokolle an einem einzigen Ort durchsuchen können. Dies ist auch nützlich, da Sie Probleme identifizieren können, die sich über mehrere Server erstrecken, indem Sie deren Protokolle während eines bestimmten Zeitraums korrelieren.
Der Elastic Stack besteht aus vier Hauptkomponenten:
-
Elasticsearch: Eine verteilte RESTful Suchmaschine, die alle gesammelten Daten speichert.
-
Logstash: Die Datenverarbeitungskomponente des Elastic Stack, die eingehende Daten an Elasticsearch sendet.
-
Kibana: Eine Weboberfläche zum Suchen und Visualisieren von Protokollen.
-
Beats: Leichte, universelle Datenversender, die Daten von Hunderten oder Tausenden von Maschinen an Logstash oder Elasticsearch senden können.
In diesem Tutorial installieren Sie den Elastic Stack auf einem CentOS 7-Server. Sie lernen, wie Sie alle Komponenten des Elastic Stacks installieren - einschließlich Filebeat, einem Beat zum Weiterleiten und Zentralisieren von Protokollen und Dateien Sammeln und Visualisieren von Systemprotokollen. Da Kibana normalerweise nur auf dem + localhost + verfügbar ist, werden Sie Nginx als Proxy verwenden, damit über einen Webbrowser darauf zugegriffen werden kann. Am Ende dieses Lernprogramms werden alle diese Komponenten auf einem einzelnen Server installiert, der als "Elastic Stack-Server" bezeichnet wird.
Voraussetzungen
Um dieses Tutorial abzuschließen, benötigen Sie Folgendes:
-
Ein CentOS 7-Server wird wie folgt eingerichtet: Initial Server Setup with CentOS 7, einschließlich eines Nicht-Root-Benutzers mit sudo Berechtigungen und eine firewall. Die Menge an CPU, RAM und Speicher, die Ihr Elastic Stack-Server benötigt, hängt von der Menge an Protokollen ab, die Sie sammeln möchten. In diesem Lernprogramm verwenden Sie einen VPS mit den folgenden Spezifikationen für unseren Elastic Stack-Server:
-
Betriebssystem: CentOS 7.5
-
RAM: 4 GB
-
CPU: 2
-
Java 8 - das von Elasticsearch und Logstash benötigt wird - ist auf Ihrem Server installiert. Beachten Sie, dass Java 9 nicht unterstützt wird. Um dies zu installieren, folgen Sie dem Abschnitt https://www.digitalocean.com/community/tutorials/how-to-install-java-on-centos-and-fedora#install-openjdk-8[ "Install OpenJDK 8 JRE" in unserer Anleitung zur Installation von Java unter CentOS.
-
Nginx ist auf Ihrem Server installiert und wird später in diesem Handbuch als Reverse-Proxy für Kibana konfiguriert. Folgen Sie unserer Anleitung unter How To Install Nginx on CentOS 7, um dies einzurichten.
Da der Elastic Stack außerdem für den Zugriff auf wichtige Informationen zu Ihrem Server verwendet wird, auf die nicht autorisierte Benutzer zugreifen sollen, ist es wichtig, dass Sie Ihren Server durch die Installation eines TLS / SSL-Zertifikats schützen. Dies ist optional, aber * dringend empfohlen *. Da Sie im Verlauf dieses Handbuchs letztendlich Änderungen an Ihrem Nginx-Serverblock vornehmen werden, empfehlen wir, diese Sicherheit durch Ausfüllen der https://www.digitalocean.com/community/tutorials/how-to-secure-nginx- zu gewährleisten. with-let-s-encrypt-on-centos-7 [Lassen Sie uns auf CentOS 7 verschlüsseln] führt Sie direkt nach dem zweiten Schritt dieses Tutorials.
Wenn Sie Let’s Encrypt auf Ihrem Server konfigurieren möchten, müssen Sie zuvor Folgendes tun:
-
Ein vollqualifizierter Domänenname (FQDN). In diesem Tutorial wird durchgehend "++" verwendet. Sie können einen Domain-Namen unter https://namecheap.com [Namecheap] erwerben, einen kostenlosen unter Freenom erhalten oder den Domain-Registrar Ihrer Wahl verwenden .
-
Die beiden folgenden DNS-Einträge wurden für Ihren Server eingerichtet. Unter https://www.digitalocean.com/community/tutorials/an-einführung-zu-digitalocean-dns finden Sie Informationen zum Hinzufügen von DNS.
-
Ein A-Datensatz mit "++", der auf die öffentliche IP-Adresse Ihres Servers verweist.
-
Ein A-Eintrag mit "+ www. +" Verweist auf die öffentliche IP-Adresse Ihres Servers.
Schritt 1 - Installieren und Konfigurieren von Elasticsearch
Die Elastic Stack-Komponenten sind standardmäßig nicht über den Paket-Manager verfügbar. Sie können sie jedoch mit "+ yum +" installieren, indem Sie das Paket-Repository von Elastic hinzufügen.
Alle Pakete des Elastic Stacks sind mit dem Elasticsearch-Signaturschlüssel signiert, um Ihr System vor Spoofing zu schützen. Pakete, die mit dem Schlüssel authentifiziert wurden, werden von Ihrem Paketmanager als vertrauenswürdig eingestuft. In diesem Schritt importieren Sie den öffentlichen GPG-Schlüssel von Elasticsearch und fügen das Elastic-Repository hinzu, um Elasticsearch zu installieren.
Führen Sie den folgenden Befehl aus, um den öffentlichen Signaturschlüssel von Elasticsearch herunterzuladen und zu installieren:
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchFügen Sie als Nächstes das elastische Repository hinzu. Verwenden Sie Ihren bevorzugten Texteditor, um die Datei "+ elasticsearch.repo " im Verzeichnis " / etc / yum.repos.d / +" zu erstellen. Hier verwenden wir den vi Texteditor:
sudo vi /etc/yum.repos.d/elasticsearch.repoUm yum mit den Informationen zu versorgen, die zum Herunterladen und Installieren der Komponenten des elastischen Stapels erforderlich sind, rufen Sie den Einfügemodus auf, indem Sie auf "+ i +" drücken und der Datei die folgenden Zeilen hinzufügen.
/etc/yum.repos.d/elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdHier haben Sie den von Menschen lesbaren "+ name " des Repos, das " baseurl " des Datenverzeichnisses des Repos und den " gpgkey +" angegeben, der zur Überprüfung von Elastic-Paketen erforderlich ist.
Wenn Sie fertig sind, drücken Sie "+ ESC ", um den Einfügemodus zu verlassen, und dann ": wq " und " ENTER +", um die Datei zu speichern und zu beenden. Weitere Informationen zum Texteditor vi und seinem Nachfolger vim finden Sie unter https://www.digitalocean.com/community/tutorials/installing-and-using-the-vim-text-editor-on-a-cloud- Server # Dokumente verwalten [Installieren und Verwenden des Vim-Texteditors auf einem Cloud-Server] Lernprogramm.
Mit dem hinzugefügten Repo können Sie jetzt den elastischen Stapel installieren. Gemäß der official documentation sollten Sie Elasticsearch vor den anderen Komponenten installieren. Durch die Installation in dieser Reihenfolge wird sichergestellt, dass die Komponenten, von denen jedes Produkt abhängt, korrekt installiert sind.
Installieren Sie Elasticsearch mit dem folgenden Befehl:
sudo yum install elasticsearchÖffnen Sie nach Abschluss der Installation von Elasticsearch die Hauptkonfigurationsdatei "+ elasticsearch.yml +" in Ihrem Editor:
sudo vi /etc/elasticsearch/elasticsearch.ymlElasticsearch überwacht den Datenverkehr von überall auf dem Port "+ 9200 ". Sie möchten den externen Zugriff auf Ihre Elasticsearch-Instanz einschränken, um zu verhindern, dass Außenstehende Ihre Daten lesen oder Ihren Elasticsearch-Cluster über die REST-API herunterfahren. Suchen Sie die Zeile, die " network.host" angibt, entfernen Sie das Kommentarzeichen und ersetzen Sie den Wert durch "+ localhost".
/etc/elasticsearch/elasticsearch.yml
. . .
network.host:
. . .Speichern und schließen Sie "+ elasticsearch.yml ". Starten Sie dann den Dienst Elasticsearch mit ` systemctl +`:
sudo systemctl start elasticsearchFühren Sie als Nächstes den folgenden Befehl aus, damit Elasticsearch bei jedem Start des Servers gestartet wird:
sudo systemctl enable elasticsearchSie können testen, ob Ihr Elasticsearch-Dienst ausgeführt wird, indem Sie eine HTTP-Anfrage senden:
curl -X GET "localhost:9200"Sie erhalten eine Antwort mit einigen grundlegenden Informationen zu Ihrem lokalen Knoten, ähnlich der folgenden:
Output{
"name" : "8oSCBFJ",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "1Nf9ZymBQaOWKpMRBfisog",
"version" : {
"number" : "6.5.2",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "9434bed",
"build_date" : "2018-11-29T23:58:20.891072Z",
"build_snapshot" : false,
"lucene_version" : "7.5.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}Nachdem Elasticsearch nun ausgeführt wird, installieren wir Kibana, die nächste Komponente des Elastic Stacks.
Schritt 2 - Installieren und Konfigurieren des Kibana-Dashboards
Entsprechend der Installationsreihenfolge in der official documentation sollten Sie Kibana als nächste Komponente nach Elasticsearch installieren. Nach dem Einrichten von Kibana können wir über die Benutzeroberfläche die von Elasticsearch gespeicherten Daten durchsuchen und visualisieren.
Da Sie das Elastic-Repository bereits im vorherigen Schritt hinzugefügt haben, können Sie die restlichen Komponenten des Elastic-Stacks einfach mit + yum + installieren:
sudo yum install kibanaAktivieren und starten Sie dann den Kibana-Dienst:
sudo systemctl enable kibana
sudo systemctl start kibanaDa Kibana so konfiguriert ist, dass nur "+ localhost +" abgehört wird, müssen wir eine reverse proxy einrichten, um externen Zugriff zu ermöglichen es. Zu diesem Zweck verwenden wir Nginx, das bereits auf Ihrem Server installiert sein sollte.
Verwenden Sie zunächst den Befehl "+ openssl ", um einen administrativen Kibana-Benutzer zu erstellen, mit dem Sie auf die Kibana-Weboberfläche zugreifen. Als Beispiel nennen wir dieses Konto "+". Um jedoch eine größere Sicherheit zu gewährleisten, empfehlen wir Ihnen, einen nicht standardmäßigen Namen für Ihren Benutzer zu wählen, der schwer zu erraten ist.
Der folgende Befehl erstellt den administrativen Kibana-Benutzer und das Passwort und speichert sie in der Datei + htpasswd.users +. Sie konfigurieren Nginx so, dass Sie diesen Benutzernamen und das Kennwort benötigen, und lesen diese Datei vorübergehend:
echo ":`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.usersGeben Sie an der Eingabeaufforderung ein Kennwort ein und bestätigen Sie es. Denken Sie daran, oder notieren Sie sich dieses Login, da Sie es für den Zugriff auf die Kibana-Weboberfläche benötigen.
Als Nächstes erstellen wir eine Nginx-Server-Blockdatei. Als Beispiel bezeichnen wir diese Datei als "+ .conf +", obwohl es hilfreich sein kann, Ihren Namen aussagekräftiger zu gestalten. Wenn Sie beispielsweise einen FQDN und DNS-Einträge für diesen Server eingerichtet haben, können Sie diese Datei nach Ihrem FQDN benennen:
sudo vi /etc/nginx/conf.d/.confFügen Sie der Datei den folgenden Codeblock hinzu, und achten Sie darauf, "+" und " www. " So zu aktualisieren, dass sie mit dem vollqualifizierten Domänennamen oder der öffentlichen IP-Adresse Ihres Servers übereinstimmen. Mit diesem Code wird Nginx so konfiguriert, dass der HTTP-Verkehr Ihres Servers an die Kibana-Anwendung geleitet wird, die ` localhost: 5601 ` abhört. Außerdem wird Nginx so konfiguriert, dass es die Datei ` htpasswd.users +` liest und eine grundlegende Authentifizierung erfordert.
Beachten Sie, dass Sie diese Datei möglicherweise bereits erstellt haben, wenn Sie den Anweisungen unter prerequisite Nginx tutorial bis zum Ende gefolgt sind und füllte es mit etwas Inhalt. Löschen Sie in diesem Fall den gesamten vorhandenen Inhalt der Datei, bevor Sie Folgendes hinzufügen:
example.com.conf ’> / etc / nginx / conf.d / .conf
server {
listen 80;
server_name www.;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}Speichern und schließen Sie die Datei, wenn Sie fertig sind.
Überprüfen Sie anschließend die Konfiguration auf Syntaxfehler:
sudo nginx -tWenn in Ihrer Ausgabe Fehler gemeldet werden, überprüfen Sie erneut, ob der Inhalt, den Sie in Ihre Konfigurationsdatei eingefügt haben, korrekt hinzugefügt wurde. Sobald Sie sehen, dass die + Syntax in der Ausgabe in Ordnung ist, starten Sie den Nginx-Dienst neu:
sudo systemctl restart nginxStandardmäßig ist die SELinux-Sicherheitsrichtlinie so eingestellt, dass sie durchgesetzt wird. Führen Sie den folgenden Befehl aus, damit Nginx auf den Proxy-Dienst zugreifen kann:
sudo setsebool httpd_can_network_connect 1 -PWeitere Informationen zu SELinux finden Sie im Tutorial Eine Einführung in SELinux unter CentOS 7.
Auf Kibana kann jetzt über Ihren FQDN oder die öffentliche IP-Adresse Ihres Elastic Stack-Servers zugegriffen werden. Sie können die Statusseite des Kibana-Servers überprüfen, indem Sie zur folgenden Adresse navigieren und Ihre Anmeldeinformationen eingeben, wenn Sie dazu aufgefordert werden:
http:///statusDiese Statusseite zeigt Informationen zur Ressourcennutzung des Servers an und listet die installierten Plugins auf.
image: https: //i.imgur.com/QSiMhUD.png [| Kibana-Statusseite]
Nachdem das Kibana-Dashboard konfiguriert wurde, installieren wir die nächste Komponente: Logstash.
Schritt 3 - Logstash installieren und konfigurieren
Beats kann zwar Daten direkt an die Elasticsearch-Datenbank senden, wir empfehlen jedoch, Logstash zu verwenden, um die Daten zuerst zu verarbeiten. Auf diese Weise können Sie Daten aus verschiedenen Quellen sammeln, in ein gemeinsames Format umwandeln und in eine andere Datenbank exportieren.
Installieren Sie Logstash mit diesem Befehl:
sudo yum install logstashNach der Installation von Logstash können Sie mit der Konfiguration fortfahren. Die Konfigurationsdateien von Logstash sind im JSON-Format geschrieben und befinden sich im Verzeichnis "+ / etc / logstash / conf.d ". Bei der Konfiguration ist es hilfreich, sich Logstash als eine Pipeline vorzustellen, die Daten an einem Ende aufnimmt, auf die eine oder andere Weise verarbeitet und an ihr Ziel sendet (in diesem Fall ist das Ziel Elasticsearch). Eine Logstash-Pipeline enthält zwei erforderliche Elemente: " input " und " output " sowie ein optionales Element: " filter +". Die Eingabe-Plugins verbrauchen Daten von einer Quelle, die Filter-Plugins verarbeiten die Daten und die Ausgabe-Plugins schreiben die Daten in ein Ziel.
image: https://assets.digitalocean.com/articles/elastic_1804/logstash_pipeline_updated.png [Logstash-Pipeline]
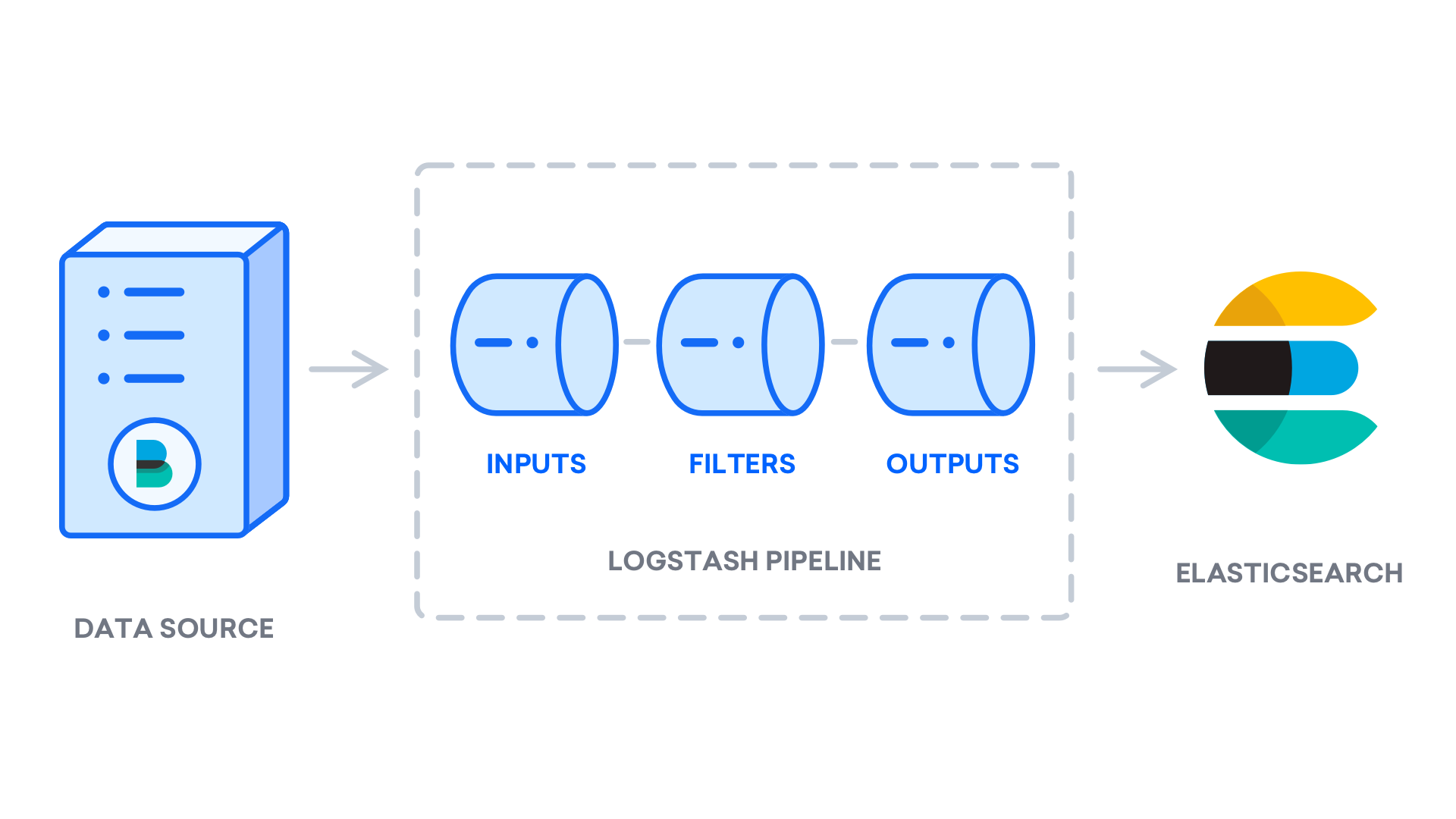{kind=link}
Erstellen Sie eine Konfigurationsdatei mit dem Namen "+ 02-beats-input.conf +", in der Sie Ihre Filebeat-Eingabe einrichten:
sudo vi /etc/logstash/conf.d/02-beats-input.confFügen Sie die folgende + input + Konfiguration ein. Dies gibt einen "+ beats " - Eingang an, der den TCP-Port " 5044 +" überwacht.
/etc/logstash/conf.d/02-beats-input.conf
input {
beats {
port => 5044
}
}Speichern und schließen Sie die Datei. Als nächstes erstellen Sie eine Konfigurationsdatei mit dem Namen "+ 10-syslog-filter.conf +", die einen Filter für Systemprotokolle, auch als "syslogs" bezeichnet, hinzufügt:
sudo vi /etc/logstash/conf.d/10-syslog-filter.confFügen Sie die folgende Syslog-Filterkonfiguration ein. Diese Beispielkonfiguration für Systemprotokolle stammt aus official Elastic documentation. Mit diesem Filter werden eingehende Systemprotokolle analysiert, um sie für die vordefinierten Kibana-Dashboards strukturiert und verwendbar zu machen:
/etc/logstash/conf.d/10-syslog-filter.conf
filter {
if [fileset][module] == "system" {
if [fileset][name] == "auth" {
grok {
match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] }
pattern_definitions => {
"GREEDYMULTILINE"=> "(.|\n)*"
}
remove_field => "message"
}
date {
match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
geoip {
source => "[system][auth][ssh][ip]"
target => "[system][auth][ssh][geoip]"
}
}
else if [fileset][name] == "syslog" {
grok {
match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] }
pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" }
remove_field => "message"
}
date {
match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
}Speichern und schließen Sie die Datei, wenn Sie fertig sind.
Zuletzt erstellen Sie eine Konfigurationsdatei mit dem Namen + 30-elasticsearch-output.conf +:
sudo vi /etc/logstash/conf.d/30-elasticsearch-output.confFügen Sie die folgende + output + Konfiguration ein. Diese Ausgabe konfiguriert Logstash so, dass die Beats-Daten in Elasticsearch, das unter + localhost: 9200 + ausgeführt wird, in einem Index gespeichert werden, der nach dem verwendeten Beat benannt ist. Der in diesem Tutorial verwendete Beat ist Filebeat:
/etc/logstash/conf.d/30-elasticsearch-output.conf
output {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}Speichern und schließen Sie die Datei.
Wenn Sie Filter für andere Anwendungen hinzufügen möchten, die die Filebeat-Eingabe verwenden, müssen Sie die Dateien so benennen, dass sie zwischen der Eingabe- und der Ausgabekonfiguration sortiert sind. Dies bedeutet, dass die Dateinamen mit einer zweistelligen Zahl zwischen + beginnen sollten 02 + `und + 30 + `.
Testen Sie Ihre Logstash-Konfiguration mit diesem Befehl:
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -tWenn keine Syntaxfehler vorliegen, zeigt Ihre Ausgabe nach einigen Sekunden "+ Konfiguration OK" an. Wenn dies in Ihrer Ausgabe nicht angezeigt wird, suchen Sie nach Fehlern in Ihrer Ausgabe und aktualisieren Sie Ihre Konfiguration, um sie zu korrigieren.
Wenn Ihr Konfigurationstest erfolgreich ist, starten Sie Logstash und aktivieren Sie es, damit die Konfigurationsänderungen wirksam werden:
sudo systemctl start logstash
sudo systemctl enable logstashNachdem Logstash ordnungsgemäß ausgeführt und vollständig konfiguriert wurde, installieren wir Filebeat.
Schritt 4 - Installieren und Konfigurieren von Filebeat
Der Elastic Stack verwendet mehrere Lightweight-Datenversender namens Beats, um Daten aus verschiedenen Quellen zu sammeln und an Logstash oder Elasticsearch zu übertragen. Hier sind die Beats, die derzeit bei Elastic erhältlich sind:
-
Filebeat: sammelt und versendet Protokolldateien.
-
Metricbeat: sammelt Metriken von Ihren Systemen und Diensten.
-
Packetbeat: sammelt und analysiert Netzwerkdaten.
-
Winlogbeat: sammelt Windows-Ereignisprotokolle.
-
Auditbeat: sammelt Linux-Audit-Framework-Daten und überwacht die Dateiintegrität.
-
Heartbeat: Überwacht Dienste auf ihre Verfügbarkeit mit aktiver Prüfung.
In diesem Tutorial verwenden wir Filebeat, um lokale Protokolle an unseren Elastic Stack weiterzuleiten.
Installiere Filebeat mit + yum +:
sudo yum install filebeatKonfigurieren Sie als Nächstes Filebeat für die Verbindung mit Logstash. Hier ändern wir die Beispielkonfigurationsdatei, die mit Filebeat geliefert wird.
Öffnen Sie die Filebeat-Konfigurationsdatei:
sudo vi /etc/filebeat/filebeat.ymlFilebeat unterstützt zahlreiche Ausgaben, in der Regel senden Sie Ereignisse jedoch nur direkt zur weiteren Verarbeitung an Elasticsearch oder Logstash. In diesem Lernprogramm verwenden wir Logstash, um die von Filebeat erfassten Daten weiter zu verarbeiten. Filebeat muss keine Daten direkt an Elasticsearch senden. Deaktivieren Sie diese Ausgabe. Suchen Sie dazu den Abschnitt "+ output.elasticsearch " und kommentieren Sie die folgenden Zeilen aus, indem Sie ihnen ein " # +" voranstellen:
/etc/filebeat/filebeat.yml
...
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]
...Konfigurieren Sie dann den Abschnitt + output.logstash +. Kommentieren Sie die Zeilen + output.logstash: + und + hosts: [" localhost: 5044 "] + aus, indem Sie das + # + entfernen. Dadurch wird Filebeat so konfiguriert, dass eine Verbindung zu Logstash auf Ihrem Elastic Stack-Server über den Port "+ 5044 +" hergestellt wird, für den wir zuvor eine Logstash-Eingabe angegeben haben:
/etc/filebeat/filebeat.yml
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]Speichern und schließen Sie die Datei.
Sie können die Funktionalität von Filebeat jetzt mit Filebeat modules erweitern. In diesem Lernprogramm verwenden Sie das Modul system, mit dem die von der Systemprotokollierung erstellten Protokolle erfasst und analysiert werden Service von gängigen Linux-Distributionen.
Aktivieren wir es:
sudo filebeat modules enable systemSie können eine Liste der aktivierten und deaktivierten Module anzeigen, indem Sie Folgendes ausführen:
sudo filebeat modules listSie sehen eine Liste ähnlich der folgenden:
OutputEnabled:
system
Disabled:
apache2
auditd
elasticsearch
haproxy
icinga
iis
kafka
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
suricata
traefikStandardmäßig ist Filebeat so konfiguriert, dass Standardpfade für das Syslog und die Autorisierungsprotokolle verwendet werden. In diesem Tutorial müssen Sie nichts an der Konfiguration ändern. Sie können die Parameter des Moduls in der Konfigurationsdatei + / etc / filebeat / modules.d / system.yml + sehen.
Laden Sie anschließend die Indexvorlage in Elasticsearch. Ein https://www.elastic.co/guide/en/elasticsearch/reference/current/basic_concepts.html#_index[_Elasticsearch index] ist eine Sammlung von Dokumenten mit ähnlichen Merkmalen. Indizes werden mit einem Namen gekennzeichnet, der verwendet wird, um auf den Index zu verweisen, wenn verschiedene Operationen darin ausgeführt werden. Die Indexvorlage wird automatisch angewendet, wenn ein neuer Index erstellt wird.
Verwenden Sie den folgenden Befehl, um die Vorlage zu laden:
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'Dies ergibt die folgende Ausgabe:
OutputLoaded index templateFilebeat wird mit Beispiel-Kibana-Dashboards geliefert, mit denen Sie Filebeat-Daten in Kibana visualisieren können. Bevor Sie die Dashboards verwenden können, müssen Sie das Indexmuster erstellen und die Dashboards in Kibana laden.
Beim Laden der Dashboards stellt Filebeat eine Verbindung zu Elasticsearch her, um die Versionsinformationen zu überprüfen. Um Dashboards zu laden, wenn Logstash aktiviert ist, müssen Sie die Logstash-Ausgabe manuell deaktivieren und die Elasticsearch-Ausgabe aktivieren:
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601Sie werden eine Ausgabe sehen, die so aussieht:
Output. . .
2018-12-05T21:23:33.806Z INFO elasticsearch/client.go:163 Elasticsearch url: http://localhost:9200
2018-12-05T21:23:33.811Z INFO elasticsearch/client.go:712 Connected to Elasticsearch version 6.5.2
2018-12-05T21:23:33.815Z INFO template/load.go:129 Template already exists and will not be overwritten.
Loaded index template
Loading dashboards (Kibana must be running and reachable)
2018-12-05T21:23:33.816Z INFO elasticsearch/client.go:163 Elasticsearch url: http://localhost:9200
2018-12-05T21:23:33.819Z INFO elasticsearch/client.go:712 Connected to Elasticsearch version 6.5.2
2018-12-05T21:23:33.819Z INFO kibana/client.go:118 Kibana url: http://localhost:5601
2018-12-05T21:24:03.981Z INFO instance/beat.go:717 Kibana dashboards successfully loaded.
Loaded dashboards
2018-12-05T21:24:03.982Z INFO elasticsearch/client.go:163 Elasticsearch url: http://localhost:9200
2018-12-05T21:24:03.984Z INFO elasticsearch/client.go:712 Connected to Elasticsearch version 6.5.2
2018-12-05T21:24:03.984Z INFO kibana/client.go:118 Kibana url: http://localhost:5601
2018-12-05T21:24:04.043Z WARN fileset/modules.go:388 X-Pack Machine Learning is not enabled
2018-12-05T21:24:04.080Z WARN fileset/modules.go:388 X-Pack Machine Learning is not enabled
Loaded machine learning job configurationsJetzt können Sie Filebeat starten und aktivieren:
sudo systemctl start filebeat
sudo systemctl enable filebeatWenn Sie Ihren Elastic Stack korrekt eingerichtet haben, beginnt Filebeat mit dem Versand Ihrer Syslog- und Autorisierungsprotokolle an Logstash, wodurch diese Daten in Elasticsearch geladen werden.
Um zu überprüfen, ob Elasticsearch diese Daten tatsächlich empfängt, fragen Sie den Filebeat-Index mit dem folgenden Befehl ab:
curl -X GET 'http://localhost:9200/filebeat-*/_search?pretty'Sie sehen eine Ausgabe, die ungefähr so aussieht:
Output{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3225,
"max_score" : 1.0,
"hits" : [
{
"_index" : "filebeat-6.5.2-2018.12.05",
"_type" : "doc",
"_id" : "vf5GgGcB_g3p-PRo_QOw",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2018-12-05T19:00:34.000Z",
"source" : "/var/log/secure",
"meta" : {
"cloud" : {
. . .Wenn Ihre Ausgabe 0 Treffer insgesamt anzeigt, lädt Elasticsearch keine Protokolle unter dem Index, nach dem Sie gesucht haben, und Sie müssen Ihr Setup auf Fehler überprüfen. Wenn Sie die erwartete Ausgabe erhalten haben, fahren Sie mit dem nächsten Schritt fort, in dem Sie einige Dashboards von Kibana kennenlernen.
Schritt 5 - Kibana Dashboards erkunden
Schauen wir uns Kibana an, das Webinterface, das wir zuvor installiert haben.
Wechseln Sie in einem Webbrowser zum FQDN oder zur öffentlichen IP-Adresse Ihres Elastic Stack-Servers. Nachdem Sie die in Schritt 2 definierten Anmeldeinformationen eingegeben haben, wird die Kibana-Homepage angezeigt:
Bild: https://assets.digitalocean.com/articles/elastic_CentOS7_120618/Kibana_Homepage_TN.png [Kibana Homepage]
{kind=link}
Klicken Sie in der linken Navigationsleiste auf den Link * Entdecken . Wählen Sie auf der Seite * Discover * das vordefinierte Indexmuster * filebeat - * aus, um die Filebeat-Daten anzuzeigen. Standardmäßig werden Ihnen alle Protokolldaten der letzten 15 Minuten angezeigt. Nachfolgend sehen Sie ein Histogramm mit Protokollereignissen und einigen Protokollmeldungen:
image: https://assets.digitalocean.com/articles/elastic_CentOS7_120618/Kibana_DiscoverPage_TN.png [Seite entdecken]
{kind=link}
Hier können Sie nach Protokollen suchen und diese durchsuchen sowie Ihr Dashboard anpassen. Zu diesem Zeitpunkt wird es jedoch noch nicht viel geben, da Sie nur Syslogs von Ihrem Elastic Stack-Server sammeln.
Navigieren Sie im linken Bereich zur Seite * Dashboard * und suchen Sie nach den Dashboards * Filebeat System *. Dort können Sie nach den Beispiel-Dashboards suchen, die mit dem + system + - Modul von Filebeat geliefert werden.
Beispielsweise können Sie detaillierte Statistiken basierend auf Ihren Syslog-Nachrichten anzeigen:
image: https://assets.digitalocean.com/articles/elastic_CentOS7_120618/Kibana_SyslogDashboard_TN.png [Syslog Dashboard]
{kind=link}
Sie können auch anzeigen, welche Benutzer den Befehl + sudo + verwendet haben und wann:
image: https: //assets.digitalocean.com/articles/elastic_CentOS7_120618/Kibana_Sudo_Page_TN.png [Sudo Dashboard]
Kibana verfügt über viele weitere Funktionen, wie z. B. Grafiken und Filter.
Fazit
In diesem Lernprogramm haben Sie den Elastic Stack zum Sammeln und Analysieren von Systemprotokollen installiert und konfiguriert. Denken Sie daran, dass Sie über Beats nahezu jede Art von Protokoll- oder indizierten Daten an Logstash senden können. Die Daten werden jedoch noch nützlicher, wenn sie mit einem Logstash analysiert und strukturiert werden filtern, da dies die Daten in ein konsistentes Format umwandelt, das von Elasticsearch einfach gelesen werden kann.