Einführung
Neuronale Netze werden als Methode des Tiefenlernens eingesetzt, eines der vielen Unterfelder der künstlichen Intelligenz. Sie wurden erstmals vor etwa 70 Jahren vorgeschlagen, um die Funktionsweise des menschlichen Gehirns zu simulieren, wenn auch in einer viel einfacheren Form. Einzelne "Neuronen" sind in Schichten verbunden, wobei Gewichte zugewiesen werden, um zu bestimmen, wie das Neuron reagiert, wenn Signale durch das Netzwerk übertragen werden. Bisher war die Anzahl der Neuronen, die sie simulieren konnten, und damit die Komplexität des Lernens, die sie erreichen konnten, bei neuronalen Netzen begrenzt. In den letzten Jahren konnten wir aufgrund der Fortschritte in der Hardwareentwicklung sehr tiefe Netzwerke aufbauen und diese auf enormen Datensätzen trainieren, um Durchbrüche in der Maschinenintelligenz zu erzielen.
Diese Durchbrüche haben es Maschinen ermöglicht, die Fähigkeiten des Menschen bei der Ausführung bestimmter Aufgaben zu erreichen und zu übertreffen. Eine solche Aufgabe ist die Objekterkennung. Obwohl Maschinen in der Vergangenheit nicht in der Lage waren, das menschliche Sehvermögen zu erreichen, haben die jüngsten Fortschritte beim Tiefenlernen den Aufbau neuronaler Netze ermöglicht, die Objekte, Gesichter, Text und sogar Emotionen erkennen können.
In diesem Lernprogramm implementieren Sie einen kleinen Unterabschnitt der Objekterkennung - Ziffernerkennung. Unter Verwendung von TensorFlow, einer Open-Source-Python-Bibliothek, die von den Google Brain Labs für Deep-Learning-Forschungen entwickelt wurde, können Sie von Hand gezeichnete Bilder der Nummern 0-9 erstellen und eine erstellen und trainieren neuronales Netzwerk, um die richtige Bezeichnung für die angezeigte Ziffer zu erkennen und vorherzusagen.
Während Sie keine Vorkenntnisse in praktischem Deep Learning oder TensorFlow benötigen, um diesem Lernprogramm zu folgen, werden wir uns mit Begriffen und Konzepten des maschinellen Lernens wie Training und Testen, Funktionen und Beschriftungen, Optimierung und Evaluierung vertraut machen. Weitere Informationen zu diesen Konzepten finden Sie unter Einführung in das maschinelle Lernen.
Voraussetzungen
Um dieses Tutorial abzuschließen, benötigen Sie:
-
Eine lokale https://www.digitalocean.com/community/tutorial_series/installations- und einrichtungshandbuch- für- lokale- programmierungsumgebung- für- Python-3[Python 3-Entwicklungsumgebung], einschließlich https : //pypi.org/project/pip/ [pip], ein Tool zum Installieren von Python-Paketen, und venv zum Erstellen virtueller Umgebungen.
Schritt 1 - Projekt konfigurieren
Bevor Sie das Erkennungsprogramm entwickeln können, müssen Sie einige Abhängigkeiten installieren und einen Arbeitsbereich für Ihre Dateien erstellen.
Wir verwenden eine virtuelle Python 3-Umgebung, um die Abhängigkeiten unseres Projekts zu verwalten. Erstellen Sie ein neues Verzeichnis für Ihr Projekt und navigieren Sie zu dem neuen Verzeichnis:
mkdir tensorflow-demo
cd tensorflow-demoFühren Sie die folgenden Befehle aus, um die virtuelle Umgebung für dieses Lernprogramm einzurichten:
python3 -m venv tensorflow-demo
source tensorflow-demo/bin/activateInstallieren Sie als Nächstes die Bibliotheken, die Sie in diesem Lernprogramm verwenden möchten. Wir werden bestimmte Versionen dieser Bibliotheken verwenden, indem wir eine "+ requirements.txt " - Datei im Projektverzeichnis erstellen, die die Anforderung und die Version angibt, die wir benötigen. Erstellen Sie die Datei ` requirements.txt +`:
touch requirements.txtÖffnen Sie die Datei in Ihrem Texteditor und fügen Sie die folgenden Zeilen hinzu, um die Image-, NumPy- und TensorFlow-Bibliotheken und ihre Versionen anzugeben:
requirements.txt
image==1.5.20
numpy==1.14.3
tensorflow==1.4.0Speichern Sie die Datei und beenden Sie den Editor. Installieren Sie dann diese Bibliotheken mit dem folgenden Befehl:
pip install -r requirements.txtMit den installierten Abhängigkeiten können wir mit der Arbeit an unserem Projekt beginnen.
Schritt 2 - Importieren des MNIST-Datensatzes
Der Datensatz, den wir in diesem Lernprogramm verwenden werden, heißt MNIST. Er ist ein Klassiker in der Community für maschinelles Lernen. Dieser Datensatz besteht aus Bildern handgeschriebener Ziffern mit einer Größe von 28 x 28 Pixel. Hier einige Beispiele für die im Datensatz enthaltenen Ziffern:
image: https://assets.digitalocean.com/articles/handwriting_tensorflow_python3/wBCHXId.png [Beispiele für MNIST-Bilder]
{kind=link}
Erstellen wir ein Python-Programm, um mit diesem Datensatz zu arbeiten. In diesem Tutorial verwenden wir eine Datei für alle unsere Arbeiten. Erstellen Sie eine neue Datei mit dem Namen "+ main.py +":
touch main.pyÖffnen Sie nun diese Datei in einem Texteditor Ihrer Wahl und fügen Sie diese Codezeile in die Datei ein, um die TensorFlow-Bibliothek zu importieren:
main.py
import tensorflow as tfFügen Sie Ihrer Datei die folgenden Codezeilen hinzu, um das MNIST-Dataset zu importieren und die Bilddaten in der Variablen "+ mnist +" zu speichern:
main.py
...
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # y labels are oh-encodedBeim Einlesen der Daten verwenden wir One-Hot-Codierung, um die Bezeichnungen darzustellen (die tatsächlich gezogene Ziffer, z. "3") der Bilder. One-Hot-Codierung verwendet einen Vektor von Binärwerten, um numerische oder kategoriale Werte darzustellen. Da unsere Bezeichnungen für die Ziffern 0-9 gelten, enthält der Vektor zehn Werte, einen für jede mögliche Ziffer. Einer dieser Werte wird auf 1 gesetzt, um die Ziffer an diesem Index des Vektors darzustellen, und der Rest wird auf 0 gesetzt. Beispielsweise wird die Ziffer 3 unter Verwendung des Vektors "+ [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0] +" dargestellt. Da der Wert am Index 3 als 1 gespeichert wird, repräsentiert der Vektor daher die Ziffer 3.
Um die tatsächlichen Bilder selbst darzustellen, werden die 28 x 28 Pixel zu einem 1D-Vektor abgeflacht, der 784 Pixel groß ist. Jedes der 784 Pixel, aus denen das Bild besteht, wird als Wert zwischen 0 und 255 gespeichert. Dies bestimmt die Graustufe des Pixels, da unsere Bilder nur in Schwarzweiß dargestellt werden. Ein schwarzes Pixel wird also durch 255 und ein weißes Pixel durch 0 dargestellt, wobei die verschiedenen Graustufen irgendwo dazwischen liegen.
Wir können die Variable + mnist + verwenden, um die Größe des gerade importierten Datensatzes zu ermitteln. Anhand der "+ num_examples +" für jede der drei Untermengen können wir feststellen, dass die Datenmenge in 55.000 Bilder für das Training, 5000 für die Validierung und 10.000 für das Testen aufgeteilt wurde. Fügen Sie Ihrer Datei die folgenden Zeilen hinzu:
main.py
...
n_train = mnist.train.num_examples # 55,000
n_validation = mnist.validation.num_examples # 5000
n_test = mnist.test.num_examples # 10,000Nachdem wir unsere Daten importiert haben, ist es an der Zeit, über das neuronale Netzwerk nachzudenken.
Schritt 3 - Definieren der neuronalen Netzwerkarchitektur
Die Architektur des neuronalen Netzwerks bezieht sich auf Elemente wie die Anzahl von Schichten im Netzwerk, die Anzahl von Einheiten in jeder Schicht und wie die Einheiten zwischen Schichten verbunden sind. Da neuronale Netze lose von der Funktionsweise des menschlichen Gehirns inspiriert sind, wird hier der Begriff Einheit verwendet, um darzustellen, was wir biologisch als Neuron betrachten würden. Wie Neuronen, die Signale durch das Gehirn leiten, nehmen Einheiten einige Werte von vorherigen Einheiten als Eingabe, führen eine Berechnung durch und leiten den neuen Wert als Ausgabe an andere Einheiten weiter. Diese Einheiten werden geschichtet, um das Netzwerk zu bilden, beginnend mit mindestens einer Schicht zur Eingabe von Werten und einer Schicht zur Ausgabe von Werten. Der Ausdruck "versteckte Schicht" wird für alle Schichten zwischen der Eingangs- und der Ausgangsschicht verwendet, d.h. diese "versteckt" vor der realen Welt.
Unterschiedliche Architekturen können zu dramatisch unterschiedlichen Ergebnissen führen, da die Leistung unter anderem als Funktion der Architektur betrachtet werden kann, z. B. als Parameter, Daten und Trainingsdauer.
Fügen Sie Ihrer Datei die folgenden Codezeilen hinzu, um die Anzahl der Einheiten pro Layer in globalen Variablen zu speichern. Auf diese Weise können wir die Netzwerkarchitektur an einer Stelle ändern. Am Ende des Lernprogramms können Sie selbst testen, wie sich die unterschiedliche Anzahl von Ebenen und Einheiten auf die Ergebnisse unseres Modells auswirkt:
main.py
...
n_input = 784 # input layer (28x28 pixels)
n_hidden1 = 512 # 1st hidden layer
n_hidden2 = 256 # 2nd hidden layer
n_hidden3 = 128 # 3rd hidden layer
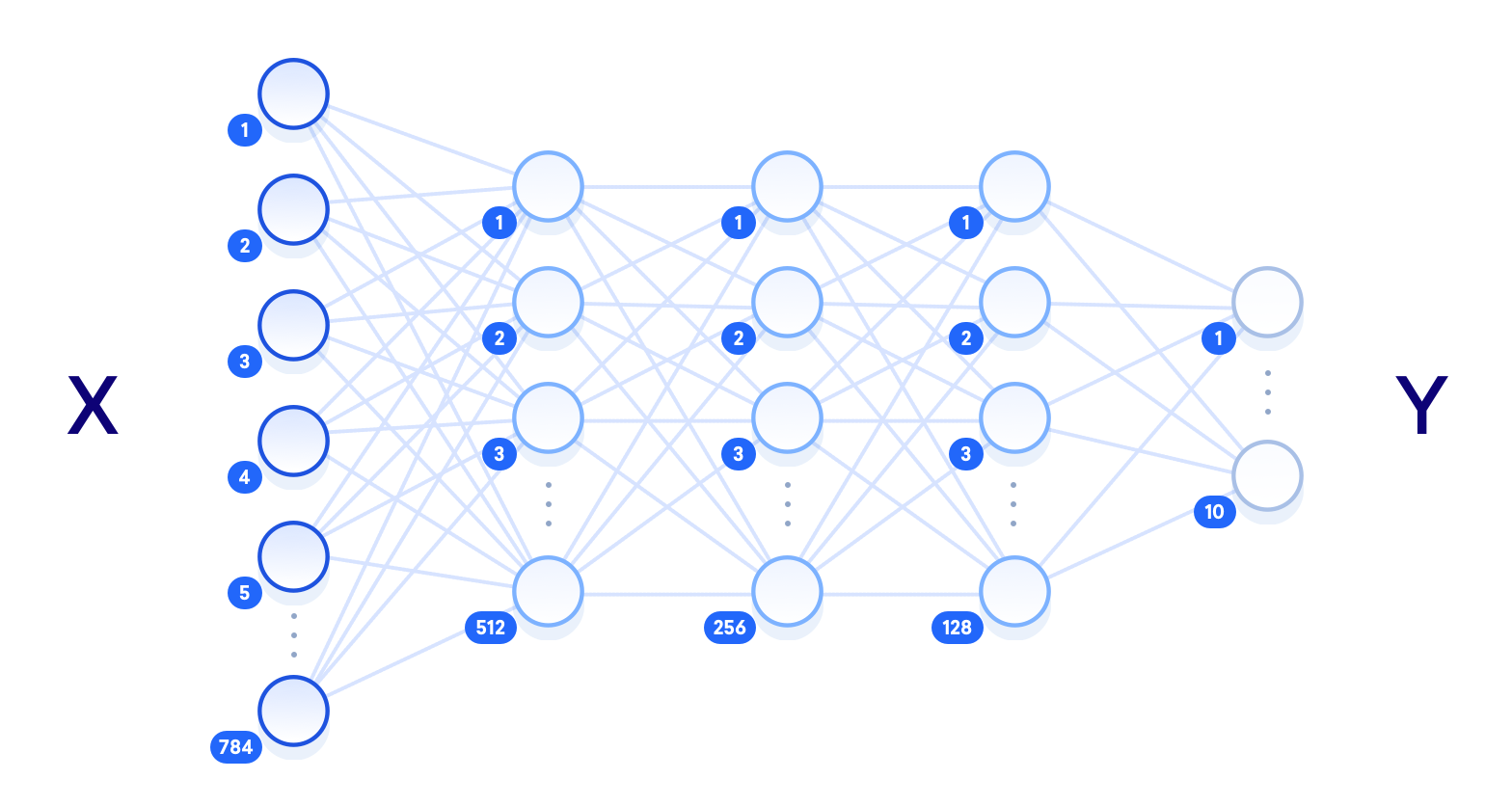
n_output = 10 # output layer (0-9 digits)Das folgende Diagramm zeigt eine Visualisierung der von uns entworfenen Architektur, wobei jede Ebene vollständig mit den umgebenden Ebenen verbunden ist:
image: https://assets.digitalocean.com/articles/handwriting_tensorflow_python3/cnwitLM.png [Diagramm eines neuronalen Netzwerks]
{kind=link}
Der Begriff "tiefes neuronales Netzwerk" bezieht sich auf die Anzahl der verborgenen Schichten, wobei "flach" normalerweise nur eine verborgene Schicht bedeutet und "tief" sich auf mehrere verborgene Schichten bezieht. Bei ausreichenden Trainingsdaten sollte ein flaches neuronales Netzwerk mit einer ausreichenden Anzahl von Einheiten theoretisch jede Funktion darstellen können, die ein tiefes neuronales Netzwerk kann. Es ist jedoch oft recheneffizienter, ein kleineres, tiefes neuronales Netzwerk zu verwenden, um die gleiche Aufgabe zu erfüllen, die ein flaches Netzwerk mit exponentiell mehr verborgenen Einheiten erfordern würde. Auch bei flachen neuronalen Netzen kommt es häufig zu einer Überanpassung, bei der das Netzwerk die ermittelten Trainingsdaten im Wesentlichen speichert und das Wissen nicht auf neue Daten verallgemeinern kann. Aus diesem Grund werden häufig tiefe neuronale Netze verwendet: Durch die mehreren Schichten zwischen den rohen Eingabedaten und dem Ausgabeetikett kann das Netzwerk Features auf verschiedenen Abstraktionsebenen erlernen, wodurch das Netzwerk selbst in der Lage ist, Verallgemeinerungen vorzunehmen.
Andere Elemente des neuronalen Netzwerks, die hier definiert werden müssen, sind die Hyperparameter. Im Gegensatz zu den Parametern, die während des Trainings aktualisiert werden, werden diese Werte anfänglich festgelegt und bleiben während des gesamten Prozesses konstant. Legen Sie in Ihrer Datei die folgenden Variablen und Werte fest:
main.py
...
learning_rate = 1e-4
n_iterations = 1000
batch_size = 128
dropout = 0.5Die Lernrate gibt an, wie stark sich die Parameter bei jedem Schritt des Lernprozesses anpassen. Diese Anpassungen sind eine Schlüsselkomponente des Trainings: Nach jedem Durchlauf durch das Netzwerk stimmen wir die Gewichte leicht ab, um den Verlust zu reduzieren. Größere Lernraten können schneller konvergieren, können aber auch die optimalen Werte überschreiten, wenn sie aktualisiert werden. Die Anzahl der Iterationen bezieht sich darauf, wie oft wir den Trainingsschritt durchlaufen, und die Stapelgröße bezieht sich darauf, wie viele Trainingsbeispiele wir in jedem Schritt verwenden. Die Variable "+ Dropout " stellt einen Schwellenwert dar, bei dem wir einige Einheiten zufällig entfernen. Wir werden " Dropout +" in unserer letzten verborgenen Ebene verwenden, um jeder Einheit eine 50% ige Chance zu geben, bei jedem Trainingsschritt eliminiert zu werden. Dies hilft, eine Überanpassung zu verhindern.
Wir haben nun die Architektur unseres neuronalen Netzwerks und die Hyperparameter definiert, die sich auf den Lernprozess auswirken. Der nächste Schritt besteht darin, das Netzwerk als TensorFlow-Diagramm aufzubauen.
Schritt 4 - Erstellen des TensorFlow-Diagramms
Um unser Netzwerk aufzubauen, richten wir das Netzwerk als Rechengraph ein, damit TensorFlow ausgeführt werden kann. Das Kernkonzept von TensorFlow ist der tensor, eine Datenstruktur ähnlich einem Array oder einer Liste. Initialisiert, manipuliert, während sie durch das Diagramm geleitet und während des Lernprozesses aktualisiert werden.
Zunächst definieren wir drei Tensoren als Platzhalter. Dies sind Tensoren, in die wir später Werte eingeben. Fügen Sie Ihrer Datei Folgendes hinzu:
main.py
...
X = tf.placeholder("float", [None, n_input])
Y = tf.placeholder("float", [None, n_output])
keep_prob = tf.placeholder(tf.float32)Der einzige Parameter, der bei der Deklaration angegeben werden muss, ist die Größe der Daten, die wir einspeisen. Für "+ X " verwenden wir eine Form von " [None, 784] ", wobei " None " eine beliebige Menge darstellt, da wir eine undefinierte Anzahl von 784-Pixel-Bildern einspeisen. Die Form von " Y " ist " [None, 10] ", da wir sie für eine undefinierte Anzahl von Etikettenausgaben mit 10 möglichen Klassen verwenden werden. Der Tensor ` keep_prob ` wird verwendet, um die Abbruchrate zu steuern, und wir initialisieren ihn als Platzhalter und nicht als unveränderliche Variable, da wir für das Training denselben Tensor verwenden möchten (wenn ` dropout ` auf `+0.5 eingestellt ist) ) und testen (wenn + dropout + auf + 1.0 + `gesetzt ist).
Die Parameter, die das Netzwerk während des Trainings aktualisiert, sind die Werte "+ weight " und " bias +". Daher müssen wir für diese Werte einen Anfangswert anstelle eines leeren Platzhalters festlegen. Diese Werte sind im Wesentlichen der Ort, an dem das Netzwerk lernt, da sie in den Aktivierungsfunktionen der Neuronen verwendet werden und die Stärke der Verbindungen zwischen Einheiten darstellen.
Da die Werte während des Trainings optimiert werden, können wir sie vorerst auf Null setzen. Der Anfangswert hat jedoch einen erheblichen Einfluss auf die endgültige Genauigkeit des Modells. Wir verwenden zufällige Werte aus einer abgeschnittenen Normalverteilung für die Gewichte. Wir möchten, dass sie nahe bei Null liegen, damit sie sich entweder in positiver oder negativer Richtung anpassen können und leicht unterschiedlich sind, sodass sie unterschiedliche Fehler erzeugen. Dadurch wird sichergestellt, dass das Modell etwas Nützliches lernt. Fügen Sie diese Zeilen hinzu:
main.py
...
weights = {
'w1': tf.Variable(tf.truncated_normal([n_input, n_hidden1], stddev=0.1)),
'w2': tf.Variable(tf.truncated_normal([n_hidden1, n_hidden2], stddev=0.1)),
'w3': tf.Variable(tf.truncated_normal([n_hidden2, n_hidden3], stddev=0.1)),
'out': tf.Variable(tf.truncated_normal([n_hidden3, n_output], stddev=0.1)),
}Für die Vorspannung verwenden wir einen kleinen konstanten Wert, um sicherzustellen, dass die Tensoren in den Anfangsstadien aktiviert werden und daher zur Ausbreitung beitragen. Die Gewichte und Vorspannungstensoren werden in Wörterbuchobjekten gespeichert, um den Zugriff zu erleichtern. Fügen Sie diesen Code zu Ihrer Datei hinzu, um die Verzerrungen zu definieren:
main.py
...
biases = {
'b1': tf.Variable(tf.constant(0.1, shape=[n_hidden1])),
'b2': tf.Variable(tf.constant(0.1, shape=[n_hidden2])),
'b3': tf.Variable(tf.constant(0.1, shape=[n_hidden3])),
'out': tf.Variable(tf.constant(0.1, shape=[n_output]))
}Als nächstes richten Sie die Schichten des Netzwerks ein, indem Sie die Operationen definieren, die die Tensoren manipulieren. Fügen Sie diese Zeilen zu Ihrer Datei hinzu:
main.py
...
layer_1 = tf.add(tf.matmul(X, weights['w1']), biases['b1'])
layer_2 = tf.add(tf.matmul(layer_1, weights['w2']), biases['b2'])
layer_3 = tf.add(tf.matmul(layer_2, weights['w3']), biases['b3'])
layer_drop = tf.nn.dropout(layer_3, keep_prob)
output_layer = tf.matmul(layer_3, weights['out']) + biases['out']Jede ausgeblendete Ebene führt eine Matrixmultiplikation auf den Ausgängen der vorherigen Ebene und den Gewichten der aktuellen Ebene durch und addiert die Verzerrung zu diesen Werten. Auf der letzten ausgeblendeten Ebene wenden wir eine Dropout-Operation mit unserem "+ keep_prob +" - Wert von 0,5 an.
Der letzte Schritt beim Erstellen des Diagramms besteht darin, die Verlustfunktion zu definieren, die optimiert werden soll. Eine beliebte Wahl der Verlustfunktion in TensorFlow-Programmen ist die Kreuzentropie, auch als log-loss bekannt, die den Unterschied zwischen zwei Wahrscheinlichkeitsverteilungen (den Vorhersagen und den Markierungen) quantifiziert. Eine perfekte Klassifizierung würde zu einer Kreuzentropie von 0 führen, wobei der Verlust vollständig minimiert würde.
Wir müssen auch den Optimierungsalgorithmus auswählen, der verwendet wird, um die Verlustfunktion zu minimieren. Ein Prozess namens Gradientenabstiegsoptimierung ist eine übliche Methode, um das (lokale) Minimum einer Funktion zu finden, indem iterative Schritte entlang des Gradienten in einer negativen (absteigenden) Richtung ausgeführt werden. In TensorFlow sind bereits verschiedene Optimierungsalgorithmen für den Gradientenabstieg implementiert. In diesem Lernprogramm wird Adam optimizer verwendet. Dies gilt auch für die Optimierung des Gefälleverlaufs, indem der Prozess mithilfe des Impulses beschleunigt wird, indem ein exponentiell gewichteter Durchschnitt der Gefälle berechnet und bei den Anpassungen verwendet wird. Fügen Sie Ihrer Datei den folgenden Code hinzu:
main.py
...
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(
labels=Y, logits=output_layer
))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)Wir haben jetzt das Netzwerk definiert und es mit TensorFlow aufgebaut. Der nächste Schritt besteht darin, Daten durch das Diagramm zu führen, um sie zu trainieren, und dann zu testen, ob sie tatsächlich etwas gelernt haben.
Schritt 5 - Training und Testen
Der Trainingsprozess beinhaltet das Zuführen des Trainingsdatensatzes durch das Diagramm und das Optimieren der Verlustfunktion. Jedes Mal, wenn das Netzwerk eine Reihe weiterer Trainingsbilder durchläuft, werden die Parameter aktualisiert, um den Verlust zu verringern und die angezeigten Ziffern genauer vorherzusagen. Der Testprozess umfasst das Durchlaufen des Testdatensatzes durch das trainierte Diagramm und das Verfolgen der Anzahl der Bilder, die korrekt vorhergesagt wurden, damit wir die Genauigkeit berechnen können.
Bevor wir mit dem Training beginnen, definieren wir unsere Methode zur Bewertung der Genauigkeit, damit wir sie während des Trainings auf kleinen Datenmengen ausdrucken können. Mit diesen gedruckten Anweisungen können wir überprüfen, ob der Verlust von der ersten bis zur letzten Iteration abnimmt und die Genauigkeit zunimmt. Sie ermöglichen es uns auch zu verfolgen, ob wir genügend Iterationen ausgeführt haben, um ein konsistentes und optimales Ergebnis zu erzielen:
main.py
...
correct_pred = tf.equal(tf.argmax(output_layer, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))In "+ correct_pred " verwenden wir die Funktion " arg_max ", um zu vergleichen, welche Bilder korrekt vorhergesagt werden, indem wir die " output_layer " (Vorhersagen) und " Y " (Beschriftungen) betrachten, und wir verwenden das " equal +" Funktion, um dies als eine Liste von Booleans zurückzugeben. Wir können diese Liste dann in Gleitkommazahlen umwandeln und den Mittelwert berechnen, um eine Gesamtgenauigkeit zu erhalten.
Jetzt können Sie eine Sitzung zum Ausführen des Diagramms initialisieren. In dieser Sitzung werden wir das Netzwerk mit unseren Trainingsbeispielen versorgen. Sobald wir trainiert haben, versorgen wir dasselbe Diagramm mit neuen Testbeispielen, um die Genauigkeit des Modells zu bestimmen. Fügen Sie Ihrer Datei die folgenden Codezeilen hinzu:
main.py
...
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)Die Essenz des Trainingsprozesses im Deep Learning besteht darin, die Verlustfunktion zu optimieren. Hier wollen wir den Unterschied zwischen den vorhergesagten Bezeichnungen der Bilder und den wahren Bezeichnungen der Bilder minimieren. Der Prozess umfasst vier Schritte, die für eine festgelegte Anzahl von Iterationen wiederholt werden:
-
Werte über das Netzwerk weiterleiten
-
Berechnen Sie den Verlust
-
Übertragen Sie Werte rückwärts über das Netzwerk
-
Aktualisieren Sie die Parameter
Bei jedem Trainingsschritt werden die Parameter leicht angepasst, um den Verlust für den nächsten Schritt zu verringern. Mit fortschreitendem Lernen sollten wir eine Verringerung der Verluste feststellen, und schließlich können wir das Training beenden und das Netzwerk als Modell zum Testen unserer neuen Daten verwenden.
Fügen Sie diesen Code zur Datei hinzu:
main.py
...
# train on mini batches
for i in range(n_iterations):
batch_x, batch_y = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={
X: batch_x, Y: batch_y, keep_prob: dropout
})
# print loss and accuracy (per minibatch)
if i % 100 == 0:
minibatch_loss, minibatch_accuracy = sess.run(
[cross_entropy, accuracy],
feed_dict={X: batch_x, Y: batch_y, keep_prob: 1.0}
)
print(
"Iteration",
str(i),
"\t| Loss =",
str(minibatch_loss),
"\t| Accuracy =",
str(minibatch_accuracy)
)Nach 100 Iterationen jedes Trainingsschritts, in dem wir einen kleinen Stapel von Bildern über das Netzwerk übertragen, drucken wir den Verlust und die Genauigkeit dieses Stapels aus. Beachten Sie, dass wir hier nicht mit einem abnehmenden Verlust und einer zunehmenden Genauigkeit rechnen sollten, da die Werte pro Charge und nicht für das gesamte Modell gelten. Wir verwenden Mini-Batches von Bildern, anstatt sie einzeln durchzuziehen, um den Trainingsprozess zu beschleunigen und dem Netzwerk eine Reihe verschiedener Beispiele zu ermöglichen, bevor die Parameter aktualisiert werden.
Sobald das Training abgeschlossen ist, können wir die Sitzung mit den Testbildern durchführen. Dieses Mal verwenden wir eine Dropout-Rate von "+ keep_prob " von " 1.0 +", um sicherzustellen, dass alle Einheiten im Testprozess aktiv sind.
Fügen Sie diesen Code zur Datei hinzu:
main.py
...
test_accuracy = sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1.0})
print("\nAccuracy on test set:", test_accuracy)Es ist jetzt Zeit, unser Programm auszuführen und zu sehen, wie genau unser neuronales Netzwerk diese handgeschriebenen Ziffern erkennen kann. Speichern Sie die Datei + main.py + und führen Sie den folgenden Befehl im Terminal aus, um das Skript auszuführen:
python main.pyEs wird eine Ausgabe angezeigt, die der folgenden ähnelt, obwohl die Ergebnisse einzelner Verluste und der Genauigkeit geringfügig variieren können:
OutputIteration 0 | Loss = 3.67079 | Accuracy = 0.140625
Iteration 100 | Loss = 0.492122 | Accuracy = 0.84375
Iteration 200 | Loss = 0.421595 | Accuracy = 0.882812
Iteration 300 | Loss = 0.307726 | Accuracy = 0.921875
Iteration 400 | Loss = 0.392948 | Accuracy = 0.882812
Iteration 500 | Loss = 0.371461 | Accuracy = 0.90625
Iteration 600 | Loss = 0.378425 | Accuracy = 0.882812
Iteration 700 | Loss = 0.338605 | Accuracy = 0.914062
Iteration 800 | Loss = 0.379697 | Accuracy = 0.875
Iteration 900 | Loss = 0.444303 | Accuracy = 0.90625
Accuracy on test set: 0.9206Um die Genauigkeit unseres Modells zu verbessern oder mehr über die Auswirkungen der Optimierung von Hyperparametern zu erfahren, können wir den Effekt der Änderung der Lernrate, des Dropout-Schwellenwerts, der Stapelgröße und der Anzahl der Iterationen testen. Wir können auch die Anzahl der Einheiten in unseren ausgeblendeten Ebenen und die Anzahl der ausgeblendeten Ebenen selbst ändern, um zu sehen, wie unterschiedliche Architekturen die Modellgenauigkeit erhöhen oder verringern.
Um zu demonstrieren, dass das Netzwerk die handgezeichneten Bilder tatsächlich erkennt, testen wir sie an einem einzelnen Bild.
Wenn Sie sich auf einem lokalen Computer befinden und Ihre eigene handgezeichnete Nummer verwenden möchten, können Sie mit einem Grafikeditor ein eigenes 28 x 28 Pixel großes Bild einer Ziffer erstellen. Andernfalls können Sie mit + curl + das folgende Beispiel-Testbild auf Ihren Server oder Computer herunterladen:
curl -O https://raw.githubusercontent.com/do-community/tensorflow-digit-recognition/master/test_img.pngÖffnen Sie die Datei + main.py + in Ihrem Editor und fügen Sie die folgenden Codezeilen oben in die Datei ein, um zwei für die Bildbearbeitung erforderliche Bibliotheken zu importieren.
main.py
import numpy as np
from PIL import Image
...Fügen Sie dann am Ende der Datei die folgende Codezeile hinzu, um das Testbild der handgeschriebenen Ziffer zu laden:
main.py
...
img = np.invert(Image.open("test_img.png").convert('L')).ravel()Die Funktion "+ open " der Bibliothek " Image +" lädt das Testbild als 4D-Array, das die drei RGB-Farbkanäle und die Alpha-Transparenz enthält. Dies ist nicht dieselbe Darstellung, die wir zuvor beim Einlesen des Datensatzes mit TensorFlow verwendet haben. Daher müssen wir einige zusätzliche Arbeiten durchführen, um das Format anzupassen.
Zuerst verwenden wir die Funktion + convert + mit dem Parameter + L +, um die 4D RGBA-Darstellung auf einen Graustufen-Farbkanal zu reduzieren. Wir speichern dies als "+ numpy " - Array und invertieren es mit " np.invert ", da die aktuelle Matrix Schwarz als 0 und Weiß als 255 darstellt, während wir das Gegenteil benötigen. Schließlich rufen wir " ravel +" auf, um das Array zu reduzieren.
Da die Bilddaten nun korrekt strukturiert sind, können wir eine Sitzung auf die gleiche Weise wie zuvor ausführen, aber diesmal nur das einzelne Bild zum Testen einspeisen.
Fügen Sie der Datei den folgenden Code hinzu, um das Bild zu testen und das ausgegebene Etikett zu drucken.
main.py
...
prediction = sess.run(tf.argmax(output_layer, 1), feed_dict={X: [img]})
print ("Prediction for test image:", np.squeeze(prediction))Die Funktion "+ np.squeeze +" wird für die Vorhersage aufgerufen, um die einzelne Ganzzahl aus dem Array zurückzugeben (d. H. von [2] nach 2) gehen. Die resultierende Ausgabe zeigt, dass das Netzwerk dieses Bild als Ziffer 2 erkannt hat.
OutputPrediction for test image: 2Sie können versuchen, das Netzwerk mit komplexeren Bildern zu testen - beispielsweise Ziffern, die anderen Ziffern ähneln oder die schlecht oder falsch gezeichnet wurden -, um festzustellen, wie gut sie abschneiden.
Fazit
In diesem Lernprogramm haben Sie ein neuronales Netzwerk erfolgreich darauf trainiert, den MNIST-Datensatz mit einer Genauigkeit von ca. 92% zu klassifizieren und auf einem eigenen Bild zu testen. Aktuelle Forschungen auf dem neuesten Stand der Technik erreichen in Bezug auf dasselbe Problem etwa 99%, wenn komplexere Netzwerkarchitekturen mit Faltungsschichten verwendet werden. Diese verwenden die 2D-Struktur des Bildes, um den Inhalt besser darzustellen, im Gegensatz zu unserer Methode, bei der alle Pixel zu einem Vektor von 784 Einheiten abgeflacht wurden. Weitere Informationen zu diesem Thema finden Sie auf der TensorFlow-Website und in den Forschungsberichten unter http: // yann .lecun.com / exdb / mnist / [MNIST-Website].
Nachdem Sie nun wissen, wie Sie ein neuronales Netzwerk aufbauen und trainieren, können Sie versuchen, diese Implementierung für Ihre eigenen Daten zu verwenden, oder sie in anderen gängigen Datensätzen wie Google StreetView testen Hausnummern oder den Datensatz CIFAR-10 für eine allgemeinere Bilderkennung.