Der Autor hatGirls Who Code ausgewählt, um eine Spende im Rahmen desWrite for DOnations-Programms zu erhalten.
Einführung
Reinforcement learning ist ein Teilfeld der Steuerungstheorie, das Steuerungssysteme betrifft, die sich im Laufe der Zeit ändern, und im Großen und Ganzen Anwendungen wie selbstfahrende Autos, Robotik und Bots für Spiele umfasst. In diesem Handbuch werden Sie mithilfe von Reinforcement Learning einen Bot für Atari-Videospiele erstellen. Dieser Bot erhält keinen Zugriff auf interne Informationen zum Spiel. Stattdessen erhält es nur Zugriff auf die gerenderte Anzeige des Spiels und die Belohnung für diese Anzeige. Dies bedeutet, dass es nur sehen kann, was ein menschlicher Spieler sehen würde.
Beim maschinellen Lernen wird ein Bot formal alsagent bezeichnet. In diesem Tutorial ist ein Agent ein „Spieler“ im System, der gemäß einer Entscheidungsfunktion handelt, die alspolicy bezeichnet wird. Das primäre Ziel ist die Entwicklung starker Agenten, indem sie mit starken Richtlinien ausgestattet werden. Mit anderen Worten, unser Ziel ist es, intelligente Bots zu entwickeln, indem wir sie mit starken Entscheidungsfähigkeiten ausstatten.
Sie beginnen dieses Tutorial mit der Schulung eines grundlegenden Agenten für das Erlernen der Verstärkung, der beim Spielen von Space Invaders, dem klassischen Atari-Arcade-Spiel, zufällige Aktionen ausführt und als Vergleichsbasis dient. Anschließend werden Sie verschiedene andere Techniken untersuchen - einschließlichQ-learning,deep Q-learning undleast squares -, während Sie Agenten bauen, die Space Invaders und Frozen Lake spielen, eine einfache Spielumgebung, die inGymenthalten ist ) s, ein vonOpenAI veröffentlichtes Toolkit zum Lernen von Verstärkungen. Wenn Sie diesem Tutorial folgen, erhalten Sie einen Einblick in die grundlegenden Konzepte, die die Wahl der Modellkomplexität beim maschinellen Lernen bestimmen.
Voraussetzungen
Um dieses Tutorial abzuschließen, benötigen Sie:
-
Ein Server mit Ubuntu 18.04 und mindestens 1 GB RAM. Auf diesem Server sollte ein Nicht-Root-Benutzer mit konfigurierten
sudo-Berechtigungen sowie eine mit UFW eingerichtete Firewall vorhanden sein. Sie können dies einrichten, indem Sie diesenInitial Server Setup Guide for Ubuntu 18.04 folgen. -
Eine virtuelle Python 3-Umgebung, die Sie erreichen können, indem Sie unser Handbuch „https://www.digitalocean.com/community/tutorials/how-to-install-python-3-and-set-up-a-programming-environment-“ lesen. on-an-ubuntu-18-04-server [So installieren Sie Python 3 und richten eine Programmierumgebung auf einem Ubuntu 18.04-Server ein]. “
Wenn Sie einen lokalen Computer verwenden, können Sie alternativ Python 3 installieren und eine lokale Programmierumgebung einrichten, indem Sie das entsprechende Lernprogramm für Ihr Betriebssystem über unserePython Installation and Setup Series lesen.
[[Schritt-1 - Erstellen des Projekts und Installieren von Abhängigkeiten] == Schritt 1 - Erstellen des Projekts und Installieren von Abhängigkeiten
Um die Entwicklungsumgebung für Ihre Bots einzurichten, müssen Sie das Spiel selbst und die für die Berechnung erforderlichen Bibliotheken herunterladen.
Erstellen Sie zunächst einen Arbeitsbereich für dieses Projekt mit dem NamenAtariBot:
mkdir ~/AtariBotNavigieren Sie zum neuen VerzeichnisAtariBot:
cd ~/AtariBotErstellen Sie dann eine neue virtuelle Umgebung für das Projekt. Sie können diese virtuelle Umgebung beliebig benennen. hier nennen wir esataribot:
python3 -m venv ataribotAktivieren Sie Ihre Umgebung:
source ataribot/bin/activateUnter Ubuntu müssen ab Version 16.04 für OpenCV noch einige Pakete installiert werden, um zu funktionieren. Dazu gehören CMake - eine Anwendung, die Softwareerstellungsprozesse verwaltet - sowie ein Sitzungsmanager, verschiedene Erweiterungen und die Erstellung digitaler Bilder. Führen Sie den folgenden Befehl aus, um diese Pakete zu installieren:
sudo apt-get install -y cmake libsm6 libxext6 libxrender-dev libz-dev[.Hinweis]##
NOTE: Wenn Sie diese Anleitung auf einem lokalen Computer unter MacOS befolgen, müssen Sie nur CMake installieren. Installieren Sie es mit Homebrew (das Sie installiert haben, wenn Sieprerequisite MacOS tutorial befolgt haben), indem Sie Folgendes eingeben:
brew install cmakeVerwenden Sie als Nächstespip, um das Paketwheel zu installieren, die Referenzimplementierung des Radverpackungsstandards. Dieses Paket ist eine Python-Bibliothek und dient als Erweiterung zum Erstellen von Rädern. Es enthält ein Befehlszeilentool zum Arbeiten mit.whl-Dateien:
python -m pip install wheelZusätzlich zuwheel müssen Sie die folgenden Pakete installieren:
-
Gym, eine Python-Bibliothek, die verschiedene Spiele für Forschungszwecke sowie alle Abhängigkeiten für die Atari-Spiele zur Verfügung stellt. Gym wurde vonOpenAI entwickelt und bietet öffentliche Benchmarks für jedes Spiel, damit die Leistung für verschiedene Agenten und Algorithmen einheitlich bewertet werden kann.
-
Tensorflow, eine Deep-Learning-Bibliothek. Mit dieser Bibliothek können wir Berechnungen effizienter ausführen. Dazu werden insbesondere mathematische Funktionen unter Verwendung der Tensorflow-Abstraktionen erstellt, die ausschließlich auf Ihrer GPU ausgeführt werden.
-
OpenCV, die zuvor erwähnte Computer-Vision-Bibliothek.
-
SciPy, eine wissenschaftliche Computerbibliothek, die effiziente Optimierungsalgorithmen bietet.
-
NumPy, eine lineare Algebra-Bibliothek.
Installieren Sie jedes dieser Pakete mit dem folgenden Befehl. Beachten Sie, dass dieser Befehl angibt, welche Version jedes Pakets installiert werden soll:
python -m pip install gym==0.9.5 tensorflow==1.5.0 tensorpack==0.8.0 numpy==1.14.0 scipy==1.1.0 opencv-python==3.4.1.15Verwenden Sie anschließend erneutpip, um die Atari-Umgebungen von Gym zu installieren, die eine Vielzahl von Atari-Videospielen enthalten, einschließlich Space Invaders:
python -m pip install gym[atari]Wenn Ihre Installation des Paketsgym[atari]erfolgreich war, endet Ihre Ausgabe wie folgt:
OutputInstalling collected packages: atari-py, Pillow, PyOpenGL
Successfully installed Pillow-5.4.1 PyOpenGL-3.1.0 atari-py-0.1.7Wenn diese Abhängigkeiten installiert sind, können Sie einen Agenten erstellen, der nach dem Zufallsprinzip abgespielt wird und als Vergleichsgrundlage dient.
[[Schritt 2 - Erstellen eines Baseline-Zufallsagenten mit Fitnessstudio]] == Schritt 2 - Erstellen eines Baseline-Zufallsagenten mit Fitnessstudio
Nachdem sich die erforderliche Software auf Ihrem Server befindet, richten Sie einen Agenten ein, der eine vereinfachte Version des klassischen Atari-Spiels Space Invaders spielt. Für jedes Experiment ist es erforderlich, eine Baseline zu erhalten, anhand derer Sie die Leistung Ihres Modells nachvollziehen können. Da dieser Agent in jedem Frame zufällige Aktionen ausführt, wird er als zufälliger Basisagent bezeichnet. In diesem Fall werden Sie mit diesem Basisagenten vergleichen, um zu verstehen, wie gut Ihre Agenten in späteren Schritten arbeiten.
Mit Gym pflegen Sie Ihre eigenengame loop. Dies bedeutet, dass Sie jeden Schritt der Spielausführung ausführen: Bei jedem Schritt geben Sie dengym eine neue Aktion und fragengym nach dengame state. In diesem Tutorial ist der Spielstatus das Erscheinungsbild des Spiels zu einem bestimmten Zeitpunkt und genau das, was Sie sehen würden, wenn Sie das Spiel spielen würden.
Erstellen Sie mit Ihrem bevorzugten Texteditor eine Python-Datei mit dem Namenbot_2_random.py. Hier verwenden wirnano:
nano bot_2_random.py[.note] #Note: In diesem Handbuch werden die Namen der Bots an der Schrittnummer ausgerichtet, in der sie angezeigt werden, und nicht an der Reihenfolge, in der sie angezeigt werden. Daher heißt dieser Botbot_2_random.py und nichtbot_1_random.py.
#
Starten Sie dieses Skript, indem Sie die folgenden hervorgehobenen Zeilen hinzufügen. Diese Zeilen enthalten einen Kommentarblock, der erklärt, was dieses Skript tun wird, und zweiimport-Anweisungen, die die Pakete importieren, die dieses Skript letztendlich benötigt, um zu funktionieren:
/AtariBot/bot_2_random.py
"""
Bot 2 -- Make a random, baseline agent for the SpaceInvaders game.
"""
import gym
import randomFügen Sie einemain-Funktion hinzu. Erstellen Sie in dieser Funktion die Spielumgebung -SpaceInvaders-v0 - und initialisieren Sie das Spiel mitenv.reset:
/AtariBot/bot_2_random.py
. . .
import gym
import random
def main():
env = gym.make('SpaceInvaders-v0')
env.reset()Fügen Sie als Nächstes eineenv.step-Funktion hinzu. Diese Funktion kann die folgenden Arten von Werten zurückgeben:
-
state: Der neue Status des Spiels nach Anwendung der bereitgestellten Aktion. -
reward: Die Erhöhung der Punktzahl, die dem Staat entsteht. Dies kann beispielsweise der Fall sein, wenn eine Kugel einen Alien zerstört hat und die Punktzahl um 50 Punkte steigt. Dannreward = 50. Beim Spielen eines auf Punkten basierenden Spiels besteht das Ziel des Spielers darin, die Punktzahl zu maximieren. Dies ist gleichbedeutend mit der Maximierung der Gesamtbelohnung. -
done: Gibt an, ob die Episode beendet wurde oder nicht. Dies tritt normalerweise auf, wenn ein Spieler alle Leben verloren hat. -
info: Nebeninformationen, die Sie vorerst beiseite legen.
Sie werdenreward verwenden, um Ihre Gesamtbelohnung zu zählen. Sie werden auchdone verwenden, um zu bestimmen, wann der Spieler stirbt. In diesem Fall gibtdoneTrue zurück.
Fügen Sie die folgende Spielschleife hinzu, die das Spiel anweist, die Schleife zu wiederholen, bis der Spieler stirbt:
/AtariBot/bot_2_random.py
. . .
def main():
env = gym.make('SpaceInvaders-v0')
env.reset()
episode_reward = 0
while True:
action = env.action_space.sample()
_, reward, done, _ = env.step(action)
episode_reward += reward
if done:
print('Reward: %s' % episode_reward)
breakFühren Sie abschließend die Funktionmainaus. Fügen Sie eine__name__-Prüfung hinzu, um sicherzustellen, dassmain nur ausgeführt wird, wenn Sie es direkt mitpython bot_2_random.py aufrufen. Wenn Sie die Prüfungif nicht hinzufügen, wirdmain immer ausgelöst, wenn die Python-Dateieven when you import the file ausgeführt wird. Daher empfiehlt es sich, den Code in einemain-Funktion einzufügen, die nur ausgeführt wird, wenn__name__ == '__main__'.
/AtariBot/bot_2_random.py
. . .
def main():
. . .
if done:
print('Reward %s' % episode_reward)
break
if __name__ == '__main__':
main()Speichern Sie die Datei und beenden Sie den Editor. Wenn Sienano verwenden, drücken Sie dazuCTRL+X,Y und dannENTER. Führen Sie dann Ihr Skript aus, indem Sie Folgendes eingeben:
python bot_2_random.pyIhr Programm gibt eine Zahl aus, ähnlich der folgenden. Beachten Sie, dass Sie jedes Mal, wenn Sie die Datei ausführen, ein anderes Ergebnis erhalten:
OutputMaking new env: SpaceInvaders-v0
Reward: 210.0Diese zufälligen Ergebnisse sind problematisch. Um Arbeiten zu produzieren, von denen andere Forscher und Praktiker profitieren können, müssen Ihre Ergebnisse und Versuche reproduzierbar sein. Um dies zu korrigieren, öffnen Sie die Skriptdatei erneut:
nano bot_2_random.pyFügen Sie nachimport randomrandom.seed(0) hinzu. Fügen Sie nachenv = gym.make('SpaceInvaders-v0')env.seed(0) hinzu. Zusammen bilden diese Linien einen konstanten Ausgangspunkt für die Umwelt und stellen sicher, dass die Ergebnisse immer reproduzierbar sind. Ihre endgültige Datei entspricht genau den folgenden Kriterien:
/AtariBot/bot_2_random.py
"""
Bot 2 -- Make a random, baseline agent for the SpaceInvaders game.
"""
import gym
import random
random.seed(0)
def main():
env = gym.make('SpaceInvaders-v0')
env.seed(0)
env.reset()
episode_reward = 0
while True:
action = env.action_space.sample()
_, reward, done, _ = env.step(action)
episode_reward += reward
if done:
print('Reward: %s' % episode_reward)
break
if __name__ == '__main__':
main()Speichern Sie die Datei und schließen Sie Ihren Editor. Führen Sie dann das Skript aus, indem Sie Folgendes in Ihr Terminal eingeben:
python bot_2_random.pyDies gibt genau die folgende Belohnung aus:
OutputMaking new env: SpaceInvaders-v0
Reward: 555.0Dies ist Ihr allererster Bot, obwohl er ziemlich unintelligent ist, da er bei Entscheidungen die Umgebung nicht berücksichtigt. Um eine zuverlässigere Schätzung der Leistung Ihres Bots zu erhalten, kann der Agent für mehrere Episoden gleichzeitig ausgeführt werden. Dabei werden die Belohnungen über mehrere Episoden gemittelt. Um dies zu konfigurieren, öffnen Sie zuerst die Datei erneut:
nano bot_2_random.pyFügen Sie nachrandom.seed(0) die folgende hervorgehobene Zeile hinzu, die den Agenten anweist, das Spiel für 10 Episoden zu spielen:
/AtariBot/bot_2_random.py
. . .
random.seed(0)
num_episodes = 10
. . .Starten Sie direkt nachenv.seed(0) eine neue Liste mit Belohnungen:
/AtariBot/bot_2_random.py
. . .
env.seed(0)
rewards = []
. . .Verschachteln Sie den gesamten Code vonenv.reset() bis zum Ende vonmain() in einerfor-Schleife und iterieren Sienum_episodes-mal. Stellen Sie sicher, dass jede Zeile vonenv.reset() bisbreak um vier Leerzeichen eingerückt wird:
/AtariBot/bot_2_random.py
. . .
def main():
env = gym.make('SpaceInvaders-v0')
env.seed(0)
rewards = []
for _ in range(num_episodes):
env.reset()
episode_reward = 0
while True:
...Fügen Sie kurz vorbreak, derzeit der letzten Zeile der Hauptspielschleife, die Belohnung der aktuellen Episode zur Liste aller Belohnungen hinzu:
/AtariBot/bot_2_random.py
. . .
if done:
print('Reward: %s' % episode_reward)
rewards.append(episode_reward)
break
. . .Geben Sie am Ende der Funktionmaindie durchschnittliche Belohnung an:
/AtariBot/bot_2_random.py
. . .
def main():
...
print('Reward: %s' % episode_reward)
break
print('Average reward: %.2f' % (sum(rewards) / len(rewards)))
. . .Ihre Datei wird nun mit den folgenden ausgerichtet. Beachten Sie, dass der folgende Codeblock einige Kommentare enthält, um wichtige Teile des Skripts zu erläutern:
/AtariBot/bot_2_random.py
"""
Bot 2 -- Make a random, baseline agent for the SpaceInvaders game.
"""
import gym
import random
random.seed(0) # make results reproducible
num_episodes = 10
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
for _ in range(num_episodes):
env.reset()
episode_reward = 0
while True:
action = env.action_space.sample()
_, reward, done, _ = env.step(action) # random action
episode_reward += reward
if done:
print('Reward: %d' % episode_reward)
rewards.append(episode_reward)
break
print('Average reward: %.2f' % (sum(rewards) / len(rewards)))
if __name__ == '__main__':
main()Speichern Sie die Datei, beenden Sie den Editor und führen Sie das Skript aus:
python bot_2_random.pyDies gibt genau die folgende durchschnittliche Belohnung aus:
OutputMaking new env: SpaceInvaders-v0
. . .
Average reward: 163.50Wir haben jetzt eine zuverlässigere Schätzung des zu übertreffenden Basisergebnisses. Um jedoch einen überlegenen Agenten zu erstellen, müssen Sie den Rahmen für das Lernen zur Verstärkung verstehen. Wie kann man den abstrakten Begriff der Entscheidungsfindung konkreter machen?
Reinforcement Learning verstehen
In jedem Spiel besteht das Ziel des Spielers darin, die Punktzahl zu maximieren. In diesem Handbuch wird die Punktzahl des Spielers alsreward bezeichnet. Um ihre Belohnung zu maximieren, muss der Spieler in der Lage sein, seine Entscheidungsfähigkeiten zu verfeinern. Eine Entscheidung ist formal der Prozess des Betrachtens des Spiels oder des Beobachtens des Spielzustands und der Auswahl einer Aktion. Unsere Entscheidungsfunktion heißtpolicy; Eine Richtlinie akzeptiert einen Status als Eingabe und „entscheidet“ über eine Aktion:
policy: state -> actionUm eine solche Funktion aufzubauen, beginnen wir mit einem bestimmten Satz von Algorithmen für das Verstärkungslernen, dieQ-learning algorithms genannt werden. Betrachten Sie zur Veranschaulichung den Anfangszustand eines Spiels, den wirstate0 nennen: Ihr Raumschiff und die Außerirdischen befinden sich alle in ihrer Startposition. Dann nehmen wir an, wir haben Zugang zu einer magischen „Q-Tabelle“, die uns sagt, wie viel Belohnung jede Aktion bringt:
| Zustand | Aktion | Belohnung |
|---|---|---|
state0 |
schießen |
10 |
state0 |
richtig |
3 |
state0 |
left |
3 |
Die Aktion vonshootmaximiert Ihre Belohnung, da sie die Belohnung mit dem höchsten Wert ergibt: 10. Wie Sie sehen, bietet eine Q-Tabelle eine einfache Möglichkeit, Entscheidungen auf der Grundlage des beobachteten Zustands zu treffen:
policy: state -> look at Q-table, pick action with greatest rewardDie meisten Spiele haben jedoch zu viele Status, um sie in einer Tabelle aufzulisten. In solchen Fällen lernt der Q-Learning-Agent einQ-function anstelle einer Q-Tabelle. Wir verwenden diese Q-Funktion ähnlich wie zuvor die Q-Tabelle. Das Umschreiben der Tabelleneinträge als Funktionen ergibt Folgendes:
Q(state0, shoot) = 10
Q(state0, right) = 3
Q(state0, left) = 3In einem bestimmten Zustand fällt es uns leicht, eine Entscheidung zu treffen: Wir betrachten einfach jede mögliche Aktion und ihre Belohnung und ergreifen dann die Aktion, die der höchsten erwarteten Belohnung entspricht. Wenn wir die frühere Politik formeller umformulieren, haben wir:
policy: state -> argmax_{action} Q(state, action)Dies erfüllt die Anforderungen einer Entscheidungsfunktion: Wenn ein Zustand im Spiel vorliegt, entscheidet sie über eine Aktion. Diese Lösung hängt jedoch davon ab, dass SieQ(state, action) für jeden Zustand und jede Aktion kennen. Beachten Sie Folgendes, umQ(state, action) zu schätzen:
-
Angesichts vieler Beobachtungen der Zustände, Aktionen und Belohnungen eines Agenten kann man eine Schätzung der Belohnung für jeden Zustand und jede Aktion erhalten, indem man einen laufenden Durchschnitt nimmt.
-
Space Invaders ist ein Spiel mit verzögerten Belohnungen: Der Spieler wird belohnt, wenn der Alien in die Luft gesprengt wird und nicht, wenn der Spieler schießt. Der Spieler, der eine Aktion durch Schießen ausführt, ist jedoch der wahre Anstoß für die Belohnung. Irgendwie muss die Q-Funktion
(state0, shoot)eine positive Belohnung zuweisen.
Diese beiden Erkenntnisse sind in den folgenden Gleichungen kodifiziert:
Q(state, action) = (1 - learning_rate) * Q(state, action) + learning_rate * Q_target
Q_target = reward + discount_factor * max_{action'} Q(state', action')Diese Gleichungen verwenden die folgenden Definitionen:
-
state: Der Status zum aktuellen Zeitschritt -
action: Die im aktuellen Zeitschritt ausgeführte Aktion -
reward: Die Belohnung für den aktuellen Zeitschritt -
state': Der neue Status für den nächsten Zeitschritt, vorausgesetzt, wir haben die Aktionaausgeführt -
action': alle möglichen Aktionen -
learning_rate: die Lernrate -
discount_factor: Der Abzinsungsfaktor, wie viel Belohnung sich "verschlechtert", wenn wir sie verbreiten
Eine vollständige Erklärung dieser beiden Gleichungen finden Sie in diesem Artikel zuUnderstanding Q-Learning.
Unter Berücksichtigung dieses Verständnisses des Lernens im Bereich der Bestärkung müssen Sie nur noch das Spiel ausführen und diese Q-Wert-Schätzungen für eine neue Richtlinie abrufen.
[[Schritt 3 - Erstellen eines einfachen Q-Lernagenten für den gefrorenen See] == Schritt 3 - Erstellen eines einfachen Q-Lernagenten für den gefrorenen See
Nachdem Sie über einen Basisagenten verfügen, können Sie neue Agenten erstellen und mit dem Original vergleichen. In diesem Schritt erstellen Sie einen Agenten, derQ-learning verwendet, eine Verstärkung-Lerntechnik, mit der einem Agenten beigebracht wird, welche Aktion in einem bestimmten Zustand ausgeführt werden soll. Dieser Agent spielt ein neues Spiel,FrozenLake. Das Setup für dieses Spiel wird auf der Gym-Website wie folgt beschrieben:
Der Winter ist da. Sie und Ihre Freunde haben im Park einen Frisbee herumgeworfen, als Sie einen wilden Wurf gemacht haben, der den Frisbee mitten im See zurückließ. Das Wasser ist meistens gefroren, aber es gibt ein paar Löcher, in denen das Eis geschmolzen ist. Wenn Sie in eines dieser Löcher treten, fallen Sie ins gefrorene Wasser. Derzeit herrscht ein internationaler Frisbee-Mangel. Daher ist es unbedingt erforderlich, dass Sie über den See navigieren und die CD abrufen. Das Eis ist jedoch rutschig, sodass Sie sich nicht immer in die gewünschte Richtung bewegen.
Die Oberfläche wird mit einem Raster wie folgt beschrieben:
SFFF (S: starting point, safe)
FHFH (F: frozen surface, safe)
FFFH (H: hole, fall to your doom)
HFFG (G: goal, where the frisbee is located)Der Spieler beginnt oben links mitS und arbeitet sich bis zum Ziel unten rechts mitG vor. Die verfügbaren Aktionen sindright,left,up unddown. Das Erreichen des Ziels führt zu einer Punktzahl von 1. Es gibt eine Anzahl von Löchern, die mitH bezeichnet sind. Wenn Sie in ein Loch fallen, erhalten Sie sofort eine Punktzahl von 0.
In diesem Abschnitt implementieren Sie einen einfachen Q-Learning-Agenten. Mit dem, was Sie zuvor gelernt haben, erstellen Sie einen Agenten, der zwischenexploration undexploitation wechselt. Exploration bedeutet in diesem Zusammenhang, dass der Agent zufällig handelt, und Exploitation bedeutet, dass er anhand seiner Q-Werte wählt, was er für die optimale Aktion hält. Sie erstellen auch eine Tabelle, in der die Q-Werte enthalten sind, und aktualisieren sie schrittweise, während der Agent handelt und lernt.
Erstellen Sie eine Kopie Ihres Skripts aus Schritt 2:
cp bot_2_random.py bot_3_q_table.pyDann öffne diese neue Datei zum Bearbeiten:
nano bot_3_q_table.pyBeginnen Sie mit der Aktualisierung des Kommentars oben in der Datei, der den Zweck des Skripts beschreibt. Da dies nur ein Kommentar ist, ist diese Änderung nicht erforderlich, damit das Skript ordnungsgemäß funktioniert. Sie kann jedoch hilfreich sein, um die Funktionsweise des Skripts im Auge zu behalten:
/AtariBot/bot_3_q_table.py
"""
Bot 3 -- Build simple q-learning agent for FrozenLake
"""
. . .Bevor Sie funktionale Änderungen am Skript vornehmen, müssen Sienumpy für die Dienstprogramme für die lineare Algebra importieren. Fügen Sie direkt unterimport gym die hervorgehobene Zeile hinzu:
/AtariBot/bot_3_q_table.py
"""
Bot 3 -- Build simple q-learning agent for FrozenLake
"""
import gym
import numpy as np
import random
random.seed(0) # make results reproducible
. . .Fügen Sie unterrandom.seed(0) einen Startwert fürnumpy hinzu:
/AtariBot/bot_3_q_table.py
. . .
import random
random.seed(0) # make results reproducible
np.random.seed(0)
. . .Als nächstes machen Sie die Spielzustände zugänglich. Aktualisieren Sie die Zeileenv.reset() wie folgt, um den Anfangszustand des Spiels in der Variablenstate zu speichern:
/AtariBot/bot_3_q_table.py
. . .
for _ in range(num_episodes):
state = env.reset()
. . .Aktualisieren Sie die Zeileenv.step(...) wie folgt: Hier wird der nächste Statusstate2 gespeichert. Sie benötigen sowohl die aktuellenstate als auch die nächsten -state2 -, um die Q-Funktion zu aktualisieren.
/AtariBot/bot_3_q_table.py
. . .
while True:
action = env.action_space.sample()
state2, reward, done, _ = env.step(action)
. . .Fügen Sie nachepisode_reward += reward eine Zeile hinzu, in der die Variablestate aktualisiert wird. Dadurch wird die Variablestate für die nächste Iteration aktualisiert, da Sie erwarten, dassstate den aktuellen Status widerspiegelt:
/AtariBot/bot_3_q_table.py
. . .
while True:
. . .
episode_reward += reward
state = state2
if done:
. . .Löschen Sie im Blockif done die Anweisungprint, die die Belohnung für jede Episode druckt. Stattdessen geben Sie die durchschnittliche Belohnung für viele Episoden aus. Derif done-Block sieht dann folgendermaßen aus:
/AtariBot/bot_3_q_table.py
. . .
if done:
rewards.append(episode_reward)
break
. . .Nach diesen Änderungen wird Ihre Spielrunde wie folgt aussehen:
/AtariBot/bot_3_q_table.py
. . .
for _ in range(num_episodes):
state = env.reset()
episode_reward = 0
while True:
action = env.action_space.sample()
state2, reward, done, _ = env.step(action)
episode_reward += reward
state = state2
if done:
rewards.append(episode_reward))
break
. . .Fügen Sie als Nächstes die Möglichkeit für den Agenten hinzu, einen Kompromiss zwischen Exploration und Exploitation einzugehen. Erstellen Sie kurz vor Ihrer Hauptspielschleife (die mitfor... beginnt) die Q-Wert-Tabelle:
/AtariBot/bot_3_q_table.py
. . .
Q = np.zeros((env.observation_space.n, env.action_space.n))
for _ in range(num_episodes):
. . .Schreiben Sie dann diefor-Schleife neu, um die Episodennummer anzuzeigen:
/AtariBot/bot_3_q_table.py
. . .
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
. . .Erstellen Sie in der inneren Spielschleife vonwhile True:noise. Noise oder bedeutungslose Zufallsdaten werden manchmal beim Training tiefer neuronaler Netze eingeführt, da dies sowohl die Leistung als auch die Genauigkeit des Modells verbessern kann. Beachten Sie, dass je höher das Rauschen ist, desto weniger die Werte inQ[state, :] von Bedeutung sind. Je höher das Rauschen, desto wahrscheinlicher ist es, dass der Agent unabhängig von seiner Kenntnis des Spiels handelt. Mit anderen Worten, höheres Rauschen ermutigt den Agenten zu zufälligen Aktionen vonexplore:
/AtariBot/bot_3_q_table.py
. . .
while True:
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
action = env.action_space.sample()
. . .Beachten Sie, dass mit zunehmendem Prozentsatz (t0) s das Rauschen quadratisch abnimmt: Mit der Zeit erforscht der Agent immer weniger, da er seiner eigenen Einschätzung der Belohnung des Spiels vertrauen und mitexploit Wissen beginnen kann.
Aktualisieren Sie die Zeileaction, damit Ihr Agent Aktionen gemäß der Q-Wert-Tabelle auswählt, wobei einige Erkundungen integriert sind:
/AtariBot/bot_3_q_table.py
. . .
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
action = np.argmax(Q[state, :] + noise)
state2, reward, done, _ = env.step(action)
. . .Ihre Hauptspielrunde sieht dann so aus:
/AtariBot/bot_3_q_table.py
. . .
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
state = env.reset()
episode_reward = 0
while True:
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
action = np.argmax(Q[state, :] + noise)
state2, reward, done, _ = env.step(action)
episode_reward += reward
state = state2
if done:
rewards.append(episode_reward)
break
. . .Als Nächstes aktualisieren Sie Ihre Q-Wert-Tabelle mitBellman update equation, einer Gleichung, die beim maschinellen Lernen häufig verwendet wird, um die optimale Richtlinie in einer bestimmten Umgebung zu finden.
Die Bellman-Gleichung enthält zwei Ideen, die für dieses Projekt von hoher Relevanz sind. Erstens führt das mehrfache Ausführen einer bestimmten Aktion aus einem bestimmten Zustand zu einer guten Schätzung des Q-Werts, der diesem Zustand und dieser Aktion zugeordnet ist. Zu diesem Zweck erhöhen Sie die Anzahl der Folgen, die dieser Bot durchspielen muss, um eine stärkere Schätzung des Q-Werts zu erhalten. Zweitens müssen sich Belohnungen über die Zeit ausbreiten, damit der ursprünglichen Aktion eine Belohnung ungleich Null zugewiesen wird. Diese Idee ist am deutlichsten in Spielen mit verzögerten Belohnungen. In Space Invaders wird der Spieler beispielsweise belohnt, wenn der Alien in die Luft gesprengt wird und nicht, wenn der Spieler schießt. Das Schießen des Spielers ist jedoch der wahre Anstoß für eine Belohnung. Ebenso muss die Q-Funktion (state0,shoot) eine positive Belohnung zuweisen.
Aktualisieren Sie zuerstnum_episodes auf 4000:
/AtariBot/bot_3_q_table.py
. . .
np.random.seed(0)
num_episodes = 4000
. . .Fügen Sie dann die erforderlichen Hyperparameter in Form von zwei weiteren Variablen oben in die Datei ein:
/AtariBot/bot_3_q_table.py
. . .
num_episodes = 4000
discount_factor = 0.8
learning_rate = 0.9
. . .Berechnen Sie den neuen Q-Zielwert direkt nach der Zeile mitenv.step(...):
/AtariBot/bot_3_q_table.py
. . .
state2, reward, done, _ = env.step(action)
Qtarget = reward + discount_factor * np.max(Q[state2, :])
episode_reward += reward
. . .Aktualisieren Sie in der Zeile direkt nachQtarget die Q-Wert-Tabelle unter Verwendung eines gewichteten Durchschnitts der alten und neuen Q-Werte:
/AtariBot/bot_3_q_table.py
. . .
Qtarget = reward + discount_factor * np.max(Q[state2, :])
Q[state, action] = (1-learning_rate) * Q[state, action] + learning_rate * Qtarget
episode_reward += reward
. . .Stellen Sie sicher, dass Ihre Hauptspielrunde jetzt den folgenden Kriterien entspricht:
/AtariBot/bot_3_q_table.py
. . .
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
state = env.reset()
episode_reward = 0
while True:
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
action = np.argmax(Q[state, :] + noise)
state2, reward, done, _ = env.step(action)
Qtarget = reward + discount_factor * np.max(Q[state2, :])
Q[state, action] = (1-learning_rate) * Q[state, action] + learning_rate * Qtarget
episode_reward += reward
state = state2
if done:
rewards.append(episode_reward)
break
. . .Unsere Logik für die Schulung des Agenten ist nun abgeschlossen. Sie müssen nur noch Berichtsmechanismen hinzufügen.
Obwohl Python keine strenge Typprüfung erzwingt, fügen Sie Ihren Funktionsdeklarationen Typen hinzu, um die Sauberkeit zu gewährleisten. Importieren Sie oben in der Datei vor der ersten Zeile mitimport gym den TypList:
/AtariBot/bot_3_q_table.py
. . .
from typing import List
import gym
. . .Deklarieren Sie direkt nachlearning_rate = 0.9 außerhalb dermain-Funktion das Intervall und das Format für Berichte:
/AtariBot/bot_3_q_table.py
. . .
learning_rate = 0.9
report_interval = 500
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
def main():
. . .Fügen Sie vor der Funktionmain eine neue Funktion hinzu, die diese Zeichenfolgereportmit der Liste aller Belohnungen auffüllt:
/AtariBot/bot_3_q_table.py
. . .
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
def print_report(rewards: List, episode: int):
"""Print rewards report for current episode
- Average for last 100 episodes
- Best 100-episode average across all time
- Average for all episodes across time
"""
print(report % (
np.mean(rewards[-100:]),
max([np.mean(rewards[i:i+100]) for i in range(len(rewards) - 100)]),
np.mean(rewards),
episode))
def main():
. . .Ändern Sie das Spiel inFrozenLake anstelle vonSpaceInvaders:
/AtariBot/bot_3_q_table.py
. . .
def main():
env = gym.make('FrozenLake-v0') # create the game
. . .Drucken Sie nachrewards.append(...) die durchschnittliche Belohnung über die letzten 100 Folgen und die durchschnittliche Belohnung über alle Folgen:
/AtariBot/bot_3_q_table.py
. . .
if done:
rewards.append(episode_reward)
if episode % report_interval == 0:
print_report(rewards, episode)
. . .Geben Sie am Ende der Funktionmain() beide Mittelwerte noch einmal an. Ersetzen Sie dazu die Zeile mit der Aufschriftprint('Average reward: %.2f' % (sum(rewards) / len(rewards))) durch die folgende hervorgehobene Zeile:
/AtariBot/bot_3_q_table.py
. . .
def main():
...
break
print_report(rewards, -1)
. . .Schließlich haben Sie Ihren Q-Learning-Agenten abgeschlossen. Stellen Sie sicher, dass Ihr Skript mit den folgenden übereinstimmt:
/AtariBot/bot_3_q_table.py
"""
Bot 3 -- Build simple q-learning agent for FrozenLake
"""
from typing import List
import gym
import numpy as np
import random
random.seed(0) # make results reproducible
np.random.seed(0) # make results reproducible
num_episodes = 4000
discount_factor = 0.8
learning_rate = 0.9
report_interval = 500
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
def print_report(rewards: List, episode: int):
"""Print rewards report for current episode
- Average for last 100 episodes
- Best 100-episode average across all time
- Average for all episodes across time
"""
print(report % (
np.mean(rewards[-100:]),
max([np.mean(rewards[i:i+100]) for i in range(len(rewards) - 100)]),
np.mean(rewards),
episode))
def main():
env = gym.make('FrozenLake-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
state = env.reset()
episode_reward = 0
while True:
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
action = np.argmax(Q[state, :] + noise)
state2, reward, done, _ = env.step(action)
Qtarget = reward + discount_factor * np.max(Q[state2, :])
Q[state, action] = (1-learning_rate) * Q[state, action] + learning_rate * Qtarget
episode_reward += reward
state = state2
if done:
rewards.append(episode_reward)
if episode % report_interval == 0:
print_report(rewards, episode)
break
print_report(rewards, -1)
if __name__ == '__main__':
main()Speichern Sie die Datei, beenden Sie Ihren Editor und führen Sie das Skript aus:
python bot_3_q_table.pyIhre Ausgabe entspricht den folgenden Kriterien:
Output100-ep Average: 0.11 . Best 100-ep Average: 0.12 . Average: 0.03 (Episode 500)
100-ep Average: 0.25 . Best 100-ep Average: 0.24 . Average: 0.09 (Episode 1000)
100-ep Average: 0.39 . Best 100-ep Average: 0.48 . Average: 0.19 (Episode 1500)
100-ep Average: 0.43 . Best 100-ep Average: 0.55 . Average: 0.25 (Episode 2000)
100-ep Average: 0.44 . Best 100-ep Average: 0.55 . Average: 0.29 (Episode 2500)
100-ep Average: 0.64 . Best 100-ep Average: 0.68 . Average: 0.32 (Episode 3000)
100-ep Average: 0.63 . Best 100-ep Average: 0.71 . Average: 0.36 (Episode 3500)
100-ep Average: 0.56 . Best 100-ep Average: 0.78 . Average: 0.40 (Episode 4000)
100-ep Average: 0.56 . Best 100-ep Average: 0.78 . Average: 0.40 (Episode -1)Sie haben jetzt Ihren ersten nicht trivialen Bot für Spiele, aber lassen Sie uns diese durchschnittliche Belohnung von0.78 relativieren. LautGym FrozenLake page bedeutet „Lösen“ des Spiels das Erreichen eines 100-Episoden-Durchschnitts von0.78. Informell bedeutet "Lösen" "spielt das Spiel sehr gut". Der Q-table-Agent ist in der Lage, FrozenLake in 4000 Episoden zu lösen, obwohl dies nicht in Rekordzeit geschieht.
Das Spiel kann jedoch komplexer sein. In diesem Beispiel haben Sie eine Tabelle verwendet, um alle 144 möglichen Zustände zu speichern. Berücksichtigen Sie jedoch Tic Tac Toe, in dem es 19.683 mögliche Zustände gibt. Betrachten Sie auch Space Invaders, bei denen zu viele mögliche Zustände zu zählen sind. Ein Q-Table ist nicht nachhaltig, da Spiele immer komplexer werden. Aus diesem Grund benötigen Sie eine Annäherung an die Q-Tabelle. Während Sie im nächsten Schritt weiter experimentieren, entwerfen Sie eine Funktion, die Zustände und Aktionen als Eingaben akzeptieren und einen Q-Wert ausgeben kann.
[[Schritt 4 - Aufbau eines tiefen Q-Lernagenten für gefrorenen See] == Schritt 4 - Aufbau eines tiefen Q-Lernagenten für gefrorenen See
Beim Verstärkungslernen sagt das neuronale Netzwerk den Wert von Q basierend auf den Eingabenstate undaction effektiv voraus und verwendet eine Tabelle, um alle möglichen Werte zu speichern. Dies wird jedoch in komplexen Spielen instabil. Beim intensiven Verstärkungslernen wird stattdessen ein neuronales Netzwerk verwendet, um die Q-Funktion zu approximieren. Weitere Einzelheiten finden Sie unterUnderstanding Deep Q-Learning.
Um sich anTensorflow zu gewöhnen, eine Deep-Learning-Bibliothek, die Sie in Schritt 1 installiert haben, implementieren Sie die gesamte bisher mit Tensorflows Abstraktionen verwendete Logik neu und verwenden ein neuronales Netzwerk, um Ihre Q-Funktion zu approximieren. Ihr neuronales Netzwerk wird jedoch äußerst einfach sein: Ihre AusgabeQ(s) ist eine MatrixW multipliziert mit Ihrer Eingabes. Dies ist als neuronales Netzwerk mit einemfully-connected layer bekannt:
Q(s) = WsUm es noch einmal zu wiederholen, besteht das Ziel darin, die gesamte Logik der Bots, die wir bereits mithilfe der Tensorflow-Abstraktionen erstellt haben, erneut zu implementieren. Dadurch werden Ihre Vorgänge effizienter, da Tensorflow alle Berechnungen auf der GPU durchführen kann.
Beginnen Sie mit dem Duplizieren Ihres Q-Table-Skripts ab Schritt 3:
cp bot_3_q_table.py bot_4_q_network.pyÖffnen Sie dann die neue Datei mitnano oder Ihrem bevorzugten Texteditor:
nano bot_4_q_network.pyAktualisieren Sie zuerst den Kommentar oben in der Datei:
/AtariBot/bot_4_q_network.py
"""
Bot 4 -- Use Q-learning network to train bot
"""
. . .Importieren Sie als Nächstes das Tensorflow-Paket, indem Sie eineimport-Direktive direkt unterimport random hinzufügen. Fügen Sie außerdemtf.set_radon_seed(0) direkt unternp.random.seed(0) hinzu. Dadurch wird sichergestellt, dass die Ergebnisse dieses Skripts in allen Sitzungen wiederholt werden können:
/AtariBot/bot_4_q_network.py
. . .
import random
import tensorflow as tf
random.seed(0)
np.random.seed(0)
tf.set_random_seed(0)
. . .Definieren Sie Ihre Hyperparameter oben in der Datei neu, damit sie mit den folgenden übereinstimmen, und fügen Sie eine Funktion namensexploration_probability hinzu, die die Erkundungswahrscheinlichkeit bei jedem Schritt zurückgibt. Denken Sie daran, dass Exploration in diesem Zusammenhang bedeutet, eine zufällige Aktion auszuführen, anstatt die von den Q-Wert-Schätzungen empfohlene Aktion auszuführen:
/AtariBot/bot_4_q_network.py
. . .
num_episodes = 4000
discount_factor = 0.99
learning_rate = 0.15
report_interval = 500
exploration_probability = lambda episode: 50. / (episode + 10)
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
. . .Als nächstes fügen Sie eineone-hot encoding-Funktion hinzu. Kurz gesagt, One-Hot-Codierung ist ein Prozess, bei dem Variablen in eine Form konvertiert werden, mit der Algorithmen für maschinelles Lernen bessere Vorhersagen treffen können. Wenn Sie mehr über die One-Hot-Codierung erfahren möchten, können SieAdversarial Examples in Computer Vision: How to Build then Fool an Emotion-Based Dog Filter überprüfen.
Fügen Sie direkt unterreport = ... eineone_hot-Funktion hinzu:
/AtariBot/bot_4_q_network.py
. . .
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
def one_hot(i: int, n: int) -> np.array:
"""Implements one-hot encoding by selecting the ith standard basis vector"""
return np.identity(n)[i].reshape((1, -1))
def print_report(rewards: List, episode: int):
. . .Als Nächstes schreiben Sie Ihre Algorithmuslogik mithilfe der Tensorflow-Abstraktionen neu. Zuvor müssen Sie jedoch zuerstplaceholders für Ihre Daten erstellen.
Fügen Sie in Ihrermain-Funktion direkt unterrewards=[] den folgenden hervorgehobenen Inhalt ein. Hier definieren Sie Platzhalter für Ihre Beobachtung zum Zeitpunktt (alsobs_t_ph) und zum Zeitpunktt+1 (alsobs_tp1_ph) sowie Platzhalter für Ihre Aktion, Belohnung und Q Ziel:
/AtariBot/bot_4_q_network.py
. . .
def main():
env = gym.make('FrozenLake-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
# 1. Setup placeholders
n_obs, n_actions = env.observation_space.n, env.action_space.n
obs_t_ph = tf.placeholder(shape=[1, n_obs], dtype=tf.float32)
obs_tp1_ph = tf.placeholder(shape=[1, n_obs], dtype=tf.float32)
act_ph = tf.placeholder(tf.int32, shape=())
rew_ph = tf.placeholder(shape=(), dtype=tf.float32)
q_target_ph = tf.placeholder(shape=[1, n_actions], dtype=tf.float32)
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
. . .Fügen Sie direkt unter der Zeile, die mitq_target_ph = beginnt, die folgenden hervorgehobenen Zeilen ein. Dieser Code startet Ihre Berechnung, indem erQ(s, a) für allea berechnet, umq_current zu machen, undQ(s’, a’) für allea’, umq_target zu machen:
/AtariBot/bot_4_q_network.py
. . .
rew_ph = tf.placeholder(shape=(), dtype=tf.float32)
q_target_ph = tf.placeholder(shape=[1, n_actions], dtype=tf.float32)
# 2. Setup computation graph
W = tf.Variable(tf.random_uniform([n_obs, n_actions], 0, 0.01))
q_current = tf.matmul(obs_t_ph, W)
q_target = tf.matmul(obs_tp1_ph, W)
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
. . .Fügen Sie erneut direkt unter der zuletzt hinzugefügten Zeile den folgenden hervorgehobenen Code ein. Die ersten beiden Zeilen entsprechen der in Schritt 3 hinzugefügten Zeile, in derQtarget berechnet wird, wobeiQtarget = reward + discount_factor * np.max(Q[state2, :]). Die nächsten beiden Zeilen richten Ihren Verlust ein, während die letzte Zeile die Aktion berechnet, die Ihren Q-Wert maximiert:
/AtariBot/bot_4_q_network.py
. . .
q_current = tf.matmul(obs_t_ph, W)
q_target = tf.matmul(obs_tp1_ph, W)
q_target_max = tf.reduce_max(q_target_ph, axis=1)
q_target_sa = rew_ph + discount_factor * q_target_max
q_current_sa = q_current[0, act_ph]
error = tf.reduce_sum(tf.square(q_target_sa - q_current_sa))
pred_act_ph = tf.argmax(q_current, 1)
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
. . .Definieren Sie nach dem Einrichten Ihres Algorithmus und der Verlustfunktion Ihren Optimierer:
/AtariBot/bot_4_q_network.py
. . .
error = tf.reduce_sum(tf.square(q_target_sa - q_current_sa))
pred_act_ph = tf.argmax(q_current, 1)
# 3. Setup optimization
trainer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
update_model = trainer.minimize(error)
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
. . .Als nächstes richten Sie den Körper der Spielschleife ein. Übergeben Sie dazu Daten an die Tensorflow-Platzhalter, und die Tensorflow-Abstraktionen übernehmen die Berechnung auf der GPU und geben das Ergebnis des Algorithmus zurück.
Beginnen Sie mit dem Löschen der alten Q-Tabelle und Logik. Löschen Sie insbesondere die Zeilen, dieQ (direkt vor derfor-Schleife),noise (in derwhile-Schleife),action,Qtargetdefinieren. s undQ[state, action]. Benennen Siestate inobs_t undstate2 inobs_tp1 um, um sie an den zuvor festgelegten Tensorflow-Platzhaltern auszurichten. Wenn Sie fertig sind, stimmt Ihrefor-Schleife mit der folgenden überein:
/AtariBot/bot_4_q_network.py
. . .
# 3. Setup optimization
trainer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
update_model = trainer.minimize(error)
for episode in range(1, num_episodes + 1):
obs_t = env.reset()
episode_reward = 0
while True:
obs_tp1, reward, done, _ = env.step(action)
episode_reward += reward
obs_t = obs_tp1
if done:
...Fügen Sie direkt über derfor-Schleife die folgenden zwei hervorgehobenen Zeilen hinzu. Diese Zeilen initialisieren eine Tensorflow-Sitzung, die wiederum die Ressourcen verwaltet, die zum Ausführen von Vorgängen auf der GPU erforderlich sind. Die zweite Zeile initialisiert alle Variablen in Ihrem Berechnungsdiagramm. Initialisieren Sie beispielsweise die Gewichte auf 0, bevor Sie sie aktualisieren. Außerdem verschachteln Sie diefor-Schleife in derwith-Anweisung, sodass Sie die gesamtefor-Schleife um vier Leerzeichen einrücken:
/AtariBot/bot_4_q_network.py
. . .
trainer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
update_model = trainer.minimize(error)
with tf.Session() as session:
session.run(tf.global_variables_initializer())
for episode in range(1, num_episodes + 1):
obs_t = env.reset()
...Fügen Sie vor dem Lesen vonobs_tp1, reward, done, _ = env.step(action) die folgenden Zeilen ein, umaction zu berechnen. Dieser Code wertet den entsprechenden Platzhalter aus und ersetzt die Aktion mit einiger Wahrscheinlichkeit durch eine zufällige Aktion:
/AtariBot/bot_4_q_network.py
. . .
while True:
# 4. Take step using best action or random action
obs_t_oh = one_hot(obs_t, n_obs)
action = session.run(pred_act_ph, feed_dict={obs_t_ph: obs_t_oh})[0]
if np.random.rand(1) < exploration_probability(episode):
action = env.action_space.sample()
. . .Fügen Sie nach der Zeile mitenv.step(action) Folgendes ein, um das neuronale Netzwerk bei der Schätzung Ihrer Q-Wert-Funktion zu trainieren:
/AtariBot/bot_4_q_network.py
. . .
obs_tp1, reward, done, _ = env.step(action)
# 5. Train model
obs_tp1_oh = one_hot(obs_tp1, n_obs)
q_target_val = session.run(q_target, feed_dict={obs_tp1_ph: obs_tp1_oh})
session.run(update_model, feed_dict={
obs_t_ph: obs_t_oh,
rew_ph: reward,
q_target_ph: q_target_val,
act_ph: action
})
episode_reward += reward
. . .Ihre endgültige Datei entsprichtthis file hosted on GitHub. Speichern Sie die Datei, beenden Sie Ihren Editor und führen Sie das Skript aus:
python bot_4_q_network.pyIhre Ausgabe endet genau mit dem Folgenden:
Output100-ep Average: 0.11 . Best 100-ep Average: 0.11 . Average: 0.05 (Episode 500)
100-ep Average: 0.41 . Best 100-ep Average: 0.54 . Average: 0.19 (Episode 1000)
100-ep Average: 0.56 . Best 100-ep Average: 0.73 . Average: 0.31 (Episode 1500)
100-ep Average: 0.57 . Best 100-ep Average: 0.73 . Average: 0.36 (Episode 2000)
100-ep Average: 0.65 . Best 100-ep Average: 0.73 . Average: 0.41 (Episode 2500)
100-ep Average: 0.65 . Best 100-ep Average: 0.73 . Average: 0.43 (Episode 3000)
100-ep Average: 0.69 . Best 100-ep Average: 0.73 . Average: 0.46 (Episode 3500)
100-ep Average: 0.77 . Best 100-ep Average: 0.79 . Average: 0.48 (Episode 4000)
100-ep Average: 0.77 . Best 100-ep Average: 0.79 . Average: 0.48 (Episode -1)Sie haben jetzt Ihren ersten Deep Q-Learning-Agenten geschult. Für ein so einfaches Spiel wie FrozenLake benötigte Ihr Agent für vertiefendes Q-Learning 4000 Episoden, um zu trainieren. Stellen Sie sich vor, das Spiel wäre weitaus komplexer. Wie viele Trainingsmuster würde das erfordern, um zu trainieren? Wie sich herausstellt, könnte das Mittelmillions Proben benötigen. Die Anzahl der erforderlichen Proben wird alssample complexity bezeichnet, ein Konzept, das im nächsten Abschnitt näher erläutert wird.
Grundlegendes zu Bias-Varianz-Kompromissen
Im Allgemeinen steht die Komplexität der Stichproben im Widerspruch zur Komplexität des Modells beim maschinellen Lernen:
-
Model complexity: Man möchte ein ausreichend komplexes Modell, um sein Problem zu lösen. Beispielsweise ist ein Modell, das so einfach wie eine Linie ist, nicht komplex genug, um die Flugbahn eines Autos vorherzusagen.
-
Sample complexity: Man möchte ein Modell, das nicht viele Stichproben benötigt. Dies kann daran liegen, dass sie nur über eingeschränkten Zugriff auf beschriftete Daten, unzureichende Rechenleistung, begrenzten Speicher usw. verfügen.
Angenommen, wir haben zwei Modelle, ein einfaches und ein äußerst komplexes. Um bei beiden Modellen die gleiche Leistung zu erzielen, sagt die Bias-Varianz aus, dass das extrem komplexe Modell exponentiell mehr Samples zum Trainieren benötigt. Ein typisches Beispiel: Ihr auf neuronalen Netzen basierender Q-Learning-Agent benötigte 4000 Episoden, um FrozenLake zu lösen. Durch Hinzufügen einer zweiten Schicht zum neuronalen Netzwerkagenten wird die Anzahl der erforderlichen Trainingsepisoden vervierfacht. Bei immer komplexer werdenden neuronalen Netzen nimmt diese Kluft nur noch zu. Um die gleiche Fehlerrate beizubehalten, erhöht eine zunehmende Komplexität des Modells die Komplexität der Stichprobe exponentiell. Ebenso verringert eine Verringerung der Probenkomplexität die Modellkomplexität. Daher können wir die Modellkomplexität nicht maximieren und die Probenkomplexität nicht nach Herzenslust minimieren.
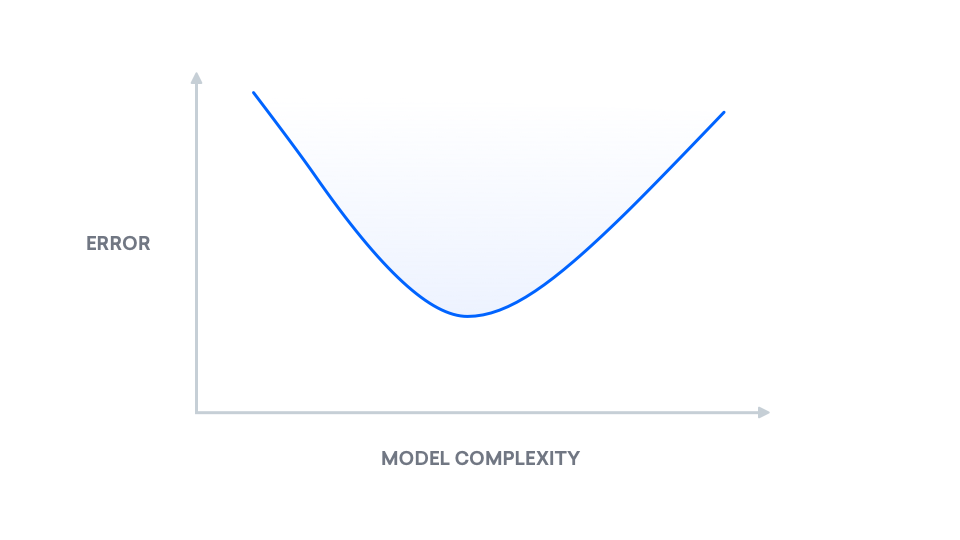
Wir können jedoch unser Wissen über diesen Kompromiss nutzen. Für eine visuelle Interpretation der Mathematik hinter denbias-variance decomposition sieheUnderstanding the Bias-Variance Tradeoff. Auf hohem Niveau ist die Bias-Varianz-Zerlegung eine Aufteilung des "wahren Fehlers" in zwei Komponenten: Bias und Varianz. Wir bezeichnen "wahren Fehler" alsmean squared error (MSE), was den erwarteten Unterschied zwischen unseren vorhergesagten Bezeichnungen und den wahren Bezeichnungen darstellt. Das folgende Diagramm zeigt die Änderung des „wahren Fehlers“ mit zunehmender Modellkomplexität:
[[Schritt 5 - Aufbau eines Agenten für kleinste Quadrate für gefrorenen See] == Schritt 5 - Aufbau eines Agenten für kleinste Quadrate für gefrorenen See
Dieleast squares-Methode, auch alslinear regression bekannt, ist ein Mittel zur Regressionsanalyse, das in den Bereichen Mathematik und Datenwissenschaft weit verbreitet ist. Beim maschinellen Lernen wird es häufig verwendet, um das optimale lineare Modell von zwei Parametern oder Datensätzen zu finden.
In Schritt 4 haben Sie ein neuronales Netzwerk erstellt, um Q-Werte zu berechnen. Anstelle eines neuronalen Netzwerks verwenden Sie in diesem Schrittridge regression, eine Variante der kleinsten Quadrate, um diesen Vektor von Q-Werten zu berechnen. Die Hoffnung ist, dass bei einem Modell, das so unkompliziert wie die kleinsten Quadrate ist, das Lösen des Spiels weniger Trainingsepisoden erfordert.
Beginnen Sie mit dem Duplizieren des Skripts ab Schritt 3:
cp bot_3_q_table.py bot_5_ls.pyÖffne die neue Datei:
nano bot_5_ls.pyAktualisieren Sie erneut den Kommentar oben in der Datei, der beschreibt, was dieses Skript bewirkt:
/AtariBot/bot_4_q_network.py
"""
Bot 5 -- Build least squares q-learning agent for FrozenLake
"""
. . .Fügen Sie vor dem Importblock am oberen Rand Ihrer Datei zwei weitere Importe zur Typprüfung hinzu:
/AtariBot/bot_5_ls.py
. . .
from typing import Tuple
from typing import Callable
from typing import List
import gym
. . .Fügen Sie in Ihrer Liste der Hyperparameter einen weiteren Hyperparameter hinzu,w_lr, um die Lernrate der zweiten Q-Funktion zu steuern. Aktualisieren Sie außerdem die Anzahl der Folgen auf 5000 und den Rabattfaktor auf0.85. Durch Ändern der Hyperparameternum_episodes unddiscount_factor auf größere Werte kann der Agent eine stärkere Leistung erzielen:
/AtariBot/bot_5_ls.py
. . .
num_episodes = 5000
discount_factor = 0.85
learning_rate = 0.9
w_lr = 0.5
report_interval = 500
. . .Fügen Sie vor Ihrerprint_report-Funktion die folgende Funktion höherer Ordnung hinzu. Es gibt ein Lambda zurück - eine anonyme Funktion - die das Modell abstrahiert:
/AtariBot/bot_5_ls.py
. . .
report_interval = 500
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
def makeQ(model: np.array) -> Callable[[np.array], np.array]:
"""Returns a Q-function, which takes state -> distribution over actions"""
return lambda X: X.dot(model)
def print_report(rewards: List, episode: int):
. . .Fügen Sie nachmakeQ eine weitere Funktion hinzu,initialize, die das Modell mit normalverteilten Werten initialisiert:
/AtariBot/bot_5_ls.py
. . .
def makeQ(model: np.array) -> Callable[[np.array], np.array]:
"""Returns a Q-function, which takes state -> distribution over actions"""
return lambda X: X.dot(model)
def initialize(shape: Tuple):
"""Initialize model"""
W = np.random.normal(0.0, 0.1, shape)
Q = makeQ(W)
return W, Q
def print_report(rewards: List, episode: int):
. . .Fügen Sie nach deminitialize-Block einetrain-Methode hinzu, die die geschlossene Lösung der Ridge-Regression berechnet, und gewichten Sie dann das alte Modell mit dem neuen. Es gibt sowohl das Modell als auch die abstrahierte Q-Funktion zurück:
/AtariBot/bot_5_ls.py
. . .
def initialize(shape: Tuple):
...
return W, Q
def train(X: np.array, y: np.array, W: np.array) -> Tuple[np.array, Callable]:
"""Train the model, using solution to ridge regression"""
I = np.eye(X.shape[1])
newW = np.linalg.inv(X.T.dot(X) + 10e-4 * I).dot(X.T.dot(y))
W = w_lr * newW + (1 - w_lr) * W
Q = makeQ(W)
return W, Q
def print_report(rewards: List, episode: int):
. . .Fügen Sie nachtrain eine letzte Funktion,one_hot, hinzu, um eine One-Hot-Codierung für Ihre Zustände und Aktionen durchzuführen:
/AtariBot/bot_5_ls.py
. . .
def train(X: np.array, y: np.array, W: np.array) -> Tuple[np.array, Callable]:
...
return W, Q
def one_hot(i: int, n: int) -> np.array:
"""Implements one-hot encoding by selecting the ith standard basis vector"""
return np.identity(n)[i]
def print_report(rewards: List, episode: int):
. . .Anschließend müssen Sie die Trainingslogik ändern. Im vorherigen Skript, das Sie geschrieben haben, wurde die Q-Tabelle bei jeder Iteration aktualisiert. Dieses Skript sammelt jedoch jedes Mal Muster und Etiketten und trainiert alle 10 Schritte ein neues Modell. Zusätzlich wird anstelle einer Q-Tabelle oder eines neuronalen Netzwerks ein Modell der kleinsten Quadrate verwendet, um Q-Werte vorherzusagen.
Gehen Sie zur Funktionmain und ersetzen Sie die Definition der Q-Tabelle (Q = np.zeros(...)) durch Folgendes:
/AtariBot/bot_5_ls.py
. . .
def main():
...
rewards = []
n_obs, n_actions = env.observation_space.n, env.action_space.n
W, Q = initialize((n_obs, n_actions))
states, labels = [], []
for episode in range(1, num_episodes + 1):
. . .Scrollen Sie vor derfor-Schleife nach unten. Fügen Sie direkt darunter die folgenden Zeilen hinzu, mit denen die Listenstates undlabels zurückgesetzt werden, wenn zu viele Informationen gespeichert sind:
/AtariBot/bot_5_ls.py
. . .
def main():
...
for episode in range(1, num_episodes + 1):
if len(states) >= 10000:
states, labels = [], []
. . .Ändern Sie die Zeile direkt nach dieser, diestate = env.reset() definiert, so, dass sie wie folgt lautet. Dadurch wird der Status sofort per One-Hot-Codierung codiert, da für alle Verwendungszwecke ein One-Hot-Vektor erforderlich ist:
/AtariBot/bot_5_ls.py
. . .
for episode in range(1, num_episodes + 1):
if len(states) >= 10000:
states, labels = [], []
state = one_hot(env.reset(), n_obs)
. . .Ändern Sie vor der ersten Zeile in der Hauptspielschleife vonwhiledie Liste derstates:
/AtariBot/bot_5_ls.py
. . .
for episode in range(1, num_episodes + 1):
...
episode_reward = 0
while True:
states.append(state)
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
. . .Aktualisieren Sie die Berechnung füraction, verringern Sie die Wahrscheinlichkeit von Rauschen und ändern Sie die Q-Funktionsbewertung:
/AtariBot/bot_5_ls.py
. . .
while True:
states.append(state)
noise = np.random.random((1, n_actions)) / episode
action = np.argmax(Q(state) + noise)
state2, reward, done, _ = env.step(action)
. . .Fügen Sie eine One-Hot-Version vonstate2 hinzu und ändern Sie den Q-Funktionsaufruf in Ihrer Definition fürQtarget wie folgt:
/AtariBot/bot_5_ls.py
. . .
while True:
...
state2, reward, done, _ = env.step(action)
state2 = one_hot(state2, n_obs)
Qtarget = reward + discount_factor * np.max(Q(state2))
. . .Löschen Sie die Zeile, in derQ[state,action] = ... aktualisiert wird, und ersetzen Sie sie durch die folgenden Zeilen. Dieser Code übernimmt die Ausgabe des aktuellen Modells und aktualisiert nur den Wert in dieser Ausgabe, der der aktuell ausgeführten Aktion entspricht. Infolgedessen gehen die Q-Werte für die anderen Aktionen nicht verloren:
/AtariBot/bot_5_ls.py
. . .
state2 = one_hot(state2, n_obs)
Qtarget = reward + discount_factor * np.max(Q(state2))
label = Q(state)
label[action] = (1 - learning_rate) * label[action] + learning_rate * Qtarget
labels.append(label)
episode_reward += reward
. . .Fügen Sie direkt nachstate = state2 eine regelmäßige Aktualisierung des Modells hinzu. Dies trainiert Ihr Modell alle 10 Zeitschritte:
/AtariBot/bot_5_ls.py
. . .
state = state2
if len(states) % 10 == 0:
W, Q = train(np.array(states), np.array(labels), W)
if done:
. . .Stellen Sie sicher, dass Ihre Datei mitthe source code übereinstimmt. Speichern Sie dann die Datei, beenden Sie den Editor und führen Sie das Skript aus:
python bot_5_ls.pyDies gibt Folgendes aus:
Output100-ep Average: 0.17 . Best 100-ep Average: 0.17 . Average: 0.09 (Episode 500)
100-ep Average: 0.11 . Best 100-ep Average: 0.24 . Average: 0.10 (Episode 1000)
100-ep Average: 0.08 . Best 100-ep Average: 0.24 . Average: 0.10 (Episode 1500)
100-ep Average: 0.24 . Best 100-ep Average: 0.25 . Average: 0.11 (Episode 2000)
100-ep Average: 0.32 . Best 100-ep Average: 0.31 . Average: 0.14 (Episode 2500)
100-ep Average: 0.35 . Best 100-ep Average: 0.38 . Average: 0.16 (Episode 3000)
100-ep Average: 0.59 . Best 100-ep Average: 0.62 . Average: 0.22 (Episode 3500)
100-ep Average: 0.66 . Best 100-ep Average: 0.66 . Average: 0.26 (Episode 4000)
100-ep Average: 0.60 . Best 100-ep Average: 0.72 . Average: 0.30 (Episode 4500)
100-ep Average: 0.75 . Best 100-ep Average: 0.82 . Average: 0.34 (Episode 5000)
100-ep Average: 0.75 . Best 100-ep Average: 0.82 . Average: 0.34 (Episode -1)Denken Sie daran, dass nach denGym FrozenLake page das „Lösen“ des Spiels das Erreichen eines 100-Episoden-Durchschnitts von 0,78 bedeutet. Hier erreicht der Agent einen Durchschnitt von 0,82, was bedeutet, dass er das Spiel in 5000 Episoden lösen konnte. Obwohl dies das Spiel nicht in weniger Episoden löst, ist diese Methode der kleinsten Quadrate immer noch in der Lage, ein einfaches Spiel mit ungefähr der gleichen Anzahl von Trainingsepisoden zu lösen. Obwohl Ihre neuronalen Netze immer komplexer werden, haben Sie gezeigt, dass für FrozenLake einfache Modelle ausreichen.
Damit haben Sie drei Q-Learning-Agenten erkundet: einen mithilfe einer Q-Tabelle, einen anderen mithilfe eines neuronalen Netzwerks und einen dritten mithilfe der kleinsten Quadrate. Als Nächstes bauen Sie ein Mittel zum vertieften Lernen für ein komplexeres Spiel auf: Space Invaders.
[[Schritt 6 - Erstellen eines Deep-Q-Learning-Agenten für Space Invaders]] == Schritt 6 - Erstellen eines Deep Q-Learning-Agenten für Space Invaders
Angenommen, Sie haben die Modellkomplexität und die Abtastkomplexität des vorherigen Q-Learning-Algorithmus perfekt abgestimmt, unabhängig davon, ob Sie sich für ein neuronales Netzwerk oder eine Methode der kleinsten Quadrate entschieden haben. Es stellt sich heraus, dass dieser unintelligente Q-Learning-Agent bei komplexeren Spielen trotz einer besonders hohen Anzahl von Trainingsepisoden immer noch eine schlechte Leistung erbringt. In diesem Abschnitt werden zwei Techniken behandelt, mit denen die Leistung verbessert werden kann. Anschließend testen Sie einen Agenten, der mit diesen Techniken geschult wurde.
Der erste Allzweckagent, der in der Lage ist, sein Verhalten ohne menschliches Eingreifen kontinuierlich anzupassen, wurde von den Forschern von DeepMind entwickelt, die ihren Agenten auch für verschiedene Atari-Spiele trainierten. DeepMind’s original deep Q-learning (DQN) paperhat zwei wichtige Probleme erkannt:
-
Correlated states: Nehmen Sie den Status unseres Spiels zum Zeitpunkt 0, den wirs0 nennen werden. Angenommen, wir aktualisierenQ(s0) gemäß den zuvor abgeleiteten Regeln. Nehmen Sie nun den Status zum Zeitpunkt 1, den wirs1 nennen, und aktualisieren SieQ(s1) nach denselben Regeln. Beachten Sie, dass der Status des Spiels zum Zeitpunkt 0 dem Status zum Zeitpunkt 1 sehr ähnlich ist. In Space Invaders haben sich die Aliens möglicherweise um jeweils ein Pixel bewegt. Genauer gesagt sinds0 unds1 sehr ähnlich. Ebenso erwarten wir, dassQ(s0) undQ(s1) sehr ähnlich sind, sodass die Aktualisierung eines das andere beeinflusst. Dies führt zu schwankenden Q-Werten, da eine Aktualisierung aufQ(s0) tatsächlich der Aktualisierung aufQ(s1) entgegenwirken kann. Formal sinds0 unds1correlated. Da die Q-Funktion deterministisch ist, korreliertQ(s1) mitQ(s0).
-
Q-function instability: Denken Sie daran, dass die FunktionQ sowohl das Modell ist, das wir trainieren, als auch die Quelle unserer Labels. Angenommen, unsere Beschriftungen sind zufällig ausgewählte Werte, die wirklichdistribution,L darstellen. Jedes Mal, wenn wirQ aktualisieren, ändern wirL, was bedeutet, dass unser Modell versucht, ein sich bewegendes Ziel zu lernen. Dies ist ein Problem, da die von uns verwendeten Modelle eine feste Verteilung annehmen.
Um korrelierte Zustände und eine instabile Q-Funktion zu bekämpfen:
-
Man könnte eine Liste von Zuständen führen, die alsreplay buffer bezeichnet werden. In jedem Zeitschritt fügen Sie den Spielstatus, den Sie beobachten, zu diesem Wiedergabepuffer hinzu. Sie wählen auch zufällig eine Untergruppe von Zuständen aus dieser Liste aus und trainieren diese Zustände.
-
Das Team von DeepMind hatQ(s, a) dupliziert. Eine heißtQ_current(s, a). Dies ist die Q-Funktion, die Sie aktualisieren. Sie benötigen eine weitere Q-Funktion für Nachfolgestatus,Q_target(s’, a’), die Sie nicht aktualisieren. RückrufQ_target(s’, a’) wird verwendet, um Ihre Etiketten zu generieren. Indem SieQ_current vonQ_target trennen und letzteres korrigieren, korrigieren Sie die Verteilung, aus der Ihre Etiketten abgetastet werden. Dann kann Ihr Deep-Learning-Modell eine kurze Zeit damit verbringen, diese Verteilung zu erlernen. Nach einer gewissen Zeit duplizieren SieQ_current erneut für ein neuesQ_target.
Sie werden diese nicht selbst implementieren, aber Sie werden vorab geschulte Modelle laden, die mit diesen Lösungen geschult wurden. Erstellen Sie dazu ein neues Verzeichnis, in dem Sie die Parameter dieser Modelle speichern:
mkdir modelsVerwenden Sie dannwget, um die Parameter eines vorab trainierten Space Invaders-Modells herunterzuladen:
wget http://models.tensorpack.com/OpenAIGym/SpaceInvaders-v0.tfmodel -P modelsLaden Sie als Nächstes ein Python-Skript herunter, das das Modell angibt, das den gerade heruntergeladenen Parametern zugeordnet ist. Beachten Sie, dass dieses vorab trainierte Modell zwei Einschränkungen für die Eingabe aufweist, die zu beachten sind:
-
Die Zustände müssen auf 84 x 84 heruntergerechnet oder verkleinert werden.
-
Die Eingabe besteht aus vier gestapelten Zuständen.
Auf diese Einschränkungen werden wir später noch näher eingehen. Laden Sie das Skript zunächst herunter, indem Sie Folgendes eingeben:
wget https://github.com/alvinwan/bots-for-atari-games/raw/master/src/bot_6_a3c.pySie werden jetzt diesen vorab geschulten Space Invaders-Agenten ausführen, um dessen Leistung zu überprüfen. Im Gegensatz zu den letzten Bots, die wir verwendet haben, schreiben Sie dieses Skript von Grund auf neu.
Erstellen Sie eine neue Skriptdatei:
nano bot_6_dqn.pyBeginnen Sie dieses Skript, indem Sie einen Kopfzeilenkommentar hinzufügen, die erforderlichen Dienstprogramme importieren und die Hauptspielschleife starten:
/AtariBot/bot_6_dqn.py
"""
Bot 6 - Fully featured deep q-learning network.
"""
import cv2
import gym
import numpy as np
import random
import tensorflow as tf
from bot_6_a3c import a3c_model
def main():
if __name__ == '__main__':
main()Legen Sie direkt nach dem Import zufällige Startwerte fest, um die Reproduzierbarkeit Ihrer Ergebnisse zu gewährleisten. Definieren Sie außerdem einen Hyperparameternum_episodes, der dem Skript mitteilt, für wie viele Episoden der Agent ausgeführt werden soll:
/AtariBot/bot_6_dqn.py
. . .
import tensorflow as tf
from bot_6_a3c import a3c_model
random.seed(0) # make results reproducible
tf.set_random_seed(0)
num_episodes = 10
def main():
. . .Definieren Sie zwei Zeilen nach dem Deklarieren vonnum_episodes einedownsample-Funktion, mit der alle Bilder auf eine Größe von 84 x 84 heruntergerechnet werden. Sie werden alle Bilder herunterrechnen, bevor Sie sie in das vortrainierte neuronale Netzwerk übertragen, da das vortrainierte Modell auf 84 x 84 Bildern trainiert wurde:
/AtariBot/bot_6_dqn.py
. . .
num_episodes = 10
def downsample(state):
return cv2.resize(state, (84, 84), interpolation=cv2.INTER_LINEAR)[None]
def main():
. . .Erstellen Sie die Spielumgebung zu Beginn Ihrermain-Funktion und legen Sie die Umgebung fest, damit die Ergebnisse reproduzierbar sind:
/AtariBot/bot_6_dqn.py
. . .
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
. . .Initialisieren Sie direkt nach dem Umgebungsstart eine leere Liste, um die Belohnungen zu speichern:
/AtariBot/bot_6_dqn.py
. . .
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
. . .Initialisieren Sie das vortrainierte Modell mit den vortrainierten Modellparametern, die Sie zu Beginn dieses Schritts heruntergeladen haben:
/AtariBot/bot_6_dqn.py
. . .
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
model = a3c_model(load='models/SpaceInvaders-v0.tfmodel')
. . .Fügen Sie als Nächstes einige Zeilen hinzu, in denen das Skript angewiesen wird,num_episodesMal zu iterieren, um die durchschnittliche Leistung zu berechnen und die Belohnung jeder Episode auf 0 zu initialisieren. Fügen Sie außerdem eine Zeile hinzu, um die Umgebung zurückzusetzen (env.reset()), den neuen Anfangszustand zu erfassen, diesen Anfangszustand mitdownsample() herunterzusampeln und die Spielschleife mit einerwhile-Schleife zu starten ::
/AtariBot/bot_6_dqn.py
. . .
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
model = a3c_model(load='models/SpaceInvaders-v0.tfmodel')
for _ in range(num_episodes):
episode_reward = 0
states = [downsample(env.reset())]
while True:
. . .Anstatt jeweils einen Zustand zu akzeptieren, akzeptiert das neue neuronale Netz jeweils vier Zustände. Daher müssen Sie warten, bis die Liste vonstates mindestens vier Zustände enthält, bevor Sie das vorab trainierte Modell anwenden. Fügen Sie die folgenden Zeilen unterhalb der Zeilewhile True: hinzu. Diese weisen den Agenten an, eine zufällige Aktion auszuführen, wenn weniger als vier Zustände vorhanden sind, oder die Zustände zu verketten und an das vortrainierte Modell weiterzuleiten, wenn mindestens vier vorhanden sind:
/AtariBot/bot_6_dqn.py
. . .
while True:
if len(states) < 4:
action = env.action_space.sample()
else:
frames = np.concatenate(states[-4:], axis=3)
action = np.argmax(model([frames]))
. . .Führen Sie dann eine Aktion aus und aktualisieren Sie die relevanten Daten. Füge eine heruntergerechnete Version des beobachteten Zustands hinzu und aktualisiere die Belohnung für diese Episode:
/AtariBot/bot_6_dqn.py
. . .
while True:
...
action = np.argmax(model([frames]))
state, reward, done, _ = env.step(action)
states.append(downsample(state))
episode_reward += reward
. . .Fügen Sie als Nächstes die folgenden Zeilen hinzu, in denen überprüft wird, ob die Episodedone beträgt, und drucken Sie gegebenenfalls die Gesamtbelohnung der Episode aus, ändern Sie die Liste aller Ergebnisse und unterbrechen Sie die Schleife vonwhilevorzeitig:
/AtariBot/bot_6_dqn.py
. . .
while True:
...
episode_reward += reward
if done:
print('Reward: %d' % episode_reward)
rewards.append(episode_reward)
break
. . .Drucken Sie außerhalb derwhile- undfor-Schleifen die durchschnittliche Belohnung aus. Platzieren Sie dies am Ende Ihrermain-Funktion:
/AtariBot/bot_6_dqn.py
def main():
...
break
print('Average reward: %.2f' % (sum(rewards) / len(rewards)))Überprüfen Sie, ob Ihre Datei den folgenden Kriterien entspricht:
/AtariBot/bot_6_dqn.py
"""
Bot 6 - Fully featured deep q-learning network.
"""
import cv2
import gym
import numpy as np
import random
import tensorflow as tf
from bot_6_a3c import a3c_model
random.seed(0) # make results reproducible
tf.set_random_seed(0)
num_episodes = 10
def downsample(state):
return cv2.resize(state, (84, 84), interpolation=cv2.INTER_LINEAR)[None]
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
model = a3c_model(load='models/SpaceInvaders-v0.tfmodel')
for _ in range(num_episodes):
episode_reward = 0
states = [downsample(env.reset())]
while True:
if len(states) < 4:
action = env.action_space.sample()
else:
frames = np.concatenate(states[-4:], axis=3)
action = np.argmax(model([frames]))
state, reward, done, _ = env.step(action)
states.append(downsample(state))
episode_reward += reward
if done:
print('Reward: %d' % episode_reward)
rewards.append(episode_reward)
break
print('Average reward: %.2f' % (sum(rewards) / len(rewards)))
if __name__ == '__main__':
main()Speichern Sie die Datei und beenden Sie Ihren Editor. Führen Sie dann das Skript aus:
python bot_6_dqn.pyIhre Ausgabe endet mit:
Output. . .
Reward: 1230
Reward: 4510
Reward: 1860
Reward: 2555
Reward: 515
Reward: 1830
Reward: 4100
Reward: 4350
Reward: 1705
Reward: 4905
Average reward: 2756.00Vergleichen Sie dies mit dem Ergebnis des ersten Skripts, in dem Sie einen zufälligen Agenten für Space Invaders ausgeführt haben. Die durchschnittliche Belohnung betrug in diesem Fall nur etwa 150, was bedeutet, dass dieses Ergebnis über zwanzigmal besser ist. Sie haben Ihren Code jedoch nur für drei Episoden ausgeführt, da er ziemlich langsam ist und der Durchschnitt von drei Episoden keine verlässliche Metrik ist. Läuft dies über 10 Episoden, liegt der Durchschnitt bei 2756; über 100 episoden liegt der durchschnitt bei 2500. Nur mit diesen Durchschnittswerten können Sie sicher schließen, dass Ihr Agent tatsächlich eine Größenordnung besser abschneidet und dass Sie jetzt einen Agenten haben, der Space Invaders recht gut spielt.
Erinnern Sie sich jedoch an das Problem, das im vorherigen Abschnitt in Bezug auf die Komplexität der Stichprobe angesprochen wurde. Wie sich herausstellt, nimmt dieser Space Invaders-Agent Millionen von Proben, um sie zu trainieren. Tatsächlich benötigte dieser Agent 24 Stunden auf vier Titan X-GPUs, um auf dieses aktuelle Niveau aufzurüsten. Mit anderen Worten, es war ein erheblicher Rechenaufwand erforderlich, um es angemessen zu trainieren. Können Sie einen ähnlich leistungsstarken Agenten mit weitaus weniger Proben ausbilden? Die vorherigen Schritte sollten Sie mit genügend Wissen ausstatten, um diese Frage zu untersuchen. Mit weitaus einfacheren Modellen und Kompromissen zwischen Abweichung und Abweichung kann dies möglich sein.
Fazit
In diesem Tutorial haben Sie mehrere Bots für Spiele erstellt und ein grundlegendes Konzept des maschinellen Lernens untersucht, das als Bias-Varianz bezeichnet wird. Die nächste Frage lautet natürlich: Können Sie Bots für komplexere Spiele wie StarCraft 2 erstellen? Wie sich herausstellt, handelt es sich hierbei um eine noch ausstehende Forschungsfrage, die durch Open-Source-Tools von Mitarbeitern aus Google, DeepMind und Blizzard ergänzt wird. Wenn dies Probleme sind, die Sie interessieren, finden Sie unteropen calls for research at OpenAI aktuelle Probleme.
Die wichtigste Erkenntnis aus diesem Tutorial ist der Bias-Varianz-Kompromiss. Es ist Aufgabe des maschinellen Lernens, die Auswirkungen der Modellkomplexität zu berücksichtigen. Während es möglich ist, hochkomplexe Modelle und Layer mit übermäßig viel Rechenaufwand, Stichproben und Zeit zu nutzen, kann eine reduzierte Modellkomplexität die erforderlichen Ressourcen erheblich reduzieren.