Der Autor hat Girls Who Code ausgewählt, um eine Spende im Rahmen des Programms Write for DOnations zu erhalten .
Einführung
Keras ist eine in Python geschriebene neuronale Netzwerk-API. Es wird über TensorFlow, CNTK oder http://deeplearning.net/ ausgeführt. Software / Theano / [Theano]. Es ist eine Abstraktion auf hoher Ebene dieser Deep-Learning-Frameworks und macht daher das Experimentieren schneller und einfacher. Keras ist modular, was bedeutet, dass die Implementierung nahtlos ist, da Entwickler Modelle schnell durch Hinzufügen von Modulen erweitern können.
TensorFlow ist eine Open-Source-Softwarebibliothek für maschinelles Lernen. Es funktioniert effizient bei der Berechnung mit Arrays. Daher ist es eine gute Wahl für das Modell, das Sie in diesem Lernprogramm erstellen. Außerdem ermöglicht TensorFlow die Ausführung von Code entweder auf der CPU oder der GPU. Dies ist eine nützliche Funktion, insbesondere wenn Sie mit einem riesigen Datensatz arbeiten.
In diesem Lernprogramm erstellen Sie ein Deep-Learning-Modell, mit dem die Wahrscheinlichkeit vorhergesagt wird, mit der ein Mitarbeiter ein Unternehmen verlässt. Die Bindung der besten Mitarbeiter ist für die meisten Unternehmen ein wichtiger Faktor. Um Ihr Modell zu erstellen, verwenden Sie dieses bei Kaggle verfügbare Dataset, das Funktionen zur Messung der Mitarbeiterzufriedenheit in einem Unternehmen enthält. Um dieses Modell zu erstellen, verwenden Sie die Keras-Ebene sequential, um die verschiedenen Ebenen für das Modell zu erstellen.
Voraussetzungen
Bevor Sie mit diesem Lernprogramm beginnen, benötigen Sie Folgendes:
-
Eine Anaconda-Entwicklungsumgebung auf Ihrem Computer.
-
Eine Installation von Jupyter Notebook. Anaconda installiert Jupyter Notebook während der Installation für Sie. In diesem Tutorial finden Sie auch eine Anleitung zur Navigation und Verwendung von Jupyter Notebook.
-
Vertrautheit mit Maschinenlernen.
Schritt 1 - Datenvorverarbeitung
Datenvorverarbeitung ist erforderlich, um Ihre Daten so aufzubereiten, dass sie von einem Deep-Learning-Modell akzeptiert werden. Wenn Ihre Daten kategoriale Variablen enthalten, müssen Sie diese in Zahlen konvertieren, da der Algorithmus nur numerische Zahlen akzeptiert. Eine kategoriale Variable repräsentiert quantitative Daten, die durch Namen dargestellt werden. In diesem Schritt laden Sie Ihr Dataset mit "+ pandas +", einer Python-Bibliothek zur Datenmanipulation.
Bevor Sie mit der Datenvorverarbeitung beginnen, aktivieren Sie Ihre Umgebung und stellen sicher, dass alle erforderlichen Pakete auf Ihrem Computer installiert sind. Es ist vorteilhaft, "+ conda " zu verwenden, um " keras " und " tensorflow " zu installieren, da alle erforderlichen Abhängigkeiten für diese Pakete installiert werden und sichergestellt wird, dass sie mit " keras " und " tensorflow +" kompatibel sind. Auf diese Weise ist die Verwendung der Anaconda Python-Distribution eine gute Wahl für datenwissenschaftliche Projekte.
Wechseln Sie in die Umgebung, die Sie im vorausgesetzten Lernprogramm erstellt haben:
conda activateFühren Sie den folgenden Befehl aus, um "+ keras " und " tensorflow +" zu installieren:
conda install tensorflow kerasÖffnen Sie jetzt Jupyter Notebook, um zu beginnen. Jupyter Notebook wird durch Eingabe des folgenden Befehls auf Ihrem Terminal geöffnet:
jupyter notebookKlicken Sie nach dem Zugriff auf Jupyter Notebook auf die * anaconda3 * -Datei und dann oben auf dem Bildschirm auf * Neu *, und wählen Sie * Python 3 * aus, um ein neues Notebook zu laden.
Jetzt importieren Sie die erforderlichen Module für das Projekt und laden den Datensatz in eine Notebook-Zelle. Sie laden das "+ pandas " - Modul zum Bearbeiten Ihrer Daten und " numpy " zum Konvertieren der Daten in " numpy +" - Arrays. Sie konvertieren auch alle Spalten im Zeichenfolgenformat in numerische Werte, die Ihr Computer verarbeiten soll.
Fügen Sie den folgenden Code in eine Notebook-Zelle ein und klicken Sie auf "Ausführen":
import pandas as pd
import numpy as np
df = pd.read_csv("https://raw.githubusercontent.com/mwitiderrick/kerasDO/master/HR_comma_sep.csv")Sie haben + numpy und` + pandas` importiert. Sie haben dann "+ pandas +" verwendet, um den Datensatz für das Modell zu laden.
Mit + head () + können Sie einen Blick auf das Dataset werfen, mit dem Sie arbeiten. Dies ist eine nützliche Funktion von "+ pandas +", mit der Sie die ersten fünf Datensätze Ihres Datenrahmens anzeigen können. Fügen Sie einer Notebook-Zelle den folgenden Code hinzu und führen Sie ihn aus:
df.head()image: https: //assets.digitalocean.com/articles/deeplearningkeras/step1a.png [Alt Kopf auf Datensatz prüfen]
Nun konvertieren Sie die kategorialen Spalten in Zahlen. Sie tun dies, indem Sie sie in Dummy-Variablen konvertieren. Dummy-Variablen sind normalerweise Einsen und Nullen, die das Vorhandensein oder Fehlen eines kategorialen Merkmals anzeigen. In einer solchen Situation können Sie auch die Dummy-Variablenfalle umgehen, indem Sie den ersten Dummy löschen.
Fügen Sie diesen Code in die nächste Notebook-Zelle ein und führen Sie ihn aus:
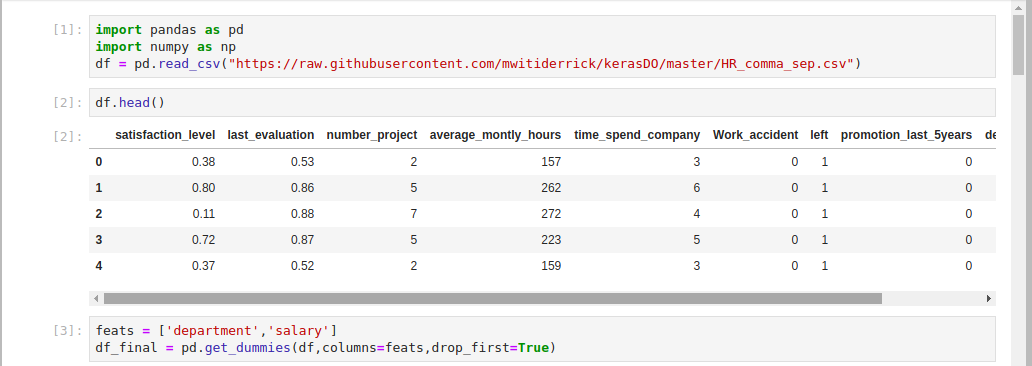
feats = ['department','salary']
df_final = pd.get_dummies(df,columns=feats,drop_first=True)+ feats = ['department', 'salary'] + definiert die beiden Spalten, für die Sie Dummy-Variablen erstellen möchten. + pd.get_dummies (df, columns = feats, drop_first = True) + generiert die numerischen Variablen, die Ihr Mitarbeiterbindungsmodell benötigt. Dazu konvertieren Sie die von Ihnen definierten "+ feats +" von kategorialen in numerische Variablen.
Bild: https://assets.digitalocean.com/articles/deeplearningkeras/step1b.png [Schritt 1]
{kind=link}
Sie haben den Datensatz geladen und die Spalten "Gehalt" und "Abteilung" in ein Format konvertiert, das das Deep-Learning-Modell "+ keras +" akzeptieren kann. Im nächsten Schritt teilen Sie den Datensatz in einen Trainings- und Testsatz auf.
Schritt 2 - Trennen der Trainings- und Testdatensätze
Sie werden https://scikit-learn.org/ [+ scikit-learn +] verwenden, um Ihren Datensatz in einen Trainings- und einen Testsatz aufzuteilen. Dies ist erforderlich, damit Sie einen Teil der Mitarbeiterdaten zum Trainieren des Modells und einen Teil zum Testen seiner Leistung verwenden können. Das Aufteilen eines Datensatzes auf diese Weise ist beim Erstellen von Deep-Learning-Modellen üblich.
Es ist wichtig, diese Aufteilung im Datensatz zu implementieren, damit das von Ihnen erstellte Modell während des Trainingsprozesses keinen Zugriff auf die Testdaten hat. Dadurch wird sichergestellt, dass das Modell nur aus den Trainingsdaten lernt, und Sie können dann seine Leistung mit den Testdaten testen. Wenn Sie Ihr Modell während des Trainings einem Datentest aussetzen, werden die erwarteten Ergebnisse gespeichert. Infolgedessen würde es keine genauen Vorhersagen für Daten geben, die es nicht gesehen hat.
Sie importieren zunächst das Modul "+ train_test_split " aus dem Paket " scikit-learn +". Dies ist das Modul, das die Aufteilungsfunktion bereitstellt. Fügen Sie diesen Code in die nächste Notebook-Zelle ein und führen Sie Folgendes aus:
from sklearn.model_selection import train_test_splitWenn das Modul "+ train_test_split " importiert ist, verwenden Sie die Spalte " left " in Ihrem Datensatz, um vorherzusagen, ob ein Mitarbeiter das Unternehmen verlässt. Daher ist es wichtig, dass Ihr Deep Learning-Modell nicht mit dieser Spalte in Kontakt kommt. Fügen Sie Folgendes in eine Zelle ein, um die Spalte ` left +` abzulegen:
X = df_final.drop(['left'],axis=1).values
y = df_final['left'].valuesIhr Deep Learning-Modell erwartet, dass die Daten als Arrays abgerufen werden. Daher verwenden Sie http://www.numpy.org/ [+ numpy +], um die Daten in + numpy + - Arrays mit dem Attribut + .values + zu konvertieren.
Jetzt können Sie den Datensatz in einen Test- und Trainingssatz umwandeln. Sie verwenden 70% der Daten für Schulungen und 30% für Tests. Das Trainingsverhältnis ist mehr als das Testverhältnis, da Sie die meisten Daten für den Trainingsprozess verwenden müssen. Auf Wunsch können Sie auch mit einem Verhältnis von 80% für das Trainingsset und 20% für das Testset experimentieren.
Fügen Sie nun diesen Code in die nächste Zelle ein und führen Sie den Befehl aus, um Ihre Trainings- und Testdaten auf das angegebene Verhältnis aufzuteilen:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)image: https://assets.digitalocean.com/articles/deeplearningkeras/step2.png [Schritt 2]
{kind=link}
Sie haben die Daten nun in den Typ konvertiert, den Keras erwartet (+ numpy + Arrays), und Ihre Daten werden in ein Trainings- und Test-Set aufgeteilt. Sie werden diese Daten später im Lernprogramm an das Modell "+ keras +" übergeben. Zuvor müssen Sie die Daten transformieren, die Sie im nächsten Schritt vervollständigen werden.
Schritt 3 - Transformieren der Daten
Beim Erstellen von Deep-Learning-Modellen empfiehlt es sich in der Regel, den Datensatz zu skalieren, um die Berechnungen effizienter zu gestalten. In diesem Schritt skalieren Sie die Daten mit dem "+ StandardScaler ". Dadurch wird sichergestellt, dass Ihre Datensatzwerte einen Mittelwert von Null und eine Einheitsvariable haben. Dies transformiert den Datensatz so, dass er normal verteilt wird. Mit dem " scikit-learn +" + StandardScaler + "skalieren Sie die Funktionen so, dass sie im selben Bereich liegen. Dadurch werden die Werte so transformiert, dass sie einen Mittelwert von 0 und eine Standardabweichung von 1 haben. Dieser Schritt ist wichtig, da Sie Features mit unterschiedlichen Abmessungen vergleichen. Daher ist dies normalerweise beim maschinellen Lernen erforderlich.
Fügen Sie zum Skalieren des Trainingssatzes und des Testsatzes diesen Code zur Notebook-Zelle hinzu und führen Sie ihn aus:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)Hier importieren Sie zunächst den + StandardScaler + und rufen eine Instanz davon auf. Anschließend skalieren Sie den Trainings- und Testsatz mit der Methode "+ fit_transform +".
Sie haben alle Dataset-Features so skaliert, dass sie im selben Bereich liegen. Im nächsten Schritt können Sie mit dem Aufbau des künstlichen neuronalen Netzwerks beginnen.
Schritt 4 - Aufbau des künstlichen neuronalen Netzwerks
Jetzt verwenden Sie "+ keras ", um das Deep Learning-Modell zu erstellen. Dazu importieren Sie " Keras ", wobei " Tensorflow " standardmäßig als Backend verwendet wird. Aus " keras " importieren Sie dann das " Sequential " - Modul, um das künstliche neuronale Netzwerk zu initialisieren. Ein künstliches neuronales Netzwerk ist ein Rechenmodell, das auf der Grundlage der Funktionsweise des menschlichen Gehirns erstellt wird. Sie importieren auch das ` Dense +` - Modul, das Ihrem Deep Learning-Modell Ebenen hinzufügt.
Beim Erstellen eines Deep-Learning-Modells geben Sie normalerweise drei Ebenentypen an:
-
Der Eingabe-Layer ist der Layer, an den Sie die Features Ihres Datasets übergeben. In dieser Ebene findet keine Berechnung statt. Es dient dazu, Features an die ausgeblendeten Ebenen weiterzuleiten.
-
Die versteckten Ebenen sind normalerweise die Ebenen zwischen der Eingabeebene und der Ausgabeebene - und es kann mehr als eine geben. Diese Ebenen führen die Berechnungen durch und leiten die Informationen an die Ausgabeebene weiter.
-
Die Ausgabeschicht stellt die Schicht Ihres neuronalen Netzwerks dar, die Ihnen die Ergebnisse nach dem Training Ihres Modells liefert. Es ist für die Erzeugung der Ausgabevariablen verantwortlich.
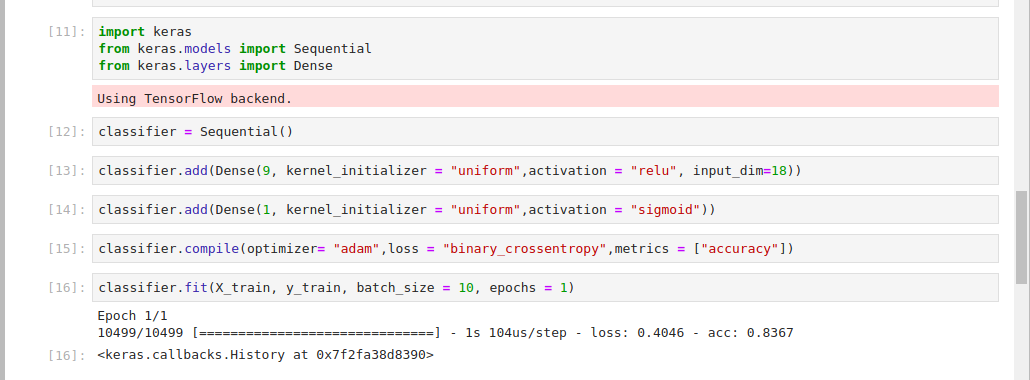
Führen Sie den folgenden Code in Ihrer Notebook-Zelle aus, um die Module "+ Keras ", " Sequential " und " Dense +" zu importieren:
import keras
from keras.models import Sequential
from keras.layers import DenseSie verwenden "+ Sequential +", um einen linearen Stapel von Ebenen zu initialisieren. Da dies ein Klassifizierungsproblem ist, erstellen Sie eine Klassifizierungsvariable. Ein Klassifizierungsproblem ist eine Aufgabe, bei der Sie Daten beschriftet haben und anhand der beschrifteten Daten einige Vorhersagen treffen möchten. Fügen Sie diesen Code zu Ihrem Notizbuch hinzu, um eine Klassifikatorvariable zu erstellen:
classifier = Sequential()Sie haben + Sequential + verwendet, um den Klassifikator zu initialisieren.
Jetzt können Sie Ihrem Netzwerk Ebenen hinzufügen. Führen Sie diesen Code in Ihrer nächsten Zelle aus:
classifier.add(Dense(9, kernel_initializer = "uniform",activation = "relu", input_dim=18))Sie fügen Layer mit der Funktion + .add () + in Ihrem Klassifikator hinzu und geben einige Parameter an:
-
Der erste Parameter ist die Anzahl der Knoten, die Ihr Netzwerk haben sollte. Die Verbindung zwischen verschiedenen Knoten bildet das neuronale Netzwerk. Eine der Strategien zur Bestimmung der Anzahl der Knoten besteht darin, den Durchschnitt der Knoten in der Eingabe- und der Ausgabeebene zu ermitteln.
-
Der zweite Parameter ist der
+ kernel_initializer. +Wenn Sie Ihr Deep Learning-Modell anpassen, werden die Gewichte auf Zahlen nahe Null, aber nicht auf Null initialisiert. Um dies zu erreichen, verwenden Sie den Uniform Distribution Initializer.+ kernel_initializer +ist die Funktion, die die Gewichte initialisiert. -
Der dritte Parameter ist die Funktion "+ Aktivierung ". Ihr Deep Learning-Modell lernt durch diese Funktion. Es gibt normalerweise lineare und nichtlineare Aktivierungsfunktionen. Sie verwenden die Aktivierungsfunktion https://keras.io/activations/ [` relu +`], da sie Ihre Daten gut verallgemeinert. Lineare Funktionen eignen sich nicht für solche Probleme, da sie eine gerade Linie bilden.
-
Der letzte Parameter ist "+ input_dim +", der die Anzahl der Features in Ihrem Dataset darstellt.
Nun fügen Sie den Ausgabe-Layer hinzu, der Ihnen die Vorhersagen liefert:
classifier.add(Dense(1, kernel_initializer = "uniform",activation = "sigmoid"))Die Ausgabeebene akzeptiert die folgenden Parameter:
-
Die Anzahl der Ausgabeknoten. Sie erwarten eine Ausgabe: Wenn ein Mitarbeiter das Unternehmen verlässt. Daher geben Sie einen Ausgabeknoten an.
-
Für "+ kernel_initializer " verwenden Sie die Aktivierungsfunktion https://keras.io/activations/ [" sigmoid "], um die Wahrscheinlichkeit zu ermitteln, dass ein Mitarbeiter ausscheidet. Falls Sie mit mehr als zwei Kategorien zu tun haben, verwenden Sie die Aktivierungsfunktion https://keras.io/activations/ [` softmax `], eine Variante der Aktivierungsfunktion ` sigmoid +`.
Als Nächstes wenden Sie einen Gradientenabstieg auf das neuronale Netzwerk an. Dies ist eine Optimierungsstrategie, mit der Fehler während des Trainingsprozesses reduziert werden. Gradientenabfall ist, wie zufällig zugewiesene Gewichte in einem neuronalen Netzwerk durch Reduzieren der Kostenfunktion angepasst werden, die ein Maß für die Leistung eines neuronalen Netzwerks basierend auf der von ihm erwarteten Ausgabe ist.
Das Ziel eines Gefälleabstiegs ist es, den Punkt zu erreichen, an dem der Fehler am geringsten ist. Dies geschieht, indem ermittelt wird, wo die Kostenfunktion am Minimum ist, was als lokales Minimum bezeichnet wird. Beim Gefälle differenzieren Sie, um die Steigung an einem bestimmten Punkt zu ermitteln und festzustellen, ob die Steigung negativ oder positiv ist - Sie steigen in das Minimum der Kostenfunktion ab. Es gibt verschiedene Arten von Optimierungsstrategien. In diesem Lernprogramm verwenden Sie jedoch eine beliebte Strategie namens "+ adam +".
Fügen Sie diesen Code zu Ihrer Notebook-Zelle hinzu und führen Sie ihn aus:
classifier.compile(optimizer= "adam",loss = "binary_crossentropy",metrics = ["accuracy"])Das Anwenden des Gradientenabstiegs erfolgt über die Funktion + compile +, die die folgenden Parameter verwendet:
-
+ optimizer +ist der Gradientenabstieg. -
+ loss +ist eine Funktion, die Sie beim Gefälle verwenden werden. Da es sich um ein Binärklassifizierungsproblem handelt, verwenden Sie die Funktion+ binary_crossentropy`+ loss`. -
Der letzte Parameter ist die "+ Metrik +", mit der Sie Ihr Modell bewerten. In diesem Fall möchten Sie es anhand seiner Genauigkeit bewerten, wenn Sie Vorhersagen treffen.
Sie können Ihren Klassifikator nun an Ihren Datensatz anpassen. Keras macht dies mit der Methode + .fit () + möglich. Fügen Sie dazu den folgenden Code in Ihr Notizbuch ein und führen Sie ihn aus, um das Modell an Ihren Datensatz anzupassen:
classifier.fit(X_train, y_train, batch_size = 10, epochs = 1)image: https://assets.digitalocean.com/articles/deeplearningkeras/step4a.png [Anpassen des Datensatzes]
{kind=link}
Die Methode + .fit () + akzeptiert einige Parameter:
-
Der erste Parameter ist das Trainingsset mit den Funktionen.
-
Der zweite Parameter ist die Spalte, für die Sie die Vorhersagen treffen.
-
Das "+ batch_size +" steht für die Anzahl der Abtastwerte, die bei jeder Trainingsrunde durch das neuronale Netzwerk geleitet werden.
-
"+ Epochen +" gibt an, wie oft der Datensatz über das neuronale Netzwerk übertragen wird. Je mehr Epochen erforderlich sind, desto länger dauert die Ausführung Ihres Modells, wodurch Sie auch bessere Ergebnisse erzielen.
Bild: https://assets.digitalocean.com/articles/deeplearningkeras/step4b.png [Schritt 4]
{kind=link}
Sie haben Ihr Deep Learning-Modell erstellt, es kompiliert und an Ihren Datensatz angepasst. Sie sind bereit, mithilfe des Deep-Learning-Modells einige Vorhersagen zu treffen. Im nächsten Schritt werden Sie Vorhersagen mit dem Datensatz treffen, den das Modell noch nicht gesehen hat.
Schritt 5 - Ausführen von Vorhersagen auf dem Testset
Um Vorhersagen zu treffen, verwenden Sie das Test-Dataset in dem von Ihnen erstellten Modell. Mit Keras können Sie mithilfe der Funktion + .predict () + Vorhersagen treffen.
Fügen Sie den folgenden Code in die nächste Notizbuchzelle ein, um Vorhersagen zu treffen:
y_pred = classifier.predict(X_test)Da Sie den Klassifikator bereits mit dem Trainingssatz trainiert haben, verwendet dieser Code das Lernen aus dem Trainingsprozess, um Vorhersagen für den Testsatz zu treffen. Dies gibt Ihnen die Wahrscheinlichkeiten, mit denen ein Mitarbeiter ausscheidet. Sie arbeiten mit einer Wahrscheinlichkeit von 50% und mehr, um die hohe Wahrscheinlichkeit anzuzeigen, dass der Mitarbeiter das Unternehmen verlässt.
Geben Sie die folgende Codezeile in Ihre Notebook-Zelle ein, um diesen Schwellenwert festzulegen:
y_pred = (y_pred > 0.5)Sie haben mithilfe der Vorhersagemethode Vorhersagen erstellt und den Schwellenwert festgelegt, anhand dessen ermittelt wird, ob ein Mitarbeiter wahrscheinlich abreist. Um zu bewerten, wie gut das Modell die Vorhersagen erfüllt, verwenden Sie als Nächstes eine Confusionsmatrix.
Schritt 6 - Überprüfen der Verwirrungsmatrix
In diesem Schritt verwenden Sie eine Confusionsmatrix, um die Anzahl der richtigen und falschen Vorhersagen zu überprüfen. Eine Verwirrungsmatrix, auch als Fehlermatrix bezeichnet, ist eine quadratische Matrix, die die Anzahl der wahren (tp), falschen (fp), wahren (tn) und falschen (fn) Negativen eines Klassifikators angibt.
-
Ein * wahres positives * ist ein Ergebnis, bei dem das Modell die positive Klasse korrekt vorhersagt (auch bekannt als Sensitivität oder Erinnerung).
-
Ein * wahres Negativ * ist ein Ergebnis, bei dem das Modell die negative Klasse korrekt vorhersagt.
-
Ein * falsch positiv * ist ein Ergebnis, bei dem das Modell die positive Klasse falsch vorhersagt.
-
Ein * falsch negativ * ist ein Ergebnis, bei dem das Modell die negative Klasse falsch vorhersagt.
Um dies zu erreichen, verwenden Sie eine Verwirrungsmatrix, die von "+ scikit-learn +" bereitgestellt wird.
Fügen Sie diesen Code in die nächste Notizbuchzelle ein, um die Verwirrungsmatrix "+ scikit-learn +" zu importieren:
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
cmDie Ausgabe der Verwirrungsmatrix bedeutet, dass Ihr Deep-Learning-Modell "3305 + 375 +" korrekte Vorhersagen und "+106 + 714 +" falsche Vorhersagen gemacht hat. Sie können die Genauigkeit berechnen mit: ` (3305 + 375) / 4500 +`. Die Gesamtzahl der Beobachtungen in Ihrem Datensatz beträgt 4500. Dies ergibt eine Genauigkeit von 81,7%. Dies ist eine sehr gute Genauigkeitsrate, da Sie mit Ihrem Modell mindestens 81% korrekte Vorhersagen erzielen können.
Outputarray([, ],
[ , ]])Sie haben Ihr Modell anhand der Verwirrungsmatrix bewertet. Als Nächstes arbeiten Sie an einer einzelnen Vorhersage mit dem von Ihnen entwickelten Modell.
Schritt 7 - Eine einzelne Vorhersage machen
In diesem Schritt erstellen Sie eine einzelne Vorhersage mit den Details eines Mitarbeiters Ihres Modells. Sie erreichen dies, indem Sie die Wahrscheinlichkeit vorhersagen, mit der ein einzelner Mitarbeiter das Unternehmen verlässt. Sie übergeben die Funktionen dieses Mitarbeiters an die Methode "+ prognostizieren ". Wie zuvor skalieren Sie auch die Features und konvertieren sie in ein " numpy +" - Array.
Führen Sie den folgenden Code in einer Zelle aus, um die Funktionen des Mitarbeiters zu übergeben:
new_pred = classifier.predict(sc.transform(np.array([[0.26,0.7 ,3., 238., 6., 0.,0.,0.,0., 0.,0.,0.,0.,0.,1.,0., 0.,1.]])))Diese Funktionen repräsentieren die Funktionen eines einzelnen Mitarbeiters. Wie im Datensatz in Schritt 1 gezeigt, stellen diese Funktionen Folgendes dar: Zufriedenheitsgrad, letzte Bewertung, Anzahl der Projekte usw. Wie in Schritt 3 müssen Sie die Funktionen so transformieren, dass sie vom Deep Learning-Modell akzeptiert werden.
Fügen Sie einen Schwellenwert von 50% mit dem folgenden Code hinzu:
new_pred = (new_pred > 0.5)
new_predDieser Schwellenwert gibt an, dass ein Mitarbeiter bei einer Wahrscheinlichkeit von mehr als 50% das Unternehmen verlässt.
Sie können in Ihrer Ausgabe sehen, dass der Mitarbeiter das Unternehmen nicht verlässt:
Outputarray([[False]])Möglicherweise möchten Sie einen niedrigeren oder höheren Schwellenwert für Ihr Modell festlegen. Beispielsweise können Sie den Schwellenwert auf 60% festlegen:
new_pred = (new_pred > 0.6)
new_predDiese neue Schwelle zeigt weiterhin, dass der Mitarbeiter das Unternehmen nicht verlässt:
Outputarray([[False]])In diesem Schritt haben Sie gesehen, wie eine einzelne Vorhersage unter Berücksichtigung der Merkmale eines einzelnen Mitarbeiters erstellt wird. Im nächsten Schritt werden Sie daran arbeiten, die Genauigkeit Ihres Modells zu verbessern.
Schritt 8 - Verbesserung der Modellgenauigkeit
Wenn Sie Ihr Modell mehrmals trainieren, erhalten Sie immer wieder andere Ergebnisse. Die Genauigkeiten für jedes Training haben eine hohe Varianz. Um dieses Problem zu lösen, verwenden Sie die K-fache Kreuzvalidierung. Normalerweise wird K auf 10 gesetzt. Bei dieser Technik wird das Modell auf den ersten 9 Falten trainiert und auf der letzten Falte getestet. Diese Iteration wird fortgesetzt, bis alle Falten verwendet wurden. Jede der Iterationen gibt ihre eigene Genauigkeit. Die Genauigkeit des Modells wird zum Durchschnitt aller dieser Genauigkeiten.
Mit + keras + können Sie die K-fache Kreuzvalidierung über den Wrapper + KerasClassifier + implementieren. Dieser Wrapper stammt aus der Kreuzvalidierung von "+ scikit-learn ". Sie importieren zunächst die Funktion " cross_val_score " und den " KerasClassifier +". Fügen Sie dazu den folgenden Code in Ihre Notebook-Zelle ein und führen Sie ihn aus:
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import cross_val_scoreFügen Sie der nächsten Zelle den folgenden Code hinzu, um die Funktion zu erstellen, die Sie an den KerasClassifier übergeben:
def make_classifier():
classifier = Sequential()
classifier.add(Dense(9, kernel_initializer = "uniform", activation = "relu", input_dim=18))
classifier.add(Dense(1, kernel_initializer = "uniform", activation = "sigmoid"))
classifier.compile(optimizer= "adam",loss = "binary_crossentropy",metrics = ["accuracy"])
return classifierHier erstellen Sie eine Funktion, die Sie an "+ KerasClassifier " übergeben. Die Funktion ist eines der Argumente, die der Klassifizierer erwartet. Die Funktion ist ein Wrapper des neuronalen Netzwerkdesigns, das Sie zuvor verwendet haben. Die übergebenen Parameter ähneln denen, die zuvor im Lernprogramm verwendet wurden. In der Funktion initialisieren Sie zuerst den Klassifikator mit ` Sequential () ` und fügen dann mit ` Dense +` die Eingabe- und Ausgabeebene hinzu. Zum Schluss kompilieren Sie den Klassifikator und geben ihn zurück.
Fügen Sie Ihrem Notizbuch die folgende Codezeile hinzu, um die von Ihnen erstellte Funktion an "+ KerasClassifier +" zu übergeben:
classifier = KerasClassifier(build_fn = make_classifier, batch_size=10, nb_epoch=1)Der + KerasClassifier + akzeptiert drei Argumente:
-
+ build_fn +: die Funktion mit dem neuronalen Netzwerkdesign -
+ batch_size +: Die Anzahl der Proben, die in jeder Iteration über das Netzwerk übertragen werden sollen -
+ nb_epoch +: Die Anzahl der Epochen, in denen das Netzwerk ausgeführt wird
Als nächstes wenden Sie die Kreuzvalidierung mit Scikit-learn + cross_val_score an. Fügen Sie den folgenden Code zu Ihrer Notebook-Zelle hinzu und führen Sie ihn aus:
accuracies = cross_val_score(estimator = classifier,X = X_train,y = y_train,cv = 10,n_jobs = -1)Diese Funktion gibt Ihnen zehn Genauigkeiten, da Sie die Anzahl der Falten mit 10 angegeben haben. Daher weisen Sie es der Variablen "Genauigkeit" zu und verwenden es später, um die mittlere Genauigkeit zu berechnen. Es braucht die folgenden Argumente:
-
+ Estimator +: Der Klassifikator, den Sie gerade definiert haben -
+ X +: Die Funktionen des Trainingssatzes -
+ y +: Der im Trainingssatz vorherzusagende Wert -
+ cv +: die Anzahl der Falten -
+ n_jobs +: die Anzahl der zu verwendenden CPUs (bei Angabe von -1 werden alle verfügbaren CPUs verwendet)
Nachdem Sie die Kreuzvalidierung angewendet haben, können Sie den Mittelwert und die Varianz der Genauigkeiten berechnen. Fügen Sie dazu den folgenden Code in Ihr Notizbuch ein:
mean = accuracies.mean()
meanIn Ihrer Ausgabe sehen Sie, dass der Mittelwert 83% beträgt:
OutputUm die Varianz der Genauigkeiten zu berechnen, fügen Sie diesen Code in die nächste Notizbuchzelle ein:
variance = accuracies.var()
varianceSie sehen, dass die Varianz 0,00109 beträgt. Da die Varianz sehr gering ist, bedeutet dies, dass Ihr Modell eine sehr gute Leistung erbringt.
OutputSie haben die Genauigkeit Ihres Modells durch die Verwendung der K-Fold-Kreuzvalidierung verbessert. Im nächsten Schritt werden Sie das Problem der Überanpassung beheben.
Schritt 9 - Hinzufügen einer Dropout-Regularisierung zur Bekämpfung von Überanpassung
Vorhersagemodelle sind anfällig für ein Problem, das als Überanpassung bekannt ist. In diesem Szenario speichert das Modell die Ergebnisse im Trainingssatz und kann keine Verallgemeinerung der Daten vornehmen, die es nicht gesehen hat. In der Regel stellen Sie eine Überanpassung fest, wenn die Genauigkeit sehr unterschiedlich ist. Um Überanpassung in Ihrem Modell zu vermeiden, fügen Sie Ihrem Modell eine Ebene hinzu.
In neuronalen Netzen ist die Dropout-Regularisierung die Technik, die der Überanpassung entgegenwirkt, indem Sie Ihrem neuronalen Netz eine "+ Dropout " - Ebene hinzufügen. Der Parameter " rate +" gibt die Anzahl der Neuronen an, die bei jeder Iteration deaktiviert werden. Das Deaktivieren von Neruronen erfolgt normalerweise zufällig. In diesem Fall geben Sie 0,1 als Rate an, was bedeutet, dass 1% der Neuronen während des Trainings deaktiviert werden. Das Netzwerkdesign bleibt unverändert.
Fügen Sie der nächsten Zelle den folgenden Code hinzu, um die Ebene "+ Dropout +" hinzuzufügen:
from keras.layers import Dropout
classifier = Sequential()
classifier.add(Dense(9, kernel_initializer = "uniform", activation = "relu", input_dim=18))
classifier.add(Dropout(rate = 0.1))
classifier.add(Dense(1, kernel_initializer = "uniform", activation = "sigmoid"))
classifier.compile(optimizer= "adam",loss = "binary_crossentropy",metrics = ["accuracy"])Sie haben eine "+ Dropout " - Ebene zwischen der Eingabe- und der Ausgabeebene hinzugefügt. Wenn Sie eine Abbrecherquote von 0,1 eingestellt haben, werden 15 Neuronen während des Trainings deaktiviert, damit der Klassifikator das Trainingsset nicht überfordert. Nachdem Sie die Ebenen " Dropout +" und "Output" hinzugefügt haben, haben Sie den Klassifikator wie zuvor kompiliert.
Sie haben in diesem Schritt versucht, Überanpassung mit einer Ebene "+ Dropout +" zu bekämpfen. Als Nächstes arbeiten Sie daran, das Modell weiter zu verbessern, indem Sie die Parameter anpassen, die Sie beim Erstellen des Modells verwendet haben.
Schritt 10 - Hyperparameter-Tuning
Die Grid-Suche ist eine Technik, mit der Sie mit verschiedenen Modellparametern experimentieren können, um diejenigen zu erhalten, die Ihnen die beste Genauigkeit bieten. Bei dieser Technik werden verschiedene Parameter ausprobiert und diejenigen zurückgegeben, die die besten Ergebnisse liefern. Mithilfe der Rastersuche suchen Sie nach den besten Parametern für Ihr Deep Learning-Modell. Dies hilft bei der Verbesserung der Modellgenauigkeit. + scikit-learn + bietet die Funktion + GridSearchCV +, um diese Funktionalität zu aktivieren. Sie werden nun die Funktion + make_classifier + ändern, um verschiedene Parameter auszuprobieren.
Fügen Sie diesen Code zu Ihrem Notizbuch hinzu, um die Funktion + make_classifier + zu ändern, sodass Sie verschiedene Optimierungsfunktionen testen können:
from sklearn.model_selection import GridSearchCV
def make_classifier(optimizer):
classifier = Sequential()
classifier.add(Dense(9, kernel_initializer = "uniform", activation = "relu", input_dim=18))
classifier.add(Dense(1, kernel_initializer = "uniform", activation = "sigmoid"))
classifier.compile(optimizer= optimizer,loss = "binary_crossentropy",metrics = ["accuracy"])
return classifierSie haben mit dem Importieren von + GridSearchCV + begonnen. Sie haben dann Änderungen an der Funktion "+ make_classifier +" vorgenommen, damit Sie verschiedene Optimierer ausprobieren können. Sie haben den Klassifizierer initialisiert, die Eingabe- und Ausgabeebene hinzugefügt und dann den Klassifizierer kompiliert. Schließlich haben Sie den Klassifikator zurückgegeben, damit Sie ihn verwenden können.
Fügen Sie wie in Schritt 4 diese Codezeile ein, um den Klassifizierer zu definieren:
classifier = KerasClassifier(build_fn = make_classifier)Sie haben den Klassifizierer mit "+ KerasClassifier " definiert, der eine Funktion über den Parameter " build_fn +" erwartet. Sie haben den KerasClassifier aufgerufen und die Funktion make_classifier übergeben, die Sie zuvor erstellt haben.
Sie werden nun einige Parameter einstellen, mit denen Sie experimentieren möchten. Geben Sie diesen Code in eine Zelle ein und führen Sie Folgendes aus:
params = {
'batch_size':[20,35],
'epochs':[2,3],
'optimizer':['adam','rmsprop']
}Hier haben Sie verschiedene Stapelgrößen, Anzahl der Epochen und verschiedene Arten von Optimierungsfunktionen hinzugefügt.
Für einen kleinen Datensatz wie Ihren ist eine Stapelgröße zwischen 20 und 35 gut. Für große Datenmengen ist es wichtig, mit größeren Chargengrößen zu experimentieren. Durch die Verwendung von niedrigen Zahlen für die Anzahl der Epochen wird sichergestellt, dass Sie innerhalb kurzer Zeit Ergebnisse erzielen. Sie können jedoch mit größeren Zahlen experimentieren, die je nach Verarbeitungsgeschwindigkeit Ihres Servers eine Weile dauern. Die Optimierer "+ adam " und " rmsprop " von " keras +" sind eine gute Wahl für diese Art von neuronalen Netzwerken.
Nun werden Sie die verschiedenen von Ihnen definierten Parameter verwenden, um mit der Funktion "+ GridSearchCV +" nach den besten Parametern zu suchen. Geben Sie dies in die nächste Zelle ein und führen Sie es aus:
grid_search = GridSearchCV(estimator=classifier,
param_grid=params,
scoring="accuracy",
cv=2)Die Rastersuchfunktion erwartet folgende Parameter:
-
+ Estimator +: Der von Ihnen verwendete Klassifikator. -
+ param_grid +: Der Parametersatz, den Sie testen möchten. -
+ Bewertung +: Die von Ihnen verwendete Metrik. -
+ cv +: Die Anzahl der Falten, die Sie testen möchten.
Als nächstes passen Sie dieses + grid_search + an Ihren Trainingsdatensatz an:
grid_search = grid_search.fit(X_train,y_train)Ihre Ausgabe sieht ungefähr so aus: Warten Sie einen Moment, bis sie abgeschlossen ist.
OutputEpoch 1/2
5249/5249 [==============================] - 1s 228us/step - loss: 0.5958 - acc: 0.7645
Epoch 2/2
5249/5249 [==============================] - 0s 82us/step - loss: 0.3962 - acc: 0.8510
Epoch 1/2
5250/5250 [==============================] - 1s 222us/step - loss: 0.5935 - acc: 0.7596
Epoch 2/2
5250/5250 [==============================] - 0s 85us/step - loss: 0.4080 - acc: 0.8029
Epoch 1/2
5249/5249 [==============================] - 1s 214us/step - loss: 0.5929 - acc: 0.7676
Epoch 2/2
5249/5249 [==============================] - 0s 82us/step - loss: 0.4261 - acc: 0.7864Fügen Sie einer Notebook-Zelle den folgenden Code hinzu, um die besten Parameter aus dieser Suche mit dem Attribut + best_params_ + zu erhalten:
best_param = grid_search.best_params_
best_accuracy = grid_search.best_score_Sie können jetzt die besten Parameter für Ihr Modell mit dem folgenden Code überprüfen:
best_paramIhre Ausgabe zeigt, dass die beste Stapelgröße "+ 20 " ist, die beste Anzahl von Epochen " 2 " ist und der Optimierer " adam +" für Ihr Modell am besten geeignet ist:
Output{'batch_size': 20, 'epochs': 2, 'optimizer': 'adam'}Sie können die beste Genauigkeit für Ihr Modell überprüfen. Die "+ beste Genauigkeitszahl" steht für die höchste Genauigkeit, die Sie mit den besten Parametern nach dem Ausführen der Rastersuche erhalten:
best_accuracyIhre Ausgabe sieht ungefähr so aus:
OutputSie haben "+ GridSearch " verwendet, um die besten Parameter für Ihren Klassifikator zu ermitteln. Sie haben gesehen, dass das beste ` batch_size ` 20 ist, das beste ` optimizer ` das ` adam +` optimizer und die beste Anzahl von Epochen 2 ist. Sie haben auch die beste Genauigkeit für Ihren Klassifikator mit 85% erhalten. Sie haben ein Mitarbeiterbindungsmodell erstellt, das mit einer Genauigkeit von bis zu 85% vorhersagt, ob ein Mitarbeiter bleibt oder geht.
Fazit
In diesem Lernprogramm haben Sie https://keras.io [Keras] verwendet, um ein künstliches neuronales Netzwerk aufzubauen, das die Wahrscheinlichkeit vorhersagt, mit der ein Mitarbeiter ein Unternehmen verlässt. Sie haben Ihre Vorkenntnisse im maschinellen Lernen mit + scikit-learn + kombiniert, um dies zu erreichen. Um Ihr Modell weiter zu verbessern, können Sie verschiedene activation functions oder optimizer functions von + keras + ausprobieren. Sie können auch mit einer anderen Anzahl von Falten experimentieren oder sogar ein Modell mit einem anderen Datensatz erstellen.
Für andere Tutorials auf dem Gebiet des maschinellen Lernens oder mit TensorFlow können Sie versuchen, eine https://www.digitalocean.com/community/tutorials/hilfe zum Erstellen eines Netzwerks zum Erkennen von handgeschriebenen Ziffern zu erstellen -with-tensorflow [Neuronales Netz zum Erkennen handgeschriebener Ziffern] oder andere DigitalOcean-Lernprogramme (https://www.digitalocean.com/community/tags/machine-learning/tutorials[machine learning tutorials).