Einführung
MySQL Cluster ist eine Softwaretechnologie, die eine hohe Verfügbarkeit und einen hohen Durchsatz bietet. Wenn Sie bereits mit anderen Clustertechnologien vertraut sind, finden Sie ähnliche MySQL-Cluster. Kurz gesagt, es gibt einen oder mehrere Verwaltungsknoten, die die Datenknoten steuern (in denen Daten gespeichert sind). Nach Rücksprache mit dem Verwaltungsknoten stellen Clients (MySQL-Clients, Server oder native APIs) eine direkte Verbindung zu den Datenknoten her.
Sie fragen sich vielleicht, wie die MySQL-Replikation mit dem MySQL-Cluster zusammenhängt. Beim Cluster gibt es keine typische Replikation von Daten, sondern eine Synchronisation der Datenknoten. Zu diesem Zweck muss eine spezielle Daten-Engine verwendet werden - NDBCluster (NDB). Stellen Sie sich den Cluster als eine einzelne logische MySQL-Umgebung mit redundanten Komponenten vor. Somit kann ein MySQL-Cluster an der Replikation mit anderen MySQL-Clustern teilnehmen.
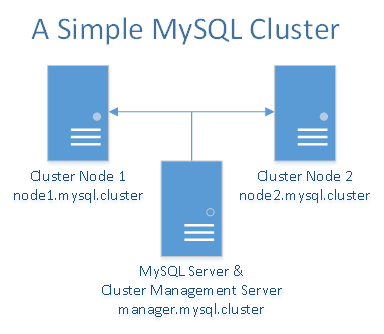
MySQL Cluster funktioniert am besten in einer Umgebung ohne gemeinsame Nutzung. Im Idealfall sollten sich keine zwei Komponenten die gleiche Hardware teilen. Der Einfachheit halber und zu Demonstrationszwecken beschränken wir uns auf die Verwendung von nur drei Tröpfchen. Es gibt zwei Tropfen, die als Datenknoten fungieren und Daten untereinander synchronisieren. Das dritte Droplet wird für den Cluster-Manager und gleichzeitig für den MySQL-Server / -Client verwendet. Wenn Sie mehr Droplets haben, können Sie mehr Datenknoten hinzufügen, den Cluster-Manager vom MySQL-Server / -Client trennen und sogar mehr Droplets als Cluster-Manager und MySQL-Server / -Clients hinzufügen.
Voraussetzungen
Sie benötigen insgesamt drei Droplets - ein Droplet für den MySQL-Cluster-Manager und den MySQL-Server / -Client und zwei Droplets für die redundanten MySQL-Datenknoten.
Erstellen Sie insame DigitalOcean data center die folgenden Tröpfchen mitprivate networking enabled:
-
Drei Ubuntu 16.04-Droplets mit mindestens 1 GB RAM undprivate networking aktiviert
-
Nicht-Root-Benutzer mit Sudo-Berechtigungen für jedes Droplet (Initial Server Setup with Ubuntu 16.04 erklärt, wie dies eingerichtet wird.)
MySQL-Cluster speichert viele Informationen im RAM. Jedes Droplet sollte mindestens 1 GB RAM haben.
Stellen Sie, wie inprivate networking tutorial erwähnt, sicher, dass Sie benutzerdefinierte Datensätze für die 3 Tröpfchen einrichten. Der Einfachheit und Bequemlichkeit halber verwenden wir die folgenden benutzerdefinierten Datensätze für jedes Droplet in der/etc/hosts-Datei:
10.XXX.XX.X node1.mysql.cluster
10.YYY.YY.Y node2.mysql.cluster
10.ZZZ.ZZ.Z manager.mysql.cluster
Bitte ersetzen Sie die hervorgehobenen IPs entsprechend durch die privaten IPs Ihrer Droplets.
Sofern nicht anders angegeben, sollten alle Befehle, für die in diesem Lernprogramm Root-Berechtigungen erforderlich sind, als Nicht-Root-Benutzer mit Sudo-Berechtigungen ausgeführt werden.
[[Schritt 1 - Herunterladen und Installieren des MySQL-Clusters]] == Schritt 1 - Herunterladen und Installieren des MySQL-Clusters
Zum Zeitpunkt der Erstellung dieses Tutorials ist die neueste GPL-Version des MySQL-Clusters 7.4.11. Das Produkt basiert auf MySQL 5.6 und beinhaltet:
-
Cluster-Manager-Software
-
Datenknoten-Manager-Software
-
MySQL 5.6 Server- und Client-Binärdateien
Sie können die kostenlose, allgemein verfügbare (GA) MySQL-Cluster-Version vonofficial MySQL cluster download pageherunterladen. Wählen Sie auf dieser Seite das Debian Linux-Plattformpaket, das auch für Ubuntu geeignet ist. Stellen Sie außerdem sicher, dass Sie je nach Architektur Ihrer Droplets die 32-Bit- oder die 64-Bit-Version auswählen. Laden Sie das Installationspaket auf jedes Ihrer Droplets hoch.
Die Installationsanweisungen sind für alle Droplets gleich. Führen Sie diese Schritte für alle 3 Droplets aus.
Bevor Sie mit der Installation beginnen, muss das Paketlibaio1installiert werden, da es sich um eine Abhängigkeit handelt:
sudo apt-get install libaio1Danach installieren Sie das MySQL-Cluster-Paket:
sudo dpkg -i mysql-cluster-gpl-7.4.11-debian7-x86_64.debJetzt finden Sie die MySQL-Cluster-Installation im Verzeichnis/opt/mysql/server-5.6/. Wir werden insbesondere mit dem bin-Verzeichnis (/opt/mysql/server-5.6/bin/) arbeiten, in dem sich alle Binärdateien befinden.
Die gleichen Installationsschritte sollten für alle drei Droplets durchgeführt werden, unabhängig davon, dass jedes über einen anderen Funktionsmanager oder Datenknoten verfügt.
Als Nächstes konfigurieren wir den MySQL-Cluster-Manager für jedes Droplet.
[[Schritt-2 - Konfigurieren und Starten des Cluster-Managers]] == Schritt 2 - Konfigurieren und Starten des Cluster-Managers
In diesem Schritt konfigurieren wir den MySQL-Cluster-Manager (manager.mysql.cluster). Die richtige Konfiguration stellt die korrekte Synchronisation und Lastverteilung zwischen den Datenknoten sicher. Alle Befehle sollten auf Dropletmanager.mysql.cluster ausgeführt werden.
Der Cluster-Manager ist die erste Komponente, die in einem Cluster gestartet werden muss. Es benötigt eine Konfigurationsdatei, die als Argument an die Binärdatei übergeben wird. Der Einfachheit halber verwenden wir die Datei/var/lib/mysql-cluster/config.ini für die Konfiguration.
Erstellen Sie im Dropletmanager.mysql.cluster zuerst das Verzeichnis, in dem sich diese Datei befindet (/var/lib/mysql-cluster):
sudo mkdir /var/lib/mysql-clusterDann erstelle eine Datei und bearbeite sie mit nano:
sudo nano /var/lib/mysql-cluster/config.iniDiese Datei sollte den folgenden Code enthalten:
/var/lib/mysql-cluster/config.ini
[ndb_mgmd]
# Management process options:
hostname=manager.mysql.cluster # Hostname of the manager
datadir=/var/lib/mysql-cluster # Directory for the log files
[ndbd]
hostname=node1.mysql.cluster # Hostname of the first data node
datadir=/usr/local/mysql/data # Remote directory for the data files
[ndbd]
hostname=node2.mysql.cluster # Hostname of the second data node
datadir=/usr/local/mysql/data # Remote directory for the data files
[mysqld]
# SQL node options:
hostname=manager.mysql.cluster # In our case the MySQL server/client is on the same Droplet as the cluster managerFür jede der oben genannten Komponenten haben wir einenhostname-Parameter definiert. Dies ist eine wichtige Sicherheitsmaßnahme, da nur der angegebene Hostname eine Verbindung zum Manager herstellen und gemäß der festgelegten Rolle am Cluster teilnehmen kann.
Darüber hinaus geben die Parameterhostnamean, auf welcher Schnittstelle der Dienst ausgeführt wird. Dies ist wichtig und wichtig für die Sicherheit, da in unserem Fall die oben genannten Hostnamen auf private IPs verweisen, die wir in den/etc/hosts-Dateien angegeben haben. Sie können daher nicht von außerhalb des privaten Netzwerks auf die oben genannten Dienste zugreifen.
In der obigen Datei können Sie redundantere Komponenten wie Datenknoten (ndbd) oder MySQL-Server (mysqld) hinzufügen, indem Sie einfach zusätzliche Instanzen auf dieselbe Weise definieren.
Jetzt können Sie den Manager zum ersten Mal starten, indem Sie die Binärdateindb_mgmdausführen und die Konfigurationsdatei mit dem Argument-fwie folgt angeben:
sudo /opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.iniSie sollten eine Meldung über den erfolgreichen Start sehen, ähnlich der folgenden:
Output of ndb_mgmdMySQL Cluster Management Server mysql-5.6.29 ndb-7.4.11Sie möchten wahrscheinlich, dass der Verwaltungsdienst automatisch mit dem Server gestartet wird. In der GA-Cluster-Version ist kein geeignetes Startskript enthalten, es sind jedoch einige online verfügbar. Zu Beginn können Sie einfach den Befehl start zur Datei/etc/rc.localhinzufügen, und der Dienst wird beim Booten automatisch gestartet. Zunächst müssen Sie jedoch sicherstellen, dass/etc/rc.local während des Serverstarts ausgeführt wird. In Ubuntu 16.04 muss dazu ein zusätzlicher Befehl ausgeführt werden:
sudo systemctl enable rc-local.serviceÖffnen Sie dann die Datei/etc/rc.local zur Bearbeitung:
sudo nano /etc/rc.localFügen Sie dort den Startbefehl vor der Zeileexitwie folgt hinzu:
/etc/rc.local
...
/opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.ini
exit 0Speichern und schließen Sie die Datei.
Der Cluster-Manager muss nicht ständig ausgeführt werden. Es kann ohne Ausfallzeit für den Cluster gestartet, gestoppt und neu gestartet werden. Es wird nur beim ersten Start der Clusterknoten und des MySQL-Servers / -Clients benötigt.
[[Schritt 3 - Konfigurieren und Starten der Datenknoten]] == Schritt 3 - Konfigurieren und Starten der Datenknoten
Als Nächstes konfigurieren wir die Datenknoten (node1.mysql.cluster undnode2.mysql.cluster) so, dass sie die Datendateien speichern und die NDB-Engine ordnungsgemäß unterstützen. Alle Befehle sollten auf beiden Knoten ausgeführt werden. Sie können zuerst mitnode1.mysql.cluster beginnen und dann genau dieselben Schritte mitnode2.mysql.cluster wiederholen.
Die Datenknoten lesen die Konfiguration aus der Standard-MySQL-Konfigurationsdatei/etc/my.cnf und insbesondere dem Teil nach der Zeile[mysql_cluster]. Erstelle diese Datei mit nano und bearbeite sie:
sudo nano /etc/my.cnfGeben Sie den Hostnamen des Managers wie folgt an:
/etc/my.cnf
[mysql_cluster]
ndb-connectstring=manager.mysql.clusterSpeichern und schließen Sie die Datei.
Die Angabe des Speicherorts des Managers ist die einzige Konfiguration, die zum Starten der Node Engine erforderlich ist. Der Rest der Konfiguration wird direkt vom Manager übernommen. In unserem Beispiel stellt der Datenknoten fest, dass sein Datenverzeichnis gemäß der Konfiguration des Managers/usr/local/mysql/data beträgt. Dieses Verzeichnis muss auf dem Knoten angelegt werden. Sie können es mit dem Befehl tun:
sudo mkdir -p /usr/local/mysql/dataDanach können Sie den Datenknoten zum ersten Mal mit dem Befehl starten:
sudo /opt/mysql/server-5.6/bin/ndbdNach einem erfolgreichen Start sollten Sie eine ähnliche Ausgabe sehen:
Output of ndbd2016-05-11 16:12:23 [ndbd] INFO -- Angel connected to 'manager.mysql.cluster:1186'
2016-05-11 16:12:23 [ndbd] INFO -- Angel allocated nodeid: 2Der ndbd-Dienst sollte automatisch mit dem Server gestartet werden. Die GA-Cluster-Version enthält auch hierfür kein geeignetes Startskript. Fügen wir wie beim Cluster-Manager den Startbefehl zur Datei/etc/rc.localhinzu. Auch hier müssen Sie sicherstellen, dass/etc/rc.local während des Serverstarts mit dem folgenden Befehl ausgeführt wird:
sudo systemctl enable rc-local.serviceÖffnen Sie dann die Datei/etc/rc.local zur Bearbeitung:
sudo nano /etc/rc.localFügen Sie den Startbefehl vor der Zeileexitwie folgt hinzu:
/etc/rc.local
...
/opt/mysql/server-5.6/bin/ndbd
exit 0Speichern und schließen Sie die Datei.
Wenn Sie mit dem ersten Knoten fertig sind, wiederholen Sie genau die gleichen Schritte auf dem anderen Knoten, in unserem Beispielnode2.mysql.cluster.
[[Schritt 4 - Konfigurieren und Starten des MySQL-Servers und -Clients]] == Schritt 4 - Konfigurieren und Starten des MySQL-Servers und -Clients
Ein Standard-MySQL-Server, wie er im Standard-Apt-Repository von Ubuntu verfügbar ist, unterstützt die MySQL-Cluster-Engine NDB nicht. Aus diesem Grund benötigen Sie eine benutzerdefinierte MySQL-Server-Installation. Das Cluster-Paket, das wir bereits auf den drei Droplets installiert haben, enthält einen MySQL-Server und einen Client. Wie bereits erwähnt, verwenden wir den MySQL-Server und -Client auf dem Verwaltungsknoten (manager.mysql.cluster).
Die Konfiguration wird erneut in der Standarddatei/etc/my.cnfgespeichert. Öffnen Sie untermanager.mysql.cluster die Konfigurationsdatei:
sudo nano /etc/my.cnfFügen Sie dann Folgendes hinzu:
/etc/my.cnf
[mysqld]
ndbcluster # run NDB storage engine
...Speichern und schließen Sie die Datei.
Gemäß den Best Practices sollte der MySQL-Server unter seinem eigenen Benutzer (mysql) ausgeführt werden, der zu seiner eigenen Gruppe gehört (wiedermysql). Erstellen wir also zuerst die Gruppe:
sudo groupadd mysqlErstellen Sie dann den Benutzer vonmysql, der zu dieser Gruppe gehört, und stellen Sie sicher, dass er keine Shell verwenden kann, indem Sie seinen Shell-Pfad wie folgt auf/bin/false setzen:
sudo useradd -r -g mysql -s /bin/false mysqlDie letzte Voraussetzung für die benutzerdefinierte Installation von MySQL Server ist die Erstellung der Standarddatenbank. Sie können es mit dem Befehl tun:
sudo /opt/mysql/server-5.6/scripts/mysql_install_db --user=mysqlZum Starten des MySQL-Servers verwenden wir das Startskript von/opt/mysql/server-5.6/support-files/mysql.server. Kopieren Sie es unter dem Namenmysqldwie folgt in das Standardverzeichnis für Init-Skripte:
sudo cp /opt/mysql/server-5.6/support-files/mysql.server /etc/init.d/mysqldAktivieren Sie das Startskript und fügen Sie es mit dem folgenden Befehl zu den Standard-Runlevels hinzu:
sudo systemctl enable mysqld.serviceJetzt können wir den MySQL-Server zum ersten Mal manuell mit dem Befehl starten:
sudo systemctl start mysqldAls MySQL-Client verwenden wir wieder die benutzerdefinierte Binärdatei, die mit der Cluster-Installation geliefert wird. Es hat den folgenden Pfad:/opt/mysql/server-5.6/bin/mysql. Erstellen Sie der Einfachheit halber einen symbolischen Link dazu im Standardpfad von/usr/bin:
sudo ln -s /opt/mysql/server-5.6/bin/mysql /usr/bin/Jetzt können Sie den Client über die Befehlszeile starten, indem Sie einfachmysql wie folgt eingeben:
mysqlSie sollten eine Ausgabe ähnlich der folgenden sehen:
Output of ndb_mgmdWelcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.6.29-ndb-7.4.11-cluster-gpl MySQL Cluster Community Server (GPL)Um die MySQL-Eingabeaufforderung zu beenden, geben Sie einfachquit ein oder drücken Sie gleichzeitigCTRL-D.
Das Obige ist die erste Überprüfung, die zeigt, dass der MySQL-Cluster, der Server und der Client funktionieren. Als Nächstes werden wir detailliertere Tests durchführen, um sicherzustellen, dass der Cluster ordnungsgemäß funktioniert.
Testen des Clusters
Zu diesem Zeitpunkt sollte unser einfacher MySQL-Cluster mit einem Client, einem Server, einem Manager und zwei Datenknoten vollständig sein. Öffnen Sie im Cluster-Manager-Droplet (manager.mysql.cluster) die Verwaltungskonsole mit dem folgenden Befehl:
sudo /opt/mysql/server-5.6/bin/ndb_mgmJetzt sollte die Eingabeaufforderung zur Cluster-Verwaltungskonsole wechseln. Es sieht aus wie das:
Inside the ndb_mgm console-- NDB Cluster -- Management Client --
ndb_mgm>Sobald Sie sich in der Konsole befinden, führen Sie den BefehlSHOWwie folgt aus:
SHOWSie sollten eine Ausgabe ähnlich der folgenden sehen:
Output of ndb_mgmConnected to Management Server at: manager.mysql.cluster:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @10.135.27.42 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0, *)
id=3 @10.135.27.43 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)
[mysqld(API)] 1 node(s)
id=4 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)Das Obige zeigt, dass es zwei Datenknoten mit den IDs 2 und 3 gibt. Sie sind aktiv und verbunden. Es gibt auch einen Verwaltungsknoten mit der ID 1 und einen MySQL-Server mit der ID 4. Weitere Informationen zu jeder ID finden Sie, indem Sie ihre Nummer mit dem folgenden BefehlSTATUSeingeben:
2 STATUSDer obige Befehl würde Ihnen den Status von Knoten 2 zusammen mit seinen MySQL- und NDB-Versionen anzeigen:
Output of ndb_mgmNode 2: started (mysql-5.6.29 ndb-7.4.11)Um die Verwaltungskonsole zu verlassen, geben Siequit ein.
Die Verwaltungskonsole ist sehr leistungsfähig und bietet Ihnen viele weitere Optionen für die Verwaltung des Clusters und seiner Daten, einschließlich der Erstellung eines Online-Backups. Weitere Informationen finden Sie unterofficial documentation.
Lassen Sie uns jetzt einen Test mit dem MySQL-Client durchführen. Starten Sie den Client aus demselben Droplet mit dem Befehlmysql für den MySQL-Root-Benutzer. Bitte denken Sie daran, dass wir zuvor einen Symlink dazu erstellt haben.
mysql -u root\ Ihre Konsole wechselt zur MySQL-Client-Konsole. Führen Sie im MySQL-Client den folgenden Befehl aus:
SHOW ENGINE NDB STATUS \GNun sollten Sie alle Informationen zur NDB-Cluster-Engine sehen, beginnend mit den Verbindungsdetails:
Output of mysql
*************************** 1. row ***************************
Type: ndbcluster
Name: connection
Status: cluster_node_id=4, connected_host=manager.mysql.cluster, connected_port=1186, number_of_data_nodes=2, number_of_ready_data_nodes=2, connect_count=0
...Die wichtigste Information von oben ist die Anzahl der bereiten Knoten - 2. Durch diese Redundanz kann Ihr MySQL-Cluster auch dann weiterarbeiten, wenn einer der Datenknoten ausfällt. Gleichzeitig werden Ihre SQL-Abfragen auf die beiden Knoten verteilt.
Sie können versuchen, einen der Datenknoten herunterzufahren, um die Clusterstabilität zu testen. Am einfachsten ist es, das gesamte Droplet neu zu starten, um den Wiederherstellungsprozess vollständig zu testen. Sie werden sehen, wie sich der Wert vonnumber_of_ready_data_nodes in1 und wieder in2 ändert, wenn der Knoten neu gestartet wird.
Arbeiten mit der NDB Engine
Um zu sehen, wie der Cluster wirklich funktioniert, erstellen wir eine neue Tabelle mit der NDB-Engine und fügen einige Daten ein. Bitte beachten Sie, dass die Engine NDB sein muss, um die Cluster-Funktionalität nutzen zu können. Wenn Sie InnoDB (Standard) oder eine andere Engine als NDB verwenden, wird der Cluster nicht verwendet.
Erstellen wir zunächst eine Datenbank mit dem Namencluster mit dem folgenden Befehl:
CREATE DATABASE cluster;Wechseln Sie als Nächstes zur neuen Datenbank:
USE cluster;Erstellen Sie nun eine einfache Tabelle mit dem Namencluster_test wie folgt:
CREATE TABLE cluster_test (name VARCHAR(20), value VARCHAR(20)) ENGINE=ndbcluster;Wir haben oben explizit die Enginendbcluster angegeben, um den Cluster zu nutzen. Als Nächstes können wir mit einer Abfrage wie der folgenden beginnen, Daten einzufügen:
INSERT INTO cluster_test (name,value) VALUES('some_name','some_value');Führen Sie eine Auswahlabfrage wie die folgende aus, um zu überprüfen, ob die Daten eingefügt wurden:
SELECT * FROM cluster_test;Wenn Sie Daten wie diese einfügen und auswählen, verteilen Sie Ihre Abfragen auf alle verfügbaren Datenknoten, in unserem Beispiel auf zwei. Mit dieser Skalierung profitieren Sie sowohl von der Stabilität als auch von der Leistung.
Fazit
Wie wir in diesem Artikel gesehen haben, kann das Einrichten eines MySQL-Clusters einfach und unkompliziert sein. Natürlich gibt es viele erweiterte Optionen und Funktionen, die es sich zu beherrschen lohnen, bevor Sie den Cluster in Ihre Produktionsumgebung integrieren. Stellen Sie wie immer sicher, dass Sie über einen angemessenen Testprozess verfügen, da einige Probleme später möglicherweise nur sehr schwer zu lösen sind. Weitere Informationen und weitere Informationen finden Sie in der offiziellen Dokumentation zuMySQL cluster.