Der Autor hat Girls Who Code ausgewählt, um eine Spende im Rahmen des Programms Write for DOnations zu erhalten .
Einführung
Computer Vision ist ein Teilgebiet der Informatik, das darauf abzielt, aus Bildern und Videos ein Verständnis höherer Ordnung zu gewinnen. Dieses Feld enthält Aufgaben wie Objekterkennung, Bildwiederherstellung (Matrixvervollständigung) und optischer Fluss. Computer Vision unterstützt Technologien wie selbstfahrende Auto-Prototypen, Lebensmittelgeschäfte ohne Mitarbeiter, unterhaltsame Snapchat-Filter und die Gesichtserkennung Ihres Mobilgeräts.
In diesem Tutorial lernen Sie das Computer-Sehen kennen, indem Sie vorab trainierte Modelle verwenden, um einen Snapchat-ähnlichen Hundefilter zu erstellen. Für diejenigen, die nicht mit Snapchat vertraut sind, erkennt dieser Filter Ihr Gesicht und überlagert es mit einer Hundemaske. Anschließend trainieren Sie einen Gesichts-Emotions-Klassifikator, damit der Filter Hundemasken basierend auf Emotionen auswählen kann, z. B. einen Corgi für glücklich oder einen Mops für traurig. Auf dem Weg dorthin werden Sie auch verwandte Konzepte sowohl im Bereich der kleinsten Quadrate als auch im Bereich der Bildverarbeitung untersuchen, die Sie mit den Grundlagen des maschinellen Lernens vertraut machen.
Bild: https://assets.digitalocean.com/articles/python3_dogfilter/Hf5RDn3.gif [Ein funktionierender Hundefilter]
{kind=link}
Während Sie das Tutorial durcharbeiten, verwenden Sie "+ OpenCV ", eine Computer-Vision-Bibliothek, " numpy " für Dienstprogramme zur linearen Algebra und " matplotlib +" zum Plotten. Sie wenden beim Erstellen einer Computer-Vision-Anwendung auch die folgenden Konzepte an:
-
Ordentliche kleinste Quadrate als Regressions- und Klassifikationstechnik.
-
Die Grundlagen der stochastischen Neuralnetze mit Gradienten.
Dieses Lernprogramm ist nicht unbedingt erforderlich, aber Sie werden einige der detaillierteren Erklärungen leichter verstehen, wenn Sie mit den folgenden mathematischen Konzepten vertraut sind:
-
Grundlegende lineare Algebra-Konzepte: Skalare, Vektoren und Matrizen.
-
Grundrechnung: Wie man eine Ableitung nimmt.
Den vollständigen Code für dieses Tutorial finden Sie unter https://github.com/do-community/emotion-based-dog-filter.
Lass uns anfangen.
Voraussetzungen
Um dieses Tutorial abzuschließen, benötigen Sie Folgendes:
-
Eine lokale Entwicklungsumgebung für Python 3 mit mindestens 1 GB RAM. Sie können Installation und Einrichtung a Lokale Programmierumgebung für Python 3, um alles zu konfigurieren, was Sie benötigen.
-
Eine funktionierende Webcam zur Echtzeit-Bilderkennung.
Schritt 1 - Projekt erstellen und Abhängigkeiten installieren
Erstellen wir einen Arbeitsbereich für dieses Projekt und installieren die Abhängigkeiten, die wir benötigen. Wir nennen unseren Arbeitsbereich "+ DogFilter +":
mkdir ~/DogFilterNavigieren Sie zum Verzeichnis + DogFilter +:
cd ~/DogFilterErstellen Sie dann eine neue virtuelle Python-Umgebung für das Projekt:
python3 -m venvAktivieren Sie Ihre Umgebung.
source /bin/activateDie Eingabeaufforderung ändert sich und zeigt an, dass die Umgebung aktiv ist. Installieren Sie jetzt PyTorch, ein Deep-Learning-Framework für Python, das wir in diesem Lernprogramm verwenden werden. Der Installationsvorgang hängt vom verwendeten Betriebssystem ab.
Installieren Sie unter macOS Pytorch mit dem folgenden Befehl:
python -m pip install torch== torchvision==Verwenden Sie unter Linux die folgenden Befehle:
pip install http://download.pytorch.org/whl/cpu/torch--cp35-cp35m-.whl
pip install torchvisionInstallieren Sie unter Windows Pytorch mit den folgenden Befehlen:
pip install http://download.pytorch.org/whl/cpu/torch--cp35-cp35m-.whl
pip install torchvisionInstallieren Sie nun vorgefertigte Binärdateien für "+ OpenCV " und " numpy +", die Computer Vision- bzw. lineare Algebra-Bibliotheken sind. Ersteres bietet Hilfsprogramme wie Bilddrehungen, und letzteres bietet Hilfsprogramme für lineare Algebra wie eine Matrixinversion.
python -m pip install opencv-python== numpy==Erstellen Sie schließlich ein Verzeichnis für unsere Assets, in dem die Bilder gespeichert werden, die wir in diesem Lernprogramm verwenden:
mkdir assetsErstellen wir mit den installierten Abhängigkeiten die erste Version unseres Filters: einen Gesichtsdetektor.
Schritt 2 - Aufbau eines Gesichtsdetektors
Unser erstes Ziel ist es, alle Gesichter in einem Bild zu erkennen. Wir erstellen ein Skript, das ein einzelnes Bild akzeptiert und ein mit Anmerkungen versehenes Bild mit den durch Kästchen umrandeten Gesichtern ausgibt.
Glücklicherweise können wir anstelle unserer eigenen Gesichtserkennungslogik vorgeübte Modelle verwenden. Wir richten ein Modell ein und laden dann vorab trainierte Parameter. OpenCV macht dies einfach, indem es beides bietet.
OpenCV stellt die Modellparameter in seinem Quellcode bereit. Für die Verwendung dieser Parameter benötigen wir jedoch den absoluten Pfad zu unserem lokal installierten OpenCV. Da dieser absolute Pfad variieren kann, laden wir stattdessen unsere eigene Kopie herunter und platzieren sie im Ordner "+ assets +":
wget -O assets/haarcascade_frontalface_default.xml https://github.com/opencv/opencv/raw/master/data/haarcascades/haarcascade_frontalface_default.xmlDie Option "+ -O " gibt das Ziel als " assets / haarcascade_frontalface_default.xml" an. Das zweite Argument ist die Quell-URL.
Wir erkennen alle Gesichter im folgenden Bild von https://pexels.com [Pexels] (CC0, link to original Bild).
image: https: //assets.digitalocean.com/articles/python3_dogfilter/CfoBWbF.png [Bild von Kindern]
Laden Sie zuerst das Bild herunter. Der folgende Befehl speichert das heruntergeladene Bild als + children.png + im Ordner + assets:
wget -O assets/children.png https://assets.digitalocean.com/articles/python3_dogfilter/CfoBWbF.pngUm zu überprüfen, ob der Erkennungsalgorithmus funktioniert, führen wir ihn für ein einzelnes Bild aus und speichern das resultierende kommentierte Bild auf der Festplatte. Erstellen Sie einen Ordner "+ Outputs +" für diese kommentierten Ergebnisse.
mkdir outputsErstellen Sie nun ein Python-Skript für den Gesichtsdetektor. Erstellen Sie die Datei "+ step_1_face_detect " mit " nano +" oder Ihrem bevorzugten Texteditor:
nano step_2_face_detect.pyFügen Sie der Datei den folgenden Code hinzu. Dieser Code importiert OpenCV, das die Bilddienstprogramme und den Gesichtsklassifikator enthält. Der Rest des Codes ist ein typisches Python-Programm.
step_2_face_detect.py
"""Test for face detection"""
import cv2
def main():
pass
if __name__ == '__main__':
main()Ersetzen Sie nun "+ pass " in der " main " - Funktion durch diesen Code, der einen Gesichtsklassifizierer unter Verwendung der OpenCV-Parameter initialisiert, die Sie in Ihren " assets +" -Ordner heruntergeladen haben:
step_2_face_detect.py
def main():
# initialize front face classifier
cascade = cv2.CascadeClassifier("assets/haarcascade_frontalface_default.xml")Fügen Sie als nächstes diese Zeile hinzu, um das Bild + children.png + zu laden.
step_2_face_detect.py
frame = cv2.imread('assets/children.png')Fügen Sie dann diesen Code hinzu, um das Bild in Schwarzweiß umzuwandeln, da der Klassifikator auf Schwarzweißbilder trainiert wurde. Um dies zu erreichen, konvertieren wir in Graustufen und diskretisieren dann das Histogramm:
step_2_face_detect.py
# Convert to black-and-white
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blackwhite = cv2.equalizeHist(gray)Verwenden Sie dann die OpenCV-Funktion https://docs.opencv.org/2.4/modules/objdetect/doc/cascade_classification.html#cascadeclassifier-detectmultiscale [+ detectMultiScale +], um alle Gesichter im Bild zu erkennen.
step_2_face_detect.py
rects = cascade.detectMultiScale(
blackwhite, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)-
+ scaleFactor +gibt an, wie stark das Bild in jeder Dimension verkleinert wird. -
+ minNeighbors +gibt an, wie viele benachbarte Rechtecke ein Kandidatenrechteck beibehalten werden muss. -
+ minSize +ist die minimal zulässige erkannte Objektgröße. Kleinere Objekte werden verworfen.
Der Rückgabetyp ist eine Liste von tuples, wobei jedes Tupel vier Zahlen hat, die das Minimum x, das Minimum y, die Breite, und Höhe des Rechtecks in dieser Reihenfolge.
Durchlaufen Sie alle erkannten Objekte und zeichnen Sie sie mit https://docs.opencv.org/2.4/modules/core/doc/drawing_functions.html#rectangle [+ cv2.rectangle +] grün auf das Bild:
step_2_face_detect.py
for x, y, w, h in rects:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)-
Das zweite und dritte Argument sind gegenüberliegende Ecken des Rechtecks.
-
Das vierte Argument ist die zu verwendende Farbe.
+ (0, 255, 0) +entspricht Grün für unseren RGB-Farbraum. -
Das letzte Argument gibt die Breite unserer Linie an.
Zum Schluss schreiben Sie das Bild mit den Begrenzungsrahmen in eine neue Datei unter + output / children_detected.png +:
step_2_face_detect.py
cv2.imwrite('outputs/children_detected.png', frame)Das fertige Skript sollte folgendermaßen aussehen:
step_2_face_detect.py
"""Tests face detection for a static image."""
import cv2
def main():
# initialize front face classifier
cascade = cv2.CascadeClassifier(
"assets/haarcascade_frontalface_default.xml")
frame = cv2.imread('assets/children.png')
# Convert to black-and-white
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blackwhite = cv2.equalizeHist(gray)
rects = cascade.detectMultiScale(
blackwhite, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
for x, y, w, h in rects:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imwrite('outputs/children_detected.png', frame)
if __name__ == '__main__':
main()Speichern Sie die Datei und beenden Sie Ihren Editor. Führen Sie dann das Skript aus:
python step_2_face_detect.pyÖffnen Sie "+ Outputs / children_detected.png +". Das folgende Bild zeigt die mit Kästchen umrandeten Gesichter:
image: https: //assets.digitalocean.com/articles/python3_dogfilter/x0fUqyk.png [Bild von Kindern mit Begrenzungsrahmen]
Zu diesem Zeitpunkt haben Sie einen funktionierenden Gesichtsdetektor. Es akzeptiert ein Bild als Eingabe und zeichnet Begrenzungsrahmen um alle Flächen im Bild und gibt das mit Anmerkungen versehene Bild aus. Wenden wir nun dieselbe Erkennung auf einen Live-Kamera-Feed an.
Schritt 3 - Verknüpfen des Kamera-Feeds
Das nächste Ziel besteht darin, die Kamera des Computers mit dem Gesichtsdetektor zu verbinden. Anstatt Gesichter in einem statischen Bild zu erkennen, erkennen Sie alle Gesichter von der Kamera Ihres Computers. Sie erfassen Kameraeingaben, erkennen und kommentieren alle Gesichter und zeigen das kommentierte Bild dem Benutzer wieder an. Sie fahren mit dem Skript in Schritt 2 fort. Beginnen Sie also mit dem Duplizieren dieses Skripts:
cp step_2_face_detect.py step_3_camera_face_detect.pyÖffnen Sie dann das neue Skript in Ihrem Editor:
nano step_3_camera_face_detect.pySie aktualisieren die Funktion "+ main " mithilfe einiger Elemente aus diesem https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_gui/py_video_display/py_video_display.html#capture-video-from-camera[test script] aus der offiziellen OpenCV-Dokumentation. Beginnen Sie mit der Initialisierung eines " VideoCapture +" - Objekts, das Live-Feeds von der Kamera Ihres Computers aufzeichnen soll. Fügen Sie dies vor den anderen Code in der Funktion ein:
step_3_camera_face_detect.py
def main():
...Beginnen Sie mit der Zeile, die "+ frame" definiert, und rücken Sie den gesamten vorhandenen Code ein. Platzieren Sie den gesamten Code in einer "+ while" -Schleife.
step_3_camera_face_detect.py
frame = cv2.imread('assets/children.png')
...
for x, y, w, h in rects:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imwrite('outputs/children_detected.png', frame)Ersetzen Sie die Zeile, die "+ frame" am Anfang der "+ while" -Schleife definiert. Anstatt von einem Bild auf der Festplatte zu lesen, lesen Sie jetzt von der Kamera:
step_3_camera_face_detect.py
Ersetzen Sie die Zeile + cv2.imwrite (…) + am Ende der Schleife + while +. Anstatt ein Bild auf die Festplatte zu schreiben, zeigen Sie das kommentierte Bild wieder auf dem Bildschirm des Benutzers an:
step_3_camera_face_detect.py
Fügen Sie außerdem Code hinzu, um auf Tastatureingaben zu achten, damit Sie das Programm stoppen können. Überprüfen Sie, ob der Benutzer das Zeichen "+ q " trifft, und beenden Sie in diesem Fall die Anwendung. Direkt nach ` cv2.imshow (…) +` fügen Sie Folgendes hinzu:
step_3_camera_face_detect.py
...
cv2.imshow('frame', frame)
...Die Zeile + cv2.waitkey (1) + hält das Programm für 1 Millisekunde an, damit das aufgenommene Bild dem Benutzer wieder angezeigt werden kann.
Lassen Sie zum Schluss die Aufnahme los und schließen Sie alle Fenster. Platzieren Sie diese außerhalb der "+ while" -Schleife, um die "+ main" -Funktion zu beenden.
step_3_camera_face_detect.py
...
while True:
...Ihr Skript sollte folgendermaßen aussehen:
step_3_camera_face_detect.py
"""Test for face detection on video camera.
Move your face around and a green box will identify your face.
With the test frame in focus, hit `q` to exit.
Note that typing `q` into your terminal will do nothing.
"""
import cv2
def main():
cap = cv2.VideoCapture(0)
# initialize front face classifier
cascade = cv2.CascadeClassifier(
"assets/haarcascade_frontalface_default.xml")
while True:
# Capture frame-by-frame
ret, frame = cap.read()
# Convert to black-and-white
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blackwhite = cv2.equalizeHist(gray)
# Detect faces
rects = cascade.detectMultiScale(
blackwhite, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
# Add all bounding boxes to the image
for x, y, w, h in rects:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Display the resulting frame
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()Speichern Sie die Datei und beenden Sie Ihren Editor.
Führen Sie nun das Testskript aus.
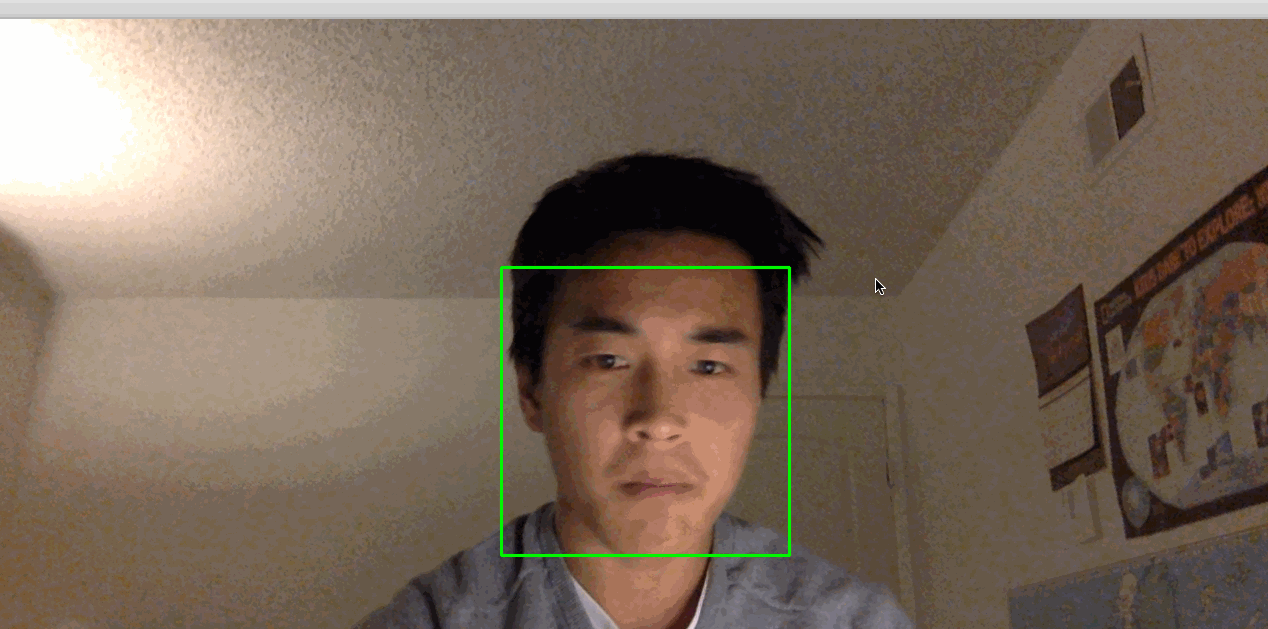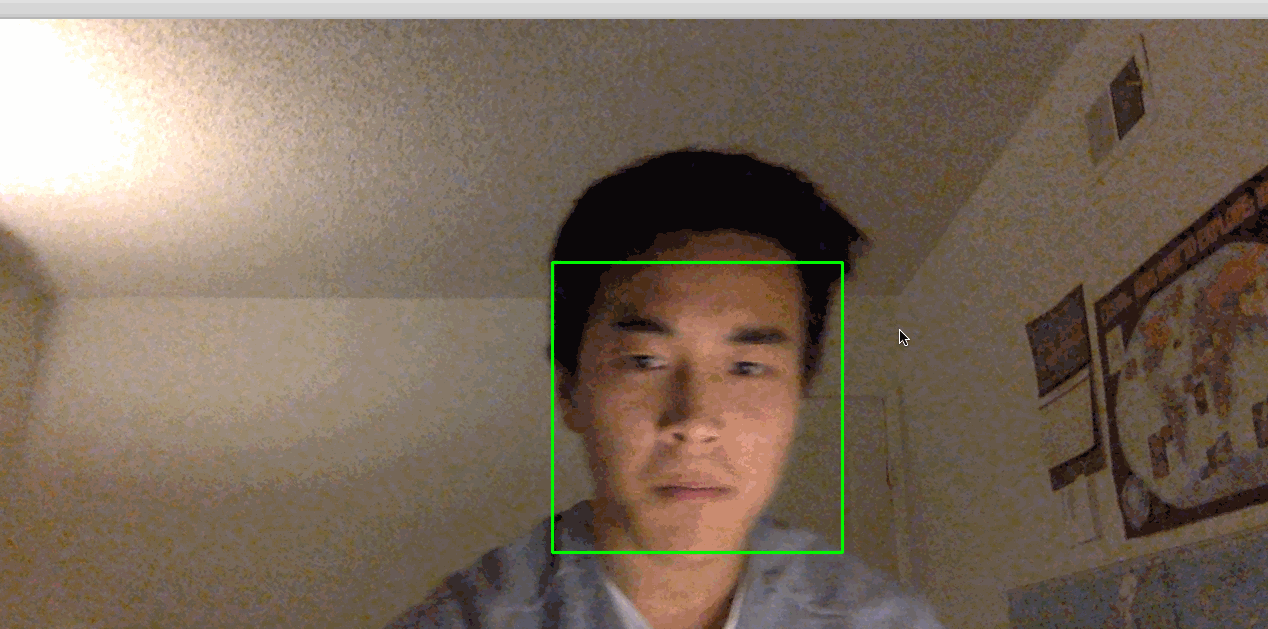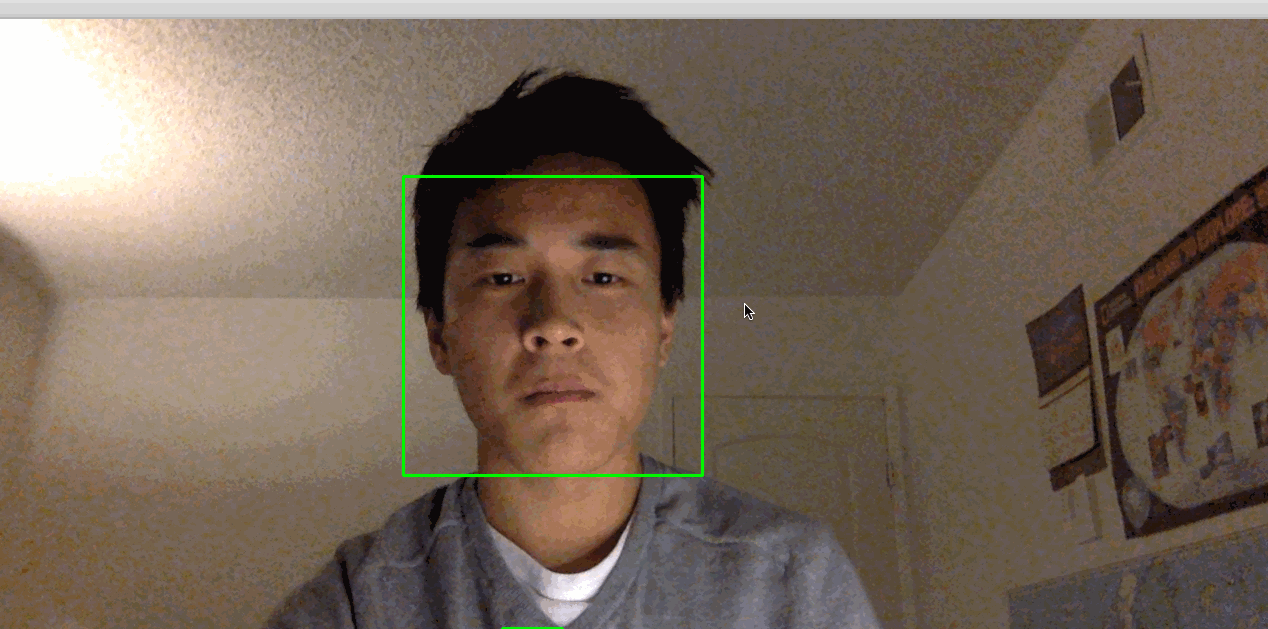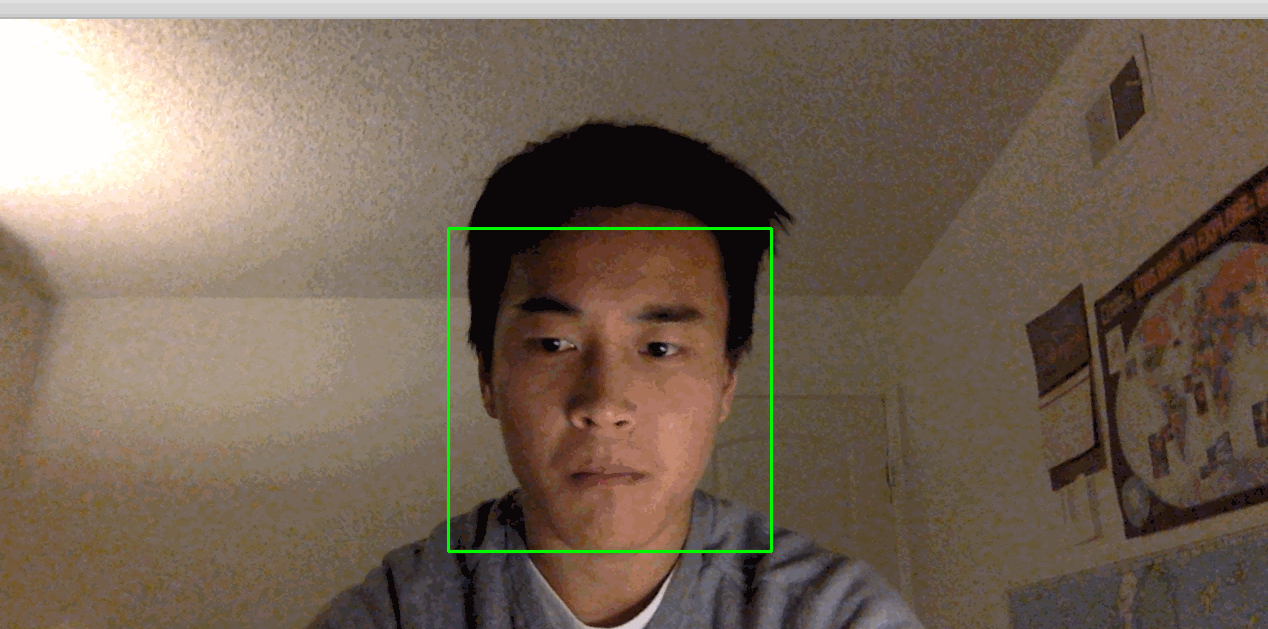
python step_3_camera_face_detect.pyDadurch wird Ihre Kamera aktiviert und ein Fenster geöffnet, in dem der Feed Ihrer Kamera angezeigt wird. Dein Gesicht wird in Echtzeit von einem grünen Quadrat umrahmt:
Bild: https://assets.digitalocean.com/articles/python3_dogfilter/a7lyf7q.gif [Arbeitsgesichtsdetektor]
{kind=link}
Unser nächstes Ziel ist es, die erkannten Gesichter aufzunehmen und Hundemasken auf jedes zu legen.
Schritt 4 - Aufbau des Hundefilters
Bevor wir den Filter selbst erstellen, wollen wir untersuchen, wie Bilder numerisch dargestellt werden. Dadurch erhalten Sie den Hintergrund, der zum Ändern von Bildern und letztendlich zum Anwenden eines Hundefilters erforderlich ist.
Schauen wir uns ein Beispiel an. Wir können ein Schwarzweißbild unter Verwendung von Zahlen konstruieren, wobei "+ 0 " Schwarz und " 1 +" Weiß entspricht.
Konzentrieren Sie sich auf die Trennlinie zwischen 1s und 0s. Welche Form siehst du?
0 0 0 0 0 0 0 0 0
0 0 0 0 1 0 0 0 0
0 0 0 1 1 1 0 0 0
0 0 1 1 1 1 1 0 0
0 0 0 1 1 1 0 0 0
0 0 0 0 1 0 0 0 0
0 0 0 0 0 0 0 0 0Das Bild ist ein Diamant. Wenn Sie diese matrix von Werten als Bild speichern. Dies gibt uns das folgende Bild:
image: https://assets.digitalocean.com/articles/python3_dogfilter/QPontyM.png [Diamant als Bild]
{kind=link}
Wir können jeden Wert zwischen 0 und 1 verwenden, z. B. 0,1, 0,26 oder 0,74391. Zahlen, die näher an 0 liegen, sind dunkler und Zahlen, die näher an 1 liegen, sind heller. Auf diese Weise können wir Weiß, Schwarz und jeden Grauton darstellen. Das sind großartige Neuigkeiten für uns, da wir jetzt jedes Graustufenbild mit 0, 1 und jedem dazwischen liegenden Wert erstellen können. Betrachten Sie beispielsweise Folgendes. Kannst du sagen, was es ist? Auch hier entspricht jede Zahl der Farbe eines Pixels.
1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 0 0 0 0 1 1 1 1
1 1 0 0 .4 .4 .4 .4 0 0 1 1
1 0 .4 .4 .5 .4 .4 .4 .4 .4 0 1
1 0 .4 .5 .5 .5 .4 .4 .4 .4 0 1
0 .4 .4 .4 .5 .4 .4 .4 .4 .4 .4 0
0 .4 .4 .4 .4 0 0 .4 .4 .4 .4 0
0 0 .4 .4 0 1 .7 0 .4 .4 0 0
0 1 0 0 0 .7 .7 0 0 0 1 0
1 0 1 1 1 0 0 .7 .7 .4 0 1
1 0 .7 1 1 1 .7 .7 .7 .7 0 1
1 1 0 0 .7 .7 .7 .7 0 0 1 1
1 1 1 1 0 0 0 0 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1Nach dem erneuten Rendern als Bild können Sie nun feststellen, dass es sich tatsächlich um einen Pokéball handelt:
image: https://assets.digitalocean.com/articles/python3_dogfilter/RwAXIGE.png [Pokeball als Bild]
{kind=link}
Sie sehen nun, wie Schwarzweiß- und Graustufenbilder numerisch dargestellt werden. Um Farbe einzuführen, brauchen wir eine Möglichkeit, mehr Informationen zu kodieren. Die Höhe und Breite eines Bildes wird als "+ h x w +" ausgedrückt.
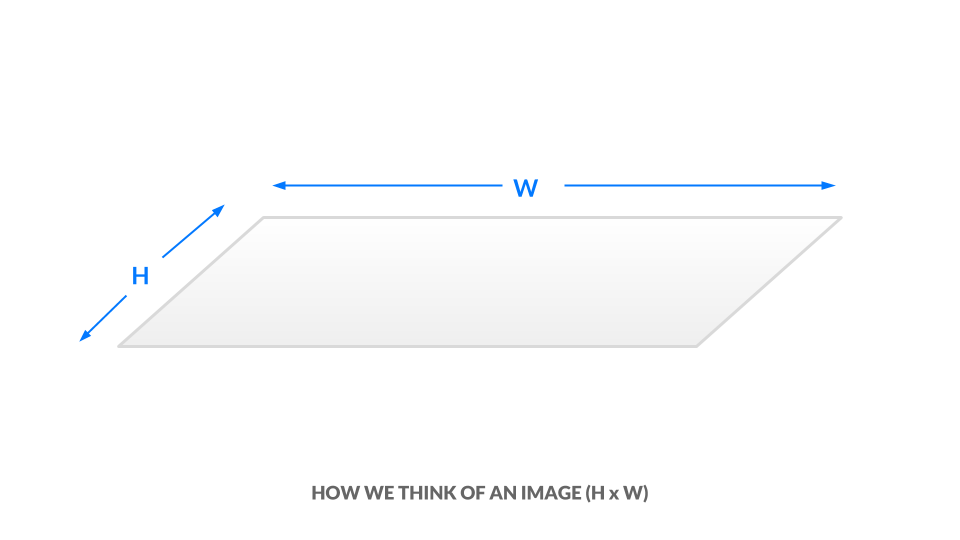{kind=link}
In der aktuellen Graustufendarstellung ist jedes Pixel ein Wert zwischen 0 und 1. Wir können gleichbedeutend sagen, dass unser Bild die Abmessungen "+ h x b x 1 " hat. Mit anderen Worten, jede Position " (x, y) +" in unserem Bild hat nur einen Wert.
image: https://assets.digitalocean.com/articles/python3_dogfilter/58GGRPe.png [Graustufenbild]
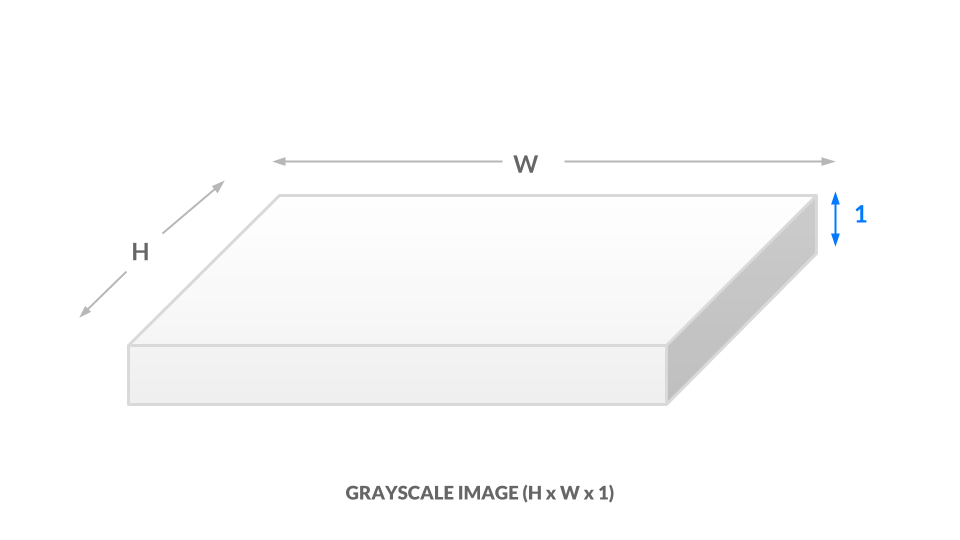{kind=link}
Für eine Farbdarstellung stellen wir die Farbe jedes Pixels mit drei Werten zwischen 0 und 1 dar. Eine Zahl entspricht dem "Grad von Rot", eine dem "Grad von Grün" und die letzte dem "Grad von Blau". Wir nennen dies den "RGB-Farbraum". Dies bedeutet, dass wir für jede Position "+ (x, y) " in unserem Bild drei Werte " (r, g, b) " haben. Als Ergebnis lautet unser Bild nun " h x b x 3 +":
image: https://assets.digitalocean.com/articles/python3_dogfilter/kXL8Mms.png [Farbbild]
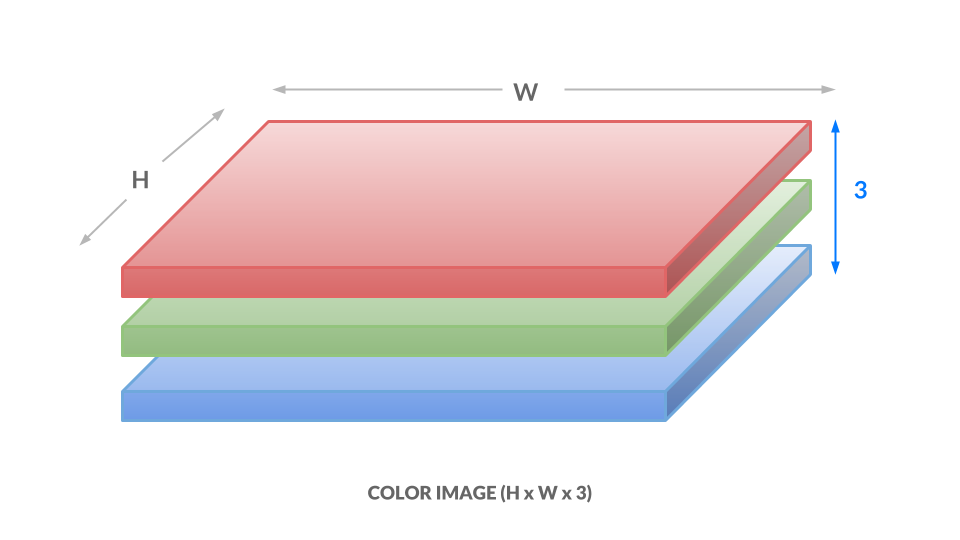{kind=link}
Hier reicht jede Zahl von 0 bis 255 anstelle von 0 bis 1, aber die Idee ist dieselbe. Unterschiedliche Zahlenkombinationen entsprechen unterschiedlichen Farben, z. B. Dunkelviolett + (102, 0, 204) + oder Hellorange + (255, 153, 51) +. Die Imbissbuden sind wie folgt:
-
Jedes Bild wird als Zahlenfeld mit drei Dimensionen dargestellt: Höhe, Breite und Farbkanäle. Das direkte Manipulieren dieses Zahlenfelds entspricht dem Manipulieren des Bildes.
-
Wir können dieses Kästchen auch zu einer Liste von Zahlen zusammenfassen. Auf diese Weise wird unser Bild zu einem vector. Später werden wir Bilder als Vektoren bezeichnen.
Nachdem Sie verstanden haben, wie Bilder numerisch dargestellt werden, sind Sie gut gerüstet, um Hundemasken auf Gesichter anzuwenden. Um eine Hundemaske anzuwenden, ersetzen Sie Werte im untergeordneten Bild durch nicht weiße Hundemaskenpixel. Zunächst arbeiten Sie mit einem einzelnen Bild. Laden Sie diesen Ausschnitt eines Gesichts aus dem Bild herunter, das Sie in Schritt 2 verwendet haben.
wget -O assets/child.png https://assets.digitalocean.com/articles/python3_dogfilter/alXjNK1.pngimage: https: //assets.digitalocean.com/articles/python3_dogfilter/alXjNK1.png [Beschnittenes Gesicht]
Laden Sie zusätzlich die folgende Hundemaske herunter. Bei den in diesem Tutorial verwendeten Hundemasken handelt es sich um meine eigenen Zeichnungen, die jetzt unter einer CC0-Lizenz öffentlich zugänglich sind.
image: https://assets.digitalocean.com/articles/python3_dogfilter/ED32BCs.png [Hundemaske]
{kind=link}
Lade dies mit + wget + herunter:
wget -O assets/dog.png https://assets.digitalocean.com/articles/python3_dogfilter/ED32BCs.pngErstellen Sie eine neue Datei mit dem Namen "+ step_4_dog_mask_simple.py +", die den Code für das Skript enthält, mit dem die Hundemaske auf Gesichter angewendet wird:
nano step_4_dog_mask_simple.pyFügen Sie das folgende Boilerplate für das Python-Skript hinzu und importieren Sie die Bibliotheken OpenCV und + numpy +:
step_4_dog_mask_simple.py
"""Test for adding dog mask"""
import cv2
import numpy as np
def main():
pass
if __name__ == '__main__':
main()Ersetzen Sie in der Funktion "+ main " " pass +" durch diese beiden Zeilen, die das Originalbild und die Hundemaske in den Speicher laden.
step_4_dog_mask_simple.py
...
def main():
face = cv2.imread('assets/child.png')
mask = cv2.imread('assets/dog.png')Befestigen Sie als nächstes die Hundemaske am Kind. Die Logik ist komplizierter als das, was wir bisher gemacht haben. Daher werden wir eine neue Funktion namens "+ apply_mask " erstellen, um unseren Code zu modularisieren. Fügen Sie direkt nach den beiden Zeilen, die die Bilder laden, diese Zeile hinzu, die die Funktion ` apply_mask +` aufruft:
step_4_dog_mask_simple.py
...
face_with_mask = apply_mask(face, mask)Erstellen Sie eine neue Funktion mit dem Namen "+ apply_mask " und platzieren Sie sie über der Funktion " main +":
step_4_dog_mask_simple.py
...
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
pass
def main():
...Zu diesem Zeitpunkt sollte Ihre Datei folgendermaßen aussehen:
step_4_dog_mask_simple.py
"""Test for adding dog mask"""
import cv2
import numpy as np
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
pass
def main():
face = cv2.imread('assets/child.png')
mask = cv2.imread('assets/dog.png')
face_with_mask = apply_mask(face, mask)
if __name__ == '__main__':
main()Bauen wir die Funktion "+ apply_mask " aus. Unser Ziel ist es, die Maske auf das Gesicht des Kindes aufzutragen. Wir müssen jedoch das Seitenverhältnis für unsere Hundemaske beibehalten. Dazu müssen wir die endgültigen Abmessungen unserer Hundemaske explizit berechnen. Ersetzen Sie in der Funktion " apply_mask " " pass +" durch diese beiden Zeilen, die die Höhe und Breite beider Bilder extrahieren:
step_4_dog_mask_simple.py
...
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shapeBestimmen Sie als Nächstes, welche Dimension "stärker verkleinert" werden muss. Um genau zu sein, benötigen wir die engere der beiden Einschränkungen. Fügen Sie diese Zeile zur Funktion + apply_mask + hinzu:
step_4_dog_mask_simple.py
...
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)Berechnen Sie dann die neue Form, indem Sie der Funktion den folgenden Code hinzufügen:
step_4_dog_mask_simple.py
...
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)Hier setzen wir die Zahlen in ganze Zahlen um, da die Funktion + resize + integrale Dimensionen benötigt.
Fügen Sie nun diesen Code hinzu, um die Größe der Hundemaske an die neue Form anzupassen:
step_4_dog_mask_simple.py
...
# Add mask to face - ensure mask is centered
resized_mask = cv2.resize(mask, new_mask_shape)Zum Schluss schreiben Sie das Image auf die Festplatte, damit Sie überprüfen können, ob Ihre angepasste Hundemaske korrekt ist, nachdem Sie das Skript ausgeführt haben:
step_4_dog_mask_simple.py
cv2.imwrite('outputs/resized_dog.png', resized_mask)Das fertige Skript sollte folgendermaßen aussehen:
step_4_dog_mask_simple.py
"""Test for adding dog mask"""
import cv2
import numpy as np
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)
# Add mask to face - ensure mask is centered
resized_mask = cv2.resize(mask, new_mask_shape)
cv2.imwrite('outputs/resized_dog.png', resized_mask)
def main():
face = cv2.imread('assets/child.png')
mask = cv2.imread('assets/dog.png')
face_with_mask = apply_mask(face, mask)
if __name__ == '__main__':
main()Speichern Sie die Datei und beenden Sie Ihren Editor. Führen Sie das neue Skript aus:
python step_4_dog_mask_simple.pyÖffnen Sie das Bild unter + output / resized_dog.png +, um zu überprüfen, ob die Größe der Maske korrekt geändert wurde. Es passt zu der Hundemaske, die weiter oben in diesem Abschnitt gezeigt wurde.
Fügen Sie dem Kind nun die Hundemaske hinzu. Öffnen Sie die Datei "+ step_4_dog_mask_simple.py " erneut und kehren Sie zur Funktion " apply_mask +" zurück:
nano step_4_dog_mask_simple.pyEntfernen Sie zunächst die Codezeile, in der die Maske mit geänderter Größe geschrieben wird, aus der Funktion + apply_mask +, da Sie sie nicht mehr benötigen:
...Wenden Sie stattdessen Ihr Wissen über die Bilddarstellung vom Anfang dieses Abschnitts an an, um das Bild zu ändern. Beginnen Sie, indem Sie eine Kopie des untergeordneten Bildes erstellen. Fügen Sie diese Zeile zur Funktion + apply_mask + hinzu:
step_4_dog_mask_simple.py
...
face_with_mask = face.copy()Als nächstes finden Sie alle Positionen, an denen die Hundemaske nicht weiß oder fast weiß ist. Überprüfen Sie dazu, ob der Pixelwert in allen Farbkanälen unter 250 liegt, da ein nahezu weißes Pixel in der Nähe von "+ [255, 255, 255] +" erwartet wird. Füge diesen Code hinzu:
step_4_dog_mask_simple.py
...
non_white_pixels = (resized_mask < 250).all(axis=2)Zu diesem Zeitpunkt ist das Hundebild höchstens so groß wie das Kinderbild. Wir möchten das Hundebild auf dem Gesicht zentrieren. Berechnen Sie daher den zum Zentrieren des Hundebildes erforderlichen Versatz, indem Sie diesen Code zu "+ apply_mask +" hinzufügen:
step_4_dog_mask_simple.py
...
off_h = int((face_h - new_mask_h) / 2)
off_w = int((face_w - new_mask_w) / 2)Kopieren Sie alle nicht weißen Pixel vom Hundebild in das untergeordnete Bild. Da das untergeordnete Bild möglicherweise größer als das Hundebild ist, müssen wir eine Teilmenge des untergeordneten Bildes aufnehmen:
step_4_dog_mask_simple.py
face_with_mask[off_h: off_h+new_mask_h, off_w: off_w+new_mask_w][non_white_pixels] = \
resized_mask[non_white_pixels]Dann gib das Ergebnis zurück:
step_4_dog_mask_simple.py
return face_with_maskFügen Sie in der Funktion "+ main " diesen Code hinzu, um das Ergebnis der Funktion " apply_mask +" in ein Ausgabebild zu schreiben, damit Sie das Ergebnis manuell überprüfen können:
step_4_dog_mask_simple.py
...
face_with_mask = apply_mask(face, mask)Ihr fertiges Skript sieht folgendermaßen aus:
step_4_dog_mask_simple.py
"""Test for adding dog mask"""
import cv2
import numpy as np
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)
resized_mask = cv2.resize(mask, new_mask_shape)
# Add mask to face - ensure mask is centered
face_with_mask = face.copy()
non_white_pixels = (resized_mask < 250).all(axis=2)
off_h = int((face_h - new_mask_h) / 2)
off_w = int((face_w - new_mask_w) / 2)
face_with_mask[off_h: off_h+new_mask_h, off_w: off_w+new_mask_w][non_white_pixels] = \
resized_mask[non_white_pixels]
return face_with_mask
def main():
face = cv2.imread('assets/child.png')
mask = cv2.imread('assets/dog.png')
face_with_mask = apply_mask(face, mask)
cv2.imwrite('outputs/child_with_dog_mask.png', face_with_mask)
if __name__ == '__main__':
main()Speichern Sie das Skript und führen Sie es aus:
python step_4_dog_mask_simple.pySie haben das folgende Bild eines Kindes mit einer Hundemaske in "+ Outputs / child_with_dog_mask.png +":
image: https: //assets.digitalocean.com/articles/python3_dogfilter/ZEn0RsJ.png [Bild eines Kindes mit Hundemaske]
Sie haben jetzt ein Dienstprogramm, mit dem Hundemasken auf Gesichter angewendet werden. Verwenden wir nun das, was Sie erstellt haben, um die Hundemaske in Echtzeit hinzuzufügen.
Wir werden dort weitermachen, wo wir in Schritt 3 aufgehört haben. Kopieren Sie "+ step_3_camera_face_detect.py " nach " step_4_dog_mask.py +".
cp step_3_camera_face_detect.py step_4_dog_mask.pyÖffnen Sie Ihr neues Skript.
nano step_4_dog_mask.pyImportieren Sie zuerst die NumPy-Bibliothek oben im Skript:
step_4_dog_mask.py
import numpy as np
...Fügen Sie dann die Funktion "+ apply_mask " aus Ihrer vorherigen Arbeit über der Funktion " main +" in diese neue Datei ein:
step_4_dog_mask.py
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)
resized_mask = cv2.resize(mask, new_mask_shape)
# Add mask to face - ensure mask is centered
face_with_mask = face.copy()
non_white_pixels = (resized_mask < 250).all(axis=2)
off_h = int((face_h - new_mask_h) / 2)
off_w = int((face_w - new_mask_w) / 2)
face_with_mask[off_h: off_h+new_mask_h, off_w: off_w+new_mask_w][non_white_pixels] = \
resized_mask[non_white_pixels]
return face_with_mask
...Suchen Sie zweitens diese Zeile in der Funktion "+ main +":
step_4_dog_mask.py
cap = cv2.VideoCapture(0)Fügen Sie diesen Code nach dieser Zeile ein, um die Hundemaske zu laden:
step_4_dog_mask.py
cap = cv2.VideoCapture(0)
...Suchen Sie als nächstes in der Schleife "+ while +" die folgende Zeile:
step_4_dog_mask.py
ret, frame = cap.read()Fügen Sie diese Zeile dahinter ein, um die Höhe und Breite des Bildes zu extrahieren:
step_4_dog_mask.py
ret, frame = cap.read()
...Löschen Sie als nächstes die Linie in "+ main ", die Begrenzungsrahmen zeichnet. Sie finden diese Zeile in der " für +" -Schleife, die erkannte Gesichter durchläuft:
step_4_dog_mask.py
for x, y, w, h in rects:
...
...Fügen Sie stattdessen diesen Code hinzu, der den Frame beschneidet. Aus ästhetischen Gründen beschneiden wir einen Bereich, der etwas größer als das Gesicht ist.
step_4_dog_mask.py
for x, y, w, h in rects:
# crop a frame slightly larger than the face
y0, y1 = int(y - 0.25*h), int(y + 0.75*h)
x0, x1 = x, x + wFühren Sie eine Überprüfung durch, falls sich das erkannte Gesicht zu nahe am Rand befindet.
step_4_dog_mask.py
# give up if the cropped frame would be out-of-bounds
if x0 < 0 or y0 < 0 or x1 > frame_w or y1 > frame_h:
continueFügen Sie abschließend das Gesicht mit einer Maske in das Bild ein.
step_4_dog_mask.py
# apply mask
frame[y0: y1, x0: x1] = apply_mask(frame[y0: y1, x0: x1], mask)Stellen Sie sicher, dass Ihr Skript folgendermaßen aussieht:
step_4_dog_mask.py
"""Real-time dog filter
Move your face around and a dog filter will be applied to your face if it is not out-of-bounds. With the test frame in focus, hit `q` to exit. Note that typing `q` into your terminal will do nothing.
"""
import numpy as np
import cv2
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)
resized_mask = cv2.resize(mask, new_mask_shape)
# Add mask to face - ensure mask is centered
face_with_mask = face.copy()
non_white_pixels = (resized_mask < 250).all(axis=2)
off_h = int((face_h - new_mask_h) / 2)
off_w = int((face_w - new_mask_w) / 2)
face_with_mask[off_h: off_h+new_mask_h, off_w: off_w+new_mask_w][non_white_pixels] = \
resized_mask[non_white_pixels]
return face_with_mask
def main():
cap = cv2.VideoCapture(0)
# load mask
mask = cv2.imread('assets/dog.png')
# initialize front face classifier
cascade = cv2.CascadeClassifier("assets/haarcascade_frontalface_default.xml")
while(True):
# Capture frame-by-frame
ret, frame = cap.read()
frame_h, frame_w, _ = frame.shape
# Convert to black-and-white
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blackwhite = cv2.equalizeHist(gray)
# Detect faces
rects = cascade.detectMultiScale(
blackwhite, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
# Add mask to faces
for x, y, w, h in rects:
# crop a frame slightly larger than the face
y0, y1 = int(y - 0.25*h), int(y + 0.75*h)
x0, x1 = x, x + w
# give up if the cropped frame would be out-of-bounds
if x0 < 0 or y0 < 0 or x1 > frame_w or y1 > frame_h:
continue
# apply mask
frame[y0: y1, x0: x1] = apply_mask(frame[y0: y1, x0: x1], mask)
# Display the resulting frame
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()Speichern Sie die Datei und beenden Sie Ihren Editor. Führen Sie dann das Skript aus.
python step_4_dog_mask.pySie haben jetzt einen Echtzeit-Hundefilter in Betrieb. Das Skript funktioniert auch mit mehreren Gesichtern im Bild, sodass Sie Ihre Freunde für eine automatische Hundebestimmung zusammenbringen können.
Bild: https://assets.digitalocean.com/articles/python3_dogfilter/g9CiUD1.gif [GIF für Working Dog Filter]
{kind=link}
Dies schließt unser erstes Hauptziel in diesem Tutorial ab, nämlich die Erstellung eines Snapchat-ähnlichen Hundefilters. Verwenden wir nun den Gesichtsausdruck, um die Hundemaske zu bestimmen, die auf ein Gesicht angewendet wird.
Schritt 5 - Erstellen Sie einen grundlegenden Gesichtsemotionsklassifikator mit den kleinsten Quadraten
In diesem Abschnitt erstellen Sie einen Emotionsklassifizierer, um verschiedene Masken basierend auf den angezeigten Emotionen anzuwenden. Wenn Sie lächeln, wendet der Filter eine Corgimaske an. Wenn Sie die Stirn runzeln, wird es eine Mopsmaske anwenden. Auf dem Weg dorthin lernen Sie das least-squares-Framework kennen, das für das Verständnis und die Diskussion von Konzepten für maschinelles Lernen von grundlegender Bedeutung ist.
Um zu verstehen, wie unsere Daten verarbeitet und Vorhersagen erstellt werden, werden wir zunächst die Modelle des maschinellen Lernens untersuchen.
Wir müssen zwei Fragen für jedes Modell stellen, das wir betrachten. Vorerst reichen diese beiden Fragen aus, um zwischen Modellen zu unterscheiden:
-
Input: Welche Informationen erhält das Modell?
-
Output: Was versucht das Modell vorherzusagen?
Ziel ist es, auf hoher Ebene ein Modell für die Emotionsklassifikation zu entwickeln. Das Modell ist:
-
Eingabe: gegebene Bilder von Gesichtern.
-
Ausgabe: sagt die entsprechende Emotion voraus.
model: face -> emotionDer Ansatz, den wir verwenden werden, ist kleinste Quadrate; Wir nehmen eine Reihe von Punkten und finden eine Linie, die am besten passt. Die im folgenden Bild gezeigte Linie der besten Anpassung ist unser Modell.
image: https://assets.digitalocean.com/articles/python3_dogfilter/lYQDlWs.png [Least Squares]
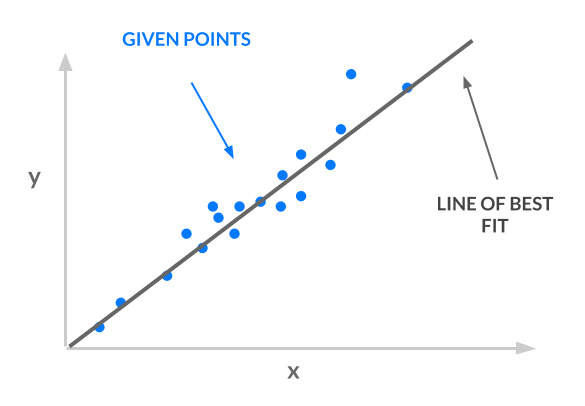{kind=link}
Betrachten Sie die Ein- und Ausgabe für unsere Linie:
-
Eingabe: gegebene
+ x +Koordinaten. -
Ausgabe: sagt die entsprechende $ y $ -Koordinate voraus.
least squares line: x -> yUnsere Eingabe + x + muss Gesichter darstellen und unsere Ausgabe + y + muss Emotionen darstellen, damit wir die kleinsten Quadrate für die Emotionsklassifizierung verwenden können:
-
+ x → face +: Anstatt one number für+ x +zu verwenden, verwenden wir einen vector von Werten für+ x +. Somit kann "+ x " Bilder von Gesichtern darstellen. Der Artikel http://alvinwan.com/understanding-least-squares/#ordinary-least-squares[Ordinary Least Squares] erklärt, warum Sie einen Vektor von Werten für ` x +` verwenden können. -
+ y → emotion +: Jede Emotion entspricht einer Zahl. Zum Beispiel ist "wütend" 0, "traurig" ist 1 und "glücklich" ist 2. Auf diese Weise kann+ y +Emotionen darstellen. Unsere Zeile ist jedoch nicht auf die Ausgabe der+ y +- Werte 0, 1 und 2 beschränkt. Es gibt unendlich viele mögliche y-Werte: 1,2, 3,5 oder 10003,42. Wie übersetzen wir diese+ y +- Werte in Ganzzahlen, die Klassen entsprechen? Weitere Informationen und Erklärungen finden Sie im Artikel One-Hot Encoding.
Mit diesem Hintergrundwissen werden Sie einen einfachen Klassifikator für kleinste Fehlerquadrate erstellen, der aus vektorisierten Bildern und One-Hot-codierten Beschriftungen besteht. Dies erreichen Sie in drei Schritten:
-
Daten vorverarbeiten: Wie zu Beginn dieses Abschnitts erläutert, sind unsere Beispiele Vektoren, bei denen jeder Vektor ein Bild eines Gesichts codiert. Unsere Beschriftungen sind Ganzzahlen, die einer Emotion entsprechen, und wir werden diese Beschriftungen mit einer einzigen Codierung versehen.
-
Spezifizieren und trainieren Sie das Modell: Verwenden Sie die Lösung der kleinsten Quadrate in geschlossener Form,
+ w ^ * +. -
Führen Sie eine Vorhersage mit dem Modell durch: Nehmen Sie den Argmax von "+ Xw ^ * +", um vorhergesagte Emotionen zu erhalten.
Lass uns anfangen.
Richten Sie zunächst ein Verzeichnis ein, das die Daten enthält:
mkdir dataLaden Sie anschließend die von Pierre-Luc Carrier und Aaron Courville kuratierten Daten aus einer Face Emotion-Klassifizierung von 2013 herunter auf Kaggle].
wget -O data/fer2013.tar https://bitbucket.org/alvinwan/adversarial-examples-in-computer-vision-building-then-fooling/raw/babfe4651f89a398c4b3fdbdd6d7a697c5104cff/fer2013.tarNavigieren Sie zum Verzeichnis "+ data" und entpacken Sie die Daten.
cd data
tar -xzf fer2013.tarJetzt erstellen wir ein Skript zum Ausführen des Modells der kleinsten Quadrate. Navigieren Sie zum Stammverzeichnis Ihres Projekts:
cd ~/DogFilterErstellen Sie eine neue Datei für das Skript:
nano step_5_ls_simple.pyFügen Sie Python Boilerplate hinzu und importieren Sie die Pakete, die Sie benötigen:
step_5_ls_simple.py
"""Train emotion classifier using least squares."""
import numpy as np
def main():
pass
if __name__ == '__main__':
main()Laden Sie anschließend die Daten in den Speicher. Ersetzen Sie "+ pass " in Ihrer " main +" - Funktion durch den folgenden Code:
step_5_ls_simple.py
# load data
with np.load('data/fer2013_train.npz') as data:
X_train, Y_train = data['X'], data['Y']
with np.load('data/fer2013_test.npz') as data:
X_test, Y_test = data['X'], data['Y']Jetzt einmalig die Etiketten codieren. Dazu konstruieren Sie die Identitätsmatrix mit "+ numpy +" und indizieren diese Matrix mit Hilfe unserer Bezeichnungsliste:
step_5_ls_simple.py
# one-hot labels
I = np.eye(6)
Y_oh_train, Y_oh_test = I[Y_train], I[Y_test]Hier verwenden wir die Tatsache, dass die + i + -te Zeile in der Identitätsmatrix bis auf den + i + -ten Eintrag alle Null ist. Somit ist die i-te Zeile die One-Hot-Codierung für das Label der Klasse "+ i ". Zusätzlich verwenden wir die erweiterte Indizierung von " numpy ", wobei " [a, b, c, d] [[1, 3]] = [b, d] +".
Das Berechnen von "+ (X ^ TX) ^ {- 1} " würde auf Standardhardware zu lange dauern, da " X ^ TX " eine " 2304x2304 +" - Matrix mit über vier Millionen Werten ist indem Sie nur die ersten 100 Features auswählen. Füge diesen Code hinzu:
step_5_ls_simple.py
...
# select first 100 dimensions
A_train, A_test = X_train[:, :100], X_test[:, :100]Fügen Sie als Nächstes diesen Code hinzu, um die Lösung der kleinsten Quadrate in geschlossener Form zu bewerten:
step_5_ls_simple.py
...
# train model
w = np.linalg.inv(A_train.T.dot(A_train)).dot(A_train.T.dot(Y_oh_train))Definieren Sie dann eine Bewertungsfunktion für Trainings- und Validierungssätze. Stellen Sie dies vor Ihre + main + Funktion:
step_5_ls_simple.py
def evaluate(A, Y, w):
Yhat = np.argmax(A.dot(w), axis=1)
return np.sum(Yhat == Y) / Y.shape[0]Um Etiketten abzuschätzen, nehmen wir mit jeder Probe das innere Produkt und erhalten die Indizes der Maximalwerte mit + np.argmax +. Dann berechnen wir die durchschnittliche Anzahl der korrekten Klassifikationen. Diese endgültige Zahl ist Ihre Richtigkeit.
Fügen Sie diesen Code am Ende der Funktion "+ main " hinzu, um die Genauigkeit von Training und Validierung mit der Funktion " valu +" zu berechnen, die Sie gerade geschrieben haben:
step_5_ls_simple.py
# evaluate model
ols_train_accuracy = evaluate(A_train, Y_train, w)
print('(ols) Train Accuracy:', ols_train_accuracy)
ols_test_accuracy = evaluate(A_test, Y_test, w)
print('(ols) Test Accuracy:', ols_test_accuracy)Stellen Sie sicher, dass Ihr Skript den folgenden Kriterien entspricht:
step_5_ls_simple.py
"""Train emotion classifier using least squares."""
import numpy as np
def evaluate(A, Y, w):
Yhat = np.argmax(A.dot(w), axis=1)
return np.sum(Yhat == Y) / Y.shape[0]
def main():
# load data
with np.load('data/fer2013_train.npz') as data:
X_train, Y_train = data['X'], data['Y']
with np.load('data/fer2013_test.npz') as data:
X_test, Y_test = data['X'], data['Y']
# one-hot labels
I = np.eye(6)
Y_oh_train, Y_oh_test = I[Y_train], I[Y_test]
# select first 100 dimensions
A_train, A_test = X_train[:, :100], X_test[:, :100]
# train model
w = np.linalg.inv(A_train.T.dot(A_train)).dot(A_train.T.dot(Y_oh_train))
# evaluate model
ols_train_accuracy = evaluate(A_train, Y_train, w)
print('(ols) Train Accuracy:', ols_train_accuracy)
ols_test_accuracy = evaluate(A_test, Y_test, w)
print('(ols) Test Accuracy:', ols_test_accuracy)
if __name__ == '__main__':
main()Speichern Sie Ihre Datei, beenden Sie Ihren Editor und führen Sie das Python-Skript aus.
python step_5_ls_simple.pySie sehen die folgende Ausgabe:
Output(ols) Train Accuracy: 0.4748918316507146
(ols) Test Accuracy: 0.45280545359202934Unser Modell liefert 47,5% Zuggenauigkeit. Wir wiederholen dies für den Validierungssatz, um eine Genauigkeit von 45,3% zu erhalten. Bei einem Drei-Wege-Klassifizierungsproblem liegen 45,3% vernünftigerweise über der Schätzung, was 33% entspricht. Dies ist unser Startklassifikator für die Emotionserkennung. Im nächsten Schritt bauen Sie dieses Modell mit den kleinsten Quadraten auf, um die Genauigkeit zu verbessern. Je höher die Genauigkeit, desto zuverlässiger kann Ihr emotionsbasierter Hundefilter den passenden Hundefilter für jede erkannte Emotion finden.
Schritt 6 - Verbesserung der Genauigkeit durch Verwendung der Eingänge
Wir können ein aussagekräftigeres Modell verwenden, um die Genauigkeit zu erhöhen. Um dies zu erreichen, featurisieren wir unsere Eingaben.
Das Originalbild sagt uns, dass die Position (+0, 0 +) rot ist, (+1, 0 +) braun ist und so weiter. Ein featurized Bild kann uns sagen, dass sich oben links im Bild ein Hund befindet, eine Person in der Mitte usw. Feature ist mächtig, aber seine genaue Definition geht über den Rahmen dieses Tutorials hinaus.
Für den Kernel der radialen Basisfunktion (RBF) verwenden wir eine https://people.eecs.berkeley.edu/%7Ebrecht/papers/07.rah.rec.nips.pdf[approximation, wobei eine zufällige Gaußsche Matrix verwendet wird. Wir werden in diesem Tutorial nicht auf Details eingehen. Stattdessen behandeln wir dies als Black Box, die für uns Features höherer Ordnung berechnet.
Wir werden dort weitermachen, wo wir im vorherigen Schritt aufgehört haben. Kopieren Sie das vorherige Skript, damit Sie einen guten Ausgangspunkt haben:
cp step_5_ls_simple.py step_6_ls_simple.pyÖffnen Sie die neue Datei in Ihrem Editor:
nano step_6_ls_simple.pyWir beginnen mit der Erstellung der featurizing-Zufallsmatrix. In unserem neuen Funktionsbereich werden wiederum nur 100 Funktionen verwendet.
Suchen Sie die folgende Zeile und definieren Sie "+ A_train " und " A_test +":
step_6_ls_simple.py
# select first 100 dimensions
A_train, A_test = X_train[:, :100], X_test[:, :100]Fügen Sie direkt über dieser Definition für "+ A_train " und " A_test +" eine zufällige Merkmalsmatrix hinzu:
step_6_ls_simple.py
# select first 100 dimensions
A_train, A_test = X_train[:, :100], X_test[:, :100] ...Ersetzen Sie dann die Definitionen für "+ A_train " und " A_test +". Wir definieren unsere Matrizen, die design-Matrizen, mit dieser zufälligen Funktion neu.
step_6_ls_simple.py
A_train, A_test = X_train.dot(W), X_test.dot(W)Speichern Sie Ihre Datei und führen Sie das Skript aus.
python step_6_ls_simple.pySie sehen die folgende Ausgabe:
Output(ols) Train Accuracy: 0.584174642717
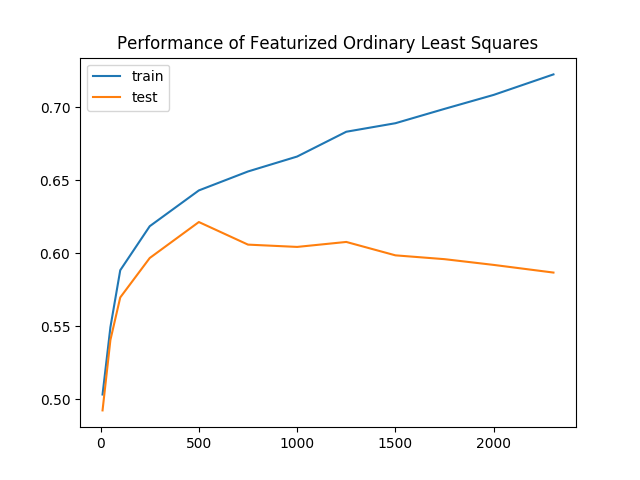
(ols) Test Accuracy: 0.584425799685Diese Funktion bietet jetzt eine Zuggenauigkeit von 58,4% und eine Validierungsgenauigkeit von 58,4%, was einer Verbesserung der Validierungsergebnisse um 13,1% entspricht. Wir haben die X-Matrix auf "100 x 100 +" getrimmt, aber die Auswahl von 100 war willkürlich. Wir könnten die " X " - Matrix auch auf "+1000 x 1000 +" oder "+50 x 50 +" trimmen. Angenommen, die Dimension von " x " ist " d x d ". Wir können weitere Werte von " d " testen, indem wir X erneut auf " d x d +" zuschneiden und ein neues Modell berechnen.
Wenn wir mehr Werte von "+ d " versuchen, finden wir eine zusätzliche Verbesserung der Testgenauigkeit um 4,3% auf 61,7%. In der folgenden Abbildung betrachten wir die Leistung unseres neuen Klassifikators, wenn wir " d " variieren. Intuitiv sollte mit zunehmendem " d +" auch die Genauigkeit zunehmen, da wir immer mehr unserer Originaldaten verwenden. Anstatt ein rosiges Bild zu zeichnen, weist die Grafik einen negativen Trend auf:
image: https://assets.digitalocean.com/articles/python3_dogfilter/cfKxdJ9.png [Leistung von featurisierten gewöhnlichen kleinsten Quadraten]
{kind=link}
Wenn wir mehr Daten speichern, vergrößert sich auch die Lücke zwischen der Genauigkeit von Training und Validierung. Dies ist ein klarer Beweis für eine Überanpassung, bei der unser Modell Darstellungen lernt, die nicht mehr für alle Daten verallgemeinerbar sind. Um der Überanpassung entgegenzuwirken, werden wir unser Modell durch Bestrafung komplexer Modelle anpassen.
Wir ergänzen unsere gewöhnliche Zielfunktion der kleinsten Quadrate um einen Regularisierungsterm, der uns ein neues Ziel gibt. Unsere neue Zielfunktion heißt ridge regression und sieht folgendermaßen aus:
min_w |Aw- y|^2 + lambda |w|^2In dieser Gleichung ist "+ Lambda " ein einstellbarer Hyperparameter. Fügen Sie ` lambda = 0 ` in die Gleichung ein und die Gratregression wird zu kleinsten Quadraten. Wenn Sie " Lambda = unendlich " in die Gleichung einfügen, müssen Sie feststellen, dass das beste " w " jetzt Null ist, da jedes Nicht-Null-Zeichen " w +" einen unendlichen Verlust verursacht. Wie sich herausstellt, ergibt dieses Ziel auch eine geschlossene Lösung:
w^* = (A^TA + lambda I)^{-1}A^TyVerwenden Sie weiterhin die featurized-Beispiele, um das Modell erneut zu trainieren und neu zu bewerten.
Öffne + step_6_ls_simple.py + erneut in deinem Editor:
nano step_6_ls_simple.pyErhöhen Sie diesmal die Dimensionalität des neuen Feature-Space auf "+ d = 1000 ". Ändern Sie den Wert von " d " von " 100 " in " 1000 +", wie im folgenden Codeblock gezeigt:
step_6_ls_simple.py
...
d =
W = np.random.normal(size=(X_train.shape[1], d))
...Wenden Sie dann die Gratregression mit einer Regularisierung von + lambda = 10 ^ {10} + an. Ersetzen Sie die Zeile, die "+ w +" definiert, durch die folgenden zwei Zeilen:
step_6_ls_simple.py
...
# train model
1e10 * IDann suchen Sie diesen Block:
step_6_ls_simple.py
...
ols_train_accuracy = evaluate(A_train, Y_train, w)
print('(ols) Train Accuracy:', ols_train_accuracy)
ols_test_accuracy = evaluate(A_test, Y_test, w)
print('(ols) Test Accuracy:', ols_test_accuracy)Ersetzen Sie es durch Folgendes:
step_6_ls_simple.py
...
print('(ridge) Train Accuracy:', evaluate(A_train, Y_train, w))
print('(ridge) Test Accuracy:', evaluate(A_test, Y_test, w))Das fertige Skript sollte folgendermaßen aussehen:
step_6_ls_simple.py
"""Train emotion classifier using least squares."""
import numpy as np
def evaluate(A, Y, w):
Yhat = np.argmax(A.dot(w), axis=1)
return np.sum(Yhat == Y) / Y.shape[0]
def main():
# load data
with np.load('data/fer2013_train.npz') as data:
X_train, Y_train = data['X'], data['Y']
with np.load('data/fer2013_test.npz') as data:
X_test, Y_test = data['X'], data['Y']
# one-hot labels
I = np.eye(6)
Y_oh_train, Y_oh_test = I[Y_train], I[Y_test]
d = 1000
W = np.random.normal(size=(X_train.shape[1], d))
# select first 100 dimensions
A_train, A_test = X_train.dot(W), X_test.dot(W)
# train model
I = np.eye(A_train.shape[1])
w = np.linalg.inv(A_train.T.dot(A_train) + 1e10 * I).dot(A_train.T.dot(Y_oh_train))
# evaluate model
print('(ridge) Train Accuracy:', evaluate(A_train, Y_train, w))
print('(ridge) Test Accuracy:', evaluate(A_test, Y_test, w))
if __name__ == '__main__':
main()Speichern Sie die Datei, beenden Sie Ihren Editor und führen Sie das Skript aus:
python step_6_ls_simple.pySie sehen die folgende Ausgabe:
Output(ridge) Train Accuracy: 0.651173462698
(ridge) Test Accuracy: 0.622181436812Die Validierungsgenauigkeit wurde um 0,4% auf 62,2% verbessert, da die Zuggenauigkeit auf 65,1% sinkt. Bei erneuter Neubewertung über eine Reihe von verschiedenen + d + stellen wir eine kleinere Lücke zwischen Trainings- und Validierungsgenauigkeiten für die Gratregression fest. Mit anderen Worten, die Gratregression unterlag einer geringeren Überanpassung.
image: https: //assets.digitalocean.com/articles/python3_dogfilter/gzGBSGo.png [Leistung von featurisierten Ols und Gratregression]
Die Ausgangsleistung für die kleinsten Fehlerquadrate ist mit diesen zusätzlichen Verbesserungen einigermaßen gut. Die Trainings- und Inferenzzeiten zusammen betragen nicht mehr als 20 Sekunden, um die besten Ergebnisse zu erzielen. Im nächsten Abschnitt werden Sie noch komplexere Modelle untersuchen.
Schritt 7 - Erstellen des Gesichts-Emotions-Klassifikators mithilfe eines neuronalen Faltungsnetzwerks in PyTorch
In diesem Abschnitt erstellen Sie einen zweiten Emotionsklassifikator mit neuronalen Netzen anstelle der kleinsten Quadrate. Auch hier ist unser Ziel, ein Modell zu erstellen, das Gesichter als Eingabe akzeptiert und Emotionen ausgibt. Letztendlich wird dieser Klassifikator dann bestimmen, welche Hundemaske angewendet werden soll.
Eine kurze Darstellung und Einführung in neuronale Netzwerke finden Sie im Artikel Understanding Neural Networks. Hier verwenden wir eine Deep-Learning-Bibliothek namens PyTorch. Es gibt eine Reihe von tief lernenden Bibliotheken, die weit verbreitet sind und jeweils verschiedene Vor- und Nachteile haben. PyTorch ist ein besonders guter Ausgangspunkt. Um diesen Klassifikator für neuronale Netze zu implementieren, gehen wir wie beim Klassifikator für kleinste Quadrate erneut in drei Schritten vor:
-
Daten vorverarbeiten: One-Hot-Codierung anwenden und anschließend PyTorch-Abstraktionen anwenden.
-
Spezifizieren und trainieren Sie das Modell: Richten Sie ein neuronales Netzwerk mit PyTorch-Layern ein. Definieren Sie Optimierungs-Hyperparameter und führen Sie einen stochastischen Gradientenabstieg durch.
-
Führen Sie eine Vorhersage mit dem Modell durch: Bewerten Sie das neuronale Netzwerk.
Erstellen Sie eine neue Datei mit dem Namen "+ step_7_fer_simple.py +"
nano step_7_fer_simple.pyImportieren Sie die erforderlichen Dienstprogramme und erstellen Sie eine Python-https://www.digitalocean.com/community/tutorials/how-to-construct-classes-and-define-objects-in-python-3[class], die Ihre Daten enthält. Zur Datenverarbeitung erstellen Sie hier die Zug- und Testdatensätze. Implementieren Sie dazu die + Dataset + - Schnittstelle von PyTorch, mit der Sie die integrierte Datenpipeline von PyTorch für das Dataset zur Erkennung von Gesichtsemotionen laden und verwenden können:
step_7_fer_simple.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparse
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
passLöschen Sie den Platzhalter "+ pass" in der Klasse "+ Fer2013 Dataset". Fügen Sie stattdessen eine Funktion hinzu, die unseren Datenbehälter initialisiert:
step_7_fer_simple.py
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
...Diese Funktion beginnt mit dem Laden der Proben und Etiketten. Anschließend werden die Daten in PyTorch-Datenstrukturen eingeschlossen.
Fügen Sie direkt nach der Funktion "+ init " eine Funktion " len " hinzu, da dies für die Implementierung der Schnittstelle " Dataset +" erforderlich ist, die PyTorch erwartet:
step_7_fer_simple.py
...
def __len__(self):
return len(self._labels)Fügen Sie schließlich eine Methode + getitem + hinzu, die eine dictionary mit dem Beispiel und der Bezeichnung zurückgibt:
step_7_fer_simple.py
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}Stellen Sie sicher, dass Ihre Datei wie folgt aussieht:
step_7_fer_simple.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparse
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}Laden Sie als nächstes den Datensatz + Fer2013Dataset +. Fügen Sie nach der Klasse + Fer2013Dataset + den folgenden Code am Ende Ihrer Datei hinzu:
step_7_fer_simple.py
trainset = Fer2013Dataset('data/fer2013_train.npz')
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
testset = Fer2013Dataset('data/fer2013_test.npz')
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False)Dieser Code initialisiert das Dataset mit der von Ihnen erstellten Klasse + Fer2013Dataset +. Dann hüllt es für die Zug- und Validierungssätze den Datensatz in einen + DataLoader +. Dadurch wird das Dataset in ein später zu verwendendes iterierbares übersetzt.
Vergewissern Sie sich zur Überprüfung der Integrität, dass die Dataset-Dienstprogramme funktionieren. Erstellen Sie mit + DataLoader + einen Beispiel-Dataset-Loader und drucken Sie das erste Element dieses Loaders. Fügen Sie am Ende Ihrer Datei Folgendes hinzu:
step_7_fer_simple.py
if __name__ == '__main__':
loader = torch.utils.data.DataLoader(trainset, batch_size=2, shuffle=False)
print(next(iter(loader)))Stellen Sie sicher, dass Ihr fertiges Skript folgendermaßen aussieht:
step_7_fer_simple.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparse
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}
trainset = Fer2013Dataset('data/fer2013_train.npz')
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
testset = Fer2013Dataset('data/fer2013_test.npz')
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False)
if __name__ == '__main__':
loader = torch.utils.data.DataLoader(trainset, batch_size=2, shuffle=False)
print(next(iter(loader)))Beenden Sie Ihren Editor und führen Sie das Skript aus.
python step_7_fer_simple.pyDies gibt das folgende Paar tensors aus. Unsere Datenpipeline gibt zwei Proben und zwei Etiketten aus. Dies zeigt an, dass unsere Datenpipeline betriebsbereit ist:
Output{'image':
(0 ,0 ,.,.) =
24 32 36 ... 173 172 173
25 34 29 ... 173 172 173
26 29 25 ... 172 172 174
... ⋱ ...
159 185 157 ... 157 156 153
136 157 187 ... 152 152 150
145 130 161 ... 142 143 142
⋮
(1 ,0 ,.,.) =
20 17 19 ... 187 176 162
22 17 17 ... 195 180 171
17 17 18 ... 203 193 175
... ⋱ ...
1 1 1 ... 106 115 119
2 2 1 ... 103 111 119
2 2 2 ... 99 107 118
[torch.LongTensor of size 2x1x48x48]
, 'label':
1
1
[torch.LongTensor of size 2]
}Nachdem Sie überprüft haben, dass die Datenpipeline funktioniert, kehren Sie zu "+ step_7_fer_simple.py " zurück, um das neuronale Netzwerk und den Optimierer hinzuzufügen. Öffnen Sie " step_7_fer_simple.py +".
nano step_7_fer_simple.pyLöschen Sie zunächst die letzten drei Zeilen, die Sie in der vorherigen Iteration hinzugefügt haben:
step_7_fer_simple.py
# Delete all three linesDefinieren Sie stattdessen ein neuronales PyTorch-Netzwerk, das drei Faltungsschichten gefolgt von drei vollständig verbundenen Schichten enthält. Fügen Sie dies am Ende Ihres vorhandenen Skripts hinzu:
step_7_fer_simple.py
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 3)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return xInitialisieren Sie nun das neuronale Netzwerk, definieren Sie eine Verlustfunktion und definieren Sie Optimierungs-Hyperparameter, indem Sie den folgenden Code am Ende des Skripts hinzufügen:
step_7_fer_simple.py
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)Wir trainieren für zwei Epochen. Im Moment definieren wir ein epoch als eine Iteration des Trainings, bei der jedes Trainingsmuster genau einmal verwendet wurde.
Extrahieren Sie zuerst "+ image" und "+ label" aus dem Datensatzlader und wickeln Sie sie dann jeweils in eine PyTorch "+ Variable A" ein. Führen Sie zweitens den Vorwärtsdurchlauf aus, und führen Sie dann eine Rückübertragung durch das Verlust- und das neuronale Netzwerk durch. Fügen Sie dazu den folgenden Code am Ende Ihres Skripts hinzu:
step_7_fer_simple.py
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs = Variable(data['image'].float())
labels = Variable(data['label'].long())
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.data[0]
if i % 100 == 0:
print('[%d, %5d] loss: %.3f' % (epoch, i, running_loss / (i + 1)))Ihr Skript sollte jetzt so aussehen:
step_7_fer_simple.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparse
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}
trainset = Fer2013Dataset('data/fer2013_train.npz')
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
testset = Fer2013Dataset('data/fer2013_test.npz')
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 3)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs = Variable(data['image'].float())
labels = Variable(data['label'].long())
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.data[0]
if i % 100 == 0:
print('[%d, %5d] loss: %.3f' % (epoch, i, running_loss / (i + 1)))Speichern Sie die Datei und beenden Sie den Editor, nachdem Sie Ihren Code überprüft haben. Starten Sie dann dieses Proof-of-Concept-Training:
python step_7_fer_simple.pyIn den neuronalen Netzwerkzügen wird eine Ausgabe ähnlich der folgenden angezeigt:
Output[0, 0] loss: 1.094
[0, 100] loss: 1.049
[0, 200] loss: 1.009
[0, 300] loss: 0.963
[0, 400] loss: 0.935
[1, 0] loss: 0.760
[1, 100] loss: 0.768
[1, 200] loss: 0.775
[1, 300] loss: 0.776
[1, 400] loss: 0.767Sie können dieses Skript dann mit einer Reihe anderer PyTorch-Dienstprogramme erweitern, um Modelle zu speichern und zu laden, Trainings- und Validierungsgenauigkeiten auszugeben, einen Zeitplan für die Lernrate zu optimieren usw. Nach 20 Trainingsepochen mit einer Lernrate von 0,01 und einem Impuls von 0,9 erreicht unser neuronales Netz eine Zuggenauigkeit von 87,9% und eine Validierungsgenauigkeit von 75,5%. Dies ist eine weitere Verbesserung von 6,8% gegenüber dem bisher erfolgreichsten Ansatz mit den kleinsten Quadraten von 66,6%. . Wir werden diese zusätzlichen Schnickschnack in ein neues Skript aufnehmen.
Erstellen Sie eine neue Datei, die den endgültigen Gesichtsemotionsdetektor enthält, den Ihr Live-Kamera-Feed verwenden wird. Dieses Skript enthält den obigen Code sowie eine Befehlszeilenschnittstelle und eine einfach zu importierende Version unseres Codes, die später verwendet wird. Zusätzlich enthält es die im Voraus eingestellten Hyperparameter für ein Modell mit höherer Genauigkeit.
nano step_7_fer.pyBeginnen Sie mit den folgenden Importen. Dies entspricht unserer vorherigen Datei, enthält aber zusätzlich OpenCV als + import cv2. +
step_7_fer.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparseVerwenden Sie Ihren Code direkt unter diesen Importen aus "+ step_7_fer_simple.py +" erneut, um das neuronale Netzwerk zu definieren:
step_7_fer.py
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 3)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return xVerwenden Sie erneut den Code für das Dataset zur Erkennung von Gesichtsgefühlen aus "+ step_7_fer_simple.py +" und fügen Sie ihn dieser Datei hinzu:
step_7_fer.py
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}Definieren Sie als Nächstes einige Dienstprogramme, um die Leistung des neuronalen Netzwerks zu bewerten. Fügen Sie zunächst eine "+ evaluieren +" - Funktion hinzu, die die vorhergesagte Emotion des neuronalen Netzwerks mit der wahren Emotion für ein einzelnes Bild vergleicht:
step_7_fer.py
def evaluate(outputs: Variable, labels: Variable, normalized: bool=True) -> float:
"""Evaluate neural network outputs against non-one-hotted labels."""
Y = labels.data.numpy()
Yhat = np.argmax(outputs.data.numpy(), axis=1)
denom = Y.shape[0] if normalized else 1
return float(np.sum(Yhat == Y) / denom)Fügen Sie dann eine Funktion mit dem Namen "+ batch_evaluate +" hinzu, die die erste Funktion auf alle Bilder anwendet:
step_7_fer.py
def batch_evaluate(net: Net, dataset: Dataset, batch_size: int=500) -> float:
"""Evaluate neural network in batches, if dataset is too large."""
score = 0.0
n = dataset.X.shape[0]
for i in range(0, n, batch_size):
x = dataset.X[i: i + batch_size]
y = dataset.Y[i: i + batch_size]
score += evaluate(net(x), y, False)
return score / nDefinieren Sie nun eine Funktion mit dem Namen "+ get_image_to_emotion_predictor +", die ein Bild aufnimmt und eine vorhergesagte Emotion mithilfe eines vorab trainierten Modells ausgibt:
step_7_fer.py
def get_image_to_emotion_predictor(model_path='assets/model_best.pth'):
"""Returns predictor, from image to emotion index."""
net = Net().float()
pretrained_model = torch.load(model_path)
net.load_state_dict(pretrained_model['state_dict'])
def predictor(image: np.array):
"""Translates images into emotion indices."""
if image.shape[2] > 1:
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
frame = cv2.resize(image, (48, 48)).reshape((1, 1, 48, 48))
X = Variable(torch.from_numpy(frame)).float()
return np.argmax(net(X).data.numpy(), axis=1)[0]
return predictorFügen Sie abschließend den folgenden Code hinzu, um die Funktion "+ main +" zu definieren, mit der die anderen Dienstprogramme genutzt werden können:
step_7_fer.py
def main():
trainset = Fer2013Dataset('data/fer2013_train.npz')
testset = Fer2013Dataset('data/fer2013_test.npz')
net = Net().float()
pretrained_model = torch.load("assets/model_best.pth")
net.load_state_dict(pretrained_model['state_dict'])
train_acc = batch_evaluate(net, trainset, batch_size=500)
print('Training accuracy: %.3f' % train_acc)
test_acc = batch_evaluate(net, testset, batch_size=500)
print('Validation accuracy: %.3f' % test_acc)
if __name__ == '__main__':
main()Dadurch wird ein vortrainiertes neuronales Netzwerk geladen und dessen Leistung anhand des bereitgestellten Datensatzes zur Gesichtsemotionserkennung bewertet. Insbesondere gibt das Skript die Genauigkeit der Bilder aus, die wir für das Training verwendet haben, sowie einen separaten Satz von Bildern, die wir zu Testzwecken beiseite legen.
Stellen Sie sicher, dass Ihre Datei den folgenden Kriterien entspricht:
step_7_fer.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparse
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 3)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}
def evaluate(outputs: Variable, labels: Variable, normalized: bool=True) -> float:
"""Evaluate neural network outputs against non-one-hotted labels."""
Y = labels.data.numpy()
Yhat = np.argmax(outputs.data.numpy(), axis=1)
denom = Y.shape[0] if normalized else 1
return float(np.sum(Yhat == Y) / denom)
def batch_evaluate(net: Net, dataset: Dataset, batch_size: int=500) -> float:
"""Evaluate neural network in batches, if dataset is too large."""
score = 0.0
n = dataset.X.shape[0]
for i in range(0, n, batch_size):
x = dataset.X[i: i + batch_size]
y = dataset.Y[i: i + batch_size]
score += evaluate(net(x), y, False)
return score / n
def get_image_to_emotion_predictor(model_path='assets/model_best.pth'):
"""Returns predictor, from image to emotion index."""
net = Net().float()
pretrained_model = torch.load(model_path)
net.load_state_dict(pretrained_model['state_dict'])
def predictor(image: np.array):
"""Translates images into emotion indices."""
if image.shape[2] > 1:
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
frame = cv2.resize(image, (48, 48)).reshape((1, 1, 48, 48))
X = Variable(torch.from_numpy(frame)).float()
return np.argmax(net(X).data.numpy(), axis=1)[0]
return predictor
def main():
trainset = Fer2013Dataset('data/fer2013_train.npz')
testset = Fer2013Dataset('data/fer2013_test.npz')
net = Net().float()
pretrained_model = torch.load("assets/model_best.pth")
net.load_state_dict(pretrained_model['state_dict'])
train_acc = batch_evaluate(net, trainset, batch_size=500)
print('Training accuracy: %.3f' % train_acc)
test_acc = batch_evaluate(net, testset, batch_size=500)
print('Validation accuracy: %.3f' % test_acc)
if __name__ == '__main__':
main(Speichern Sie die Datei und beenden Sie Ihren Editor.
Laden Sie wie zuvor mit dem Gesichtsdetektor vorab trainierte Modellparameter herunter und speichern Sie sie in Ihrem Ordner "+ assets +" mit dem folgenden Befehl:
wget -O assets/model_best.pth https://github.com/alvinwan/emotion-based-dog-filter/raw/master/src/assets/model_best.pthFühren Sie das Skript aus, um das vorab trainierte Modell zu verwenden und auszuwerten:
python step_7_fer.pyDies gibt Folgendes aus:
OutputTraining accuracy: 0.879
Validation accuracy: 0.755Zu diesem Zeitpunkt haben Sie einen ziemlich genauen Gesichts-Emotions-Klassifikator erstellt. Im Wesentlichen kann unser Modell zwischen glücklichen, traurigen und überraschten Gesichtern acht Mal korrekt unterscheiden. Dies ist ein einigermaßen gutes Modell, sodass Sie nun mit diesem Gesichts-Emotions-Klassifikator bestimmen können, welche Hundemaske auf Gesichter angewendet werden soll.
Schritt 8 - Fertigstellen des emotionalen Hundefilters
Vor der Integration unseres brandneuen Gesichts-Emotions-Klassifikators benötigen wir Tiermasken zur Auswahl. Wir werden eine Dalmationsmaske und eine Schäferhundmaske verwenden:
Bild: https: //assets.digitalocean.com/articles/python3_dogfilter/HveFdkg.png [Dalmation mask] + Bild: https: //assets.digitalocean.com/articles/python3_dogfilter/E9ax7PI.png [Sheepdog mask]
Führen Sie diese Befehle aus, um beide Masken in Ihren Ordner "+ assets +" herunterzuladen:
wget -O assets/dalmation.png https://assets.digitalocean.com/articles/python3_dogfilter/E9ax7PI.png # dalmation
wget -O assets/sheepdog.png https://assets.digitalocean.com/articles/python3_dogfilter/HveFdkg.png # sheepdogVerwenden wir nun die Masken in unserem Filter. Beginnen Sie mit dem Duplizieren der Datei + step_4_dog_mask.py +:
cp step_4_dog_mask.py step_8_dog_emotion_mask.pyÖffnen Sie das neue Python-Skript.
nano step_8_dog_emotion_mask.pyFügen Sie oben im Skript eine neue Zeile ein, um die Emotionsvorhersage zu importieren:
step_8_dog_emotion_mask.py
from step_7_fer import get_image_to_emotion_predictor
...Suchen Sie dann in der Funktion "+ main () +" die folgende Zeile:
step_8_dog_emotion_mask.py
mask = cv2.imread('assets/dog.png')Ersetzen Sie es durch Folgendes, um die neuen Masken zu laden und alle Masken zu einem Tupel zu aggregieren:
step_8_dog_emotion_mask.py
mask0 = cv2.imread('assets/dog.png')
mask1 = cv2.imread('assets/dalmation.png')
mask2 = cv2.imread('assets/sheepdog.png')
masks = (mask0, mask1, mask2)Fügen Sie einen Zeilenumbruch hinzu, und fügen Sie dann diesen Code hinzu, um die Emotionsvorhersage zu erstellen.
step_8_dog_emotion_mask.py
# get emotion predictor
predictor = get_image_to_emotion_predictor()Ihre "+ main +" - Funktion sollte jetzt mit den folgenden übereinstimmen:
step_8_dog_emotion_mask.py
def main():
cap = cv2.VideoCapture(0)
# load mask
mask0 = cv2.imread('assets/dog.png')
mask1 = cv2.imread('assets/dalmation.png')
mask2 = cv2.imread('assets/sheepdog.png')
masks = (mask0, mask1, mask2)
# get emotion predictor
predictor = get_image_to_emotion_predictor()
# initialize front face classifier
...Suchen Sie als Nächstes die folgenden Zeilen:
step_8_dog_emotion_mask.py
# apply mask
frame[y0: y1, x0: x1] = apply_mask(frame[y0: y1, x0: x1], mask)Fügen Sie die folgende Zeile unter der Zeile "+ # Apply Mask +" ein, um die entsprechende Maske mithilfe des Prädiktors auszuwählen:
step_8_dog_emotion_mask.py
# apply mask
frame[y0: y1, x0: x1] = apply_mask(frame[y0: y1, x0: x1], mask)Die fertige Datei sollte folgendermaßen aussehen:
step_8_dog_emotion_mask.py
"""Test for face detection"""
from step_7_fer import get_image_to_emotion_predictor
import numpy as np
import cv2
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)
resized_mask = cv2.resize(mask, new_mask_shape)
# Add mask to face - ensure mask is centered
face_with_mask = face.copy()
non_white_pixels = (resized_mask < 250).all(axis=2)
off_h = int((face_h - new_mask_h) / 2)
off_w = int((face_w - new_mask_w) / 2)
face_with_mask[off_h: off_h+new_mask_h, off_w: off_w+new_mask_w][non_white_pixels] = \
resized_mask[non_white_pixels]
return face_with_mask
def main():
cap = cv2.VideoCapture(0)
# load mask
mask0 = cv2.imread('assets/dog.png')
mask1 = cv2.imread('assets/dalmation.png')
mask2 = cv2.imread('assets/sheepdog.png')
masks = (mask0, mask1, mask2)
# get emotion predictor
predictor = get_image_to_emotion_predictor()
# initialize front face classifier
cascade = cv2.CascadeClassifier("assets/haarcascade_frontalface_default.xml")
while True:
# Capture frame-by-frame
ret, frame = cap.read()
frame_h, frame_w, _ = frame.shape
# Convert to black-and-white
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blackwhite = cv2.equalizeHist(gray)
rects = cascade.detectMultiScale(
blackwhite, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
for x, y, w, h in rects:
# crop a frame slightly larger than the face
y0, y1 = int(y - 0.25*h), int(y + 0.75*h)
x0, x1 = x, x + w
# give up if the cropped frame would be out-of-bounds
if x0 < 0 or y0 < 0 or x1 > frame_w or y1 > frame_h:
continue
# apply mask
mask = masks[predictor(frame[y:y+h, x: x+w])]
frame[y0: y1, x0: x1] = apply_mask(frame[y0: y1, x0: x1], mask)
# Display the resulting frame
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()Speichern und beenden Sie Ihren Editor. Starten Sie nun das Skript:
python step_8_dog_emotion_mask.pyProbieren Sie es jetzt aus! Das Lächeln wird als "glücklich" registriert und zeigt den ursprünglichen Hund. Ein neutrales Gesicht oder ein Stirnrunzeln wird als "traurig" registriert und ergibt den Dalmatiner. Ein Gesicht voller Überraschungen mit einem schönen großen Kiefer wird den Schäferhund hervorbringen.
image: https://assets.digitalocean.com/articles/python3_dogfilter/JPavHJl.gif [GIF für emotionsbasierten Hundefilter]
{kind=link}
Dies schließt unseren emotionalen Hundefilter und den Einstieg in das Computer-Sehen ab.
Fazit
In diesem Lernprogramm haben Sie einen Gesichtsdetektor und einen Hundefilter mithilfe von Computer Vision erstellt und maschinelle Lernmodelle verwendet, um Masken basierend auf erkannten Emotionen anzuwenden.
Maschinelles Lernen ist weit verbreitet. Es ist jedoch Sache des Praktikers, die ethischen Auswirkungen jeder Anwendung bei der Anwendung des maschinellen Lernens zu berücksichtigen. Die Anwendung, die Sie in diesem Lernprogramm erstellt haben, hat Spaß gemacht. Denken Sie jedoch daran, dass Sie sich beim Identifizieren von Gesichtern auf OpenCV und einen vorhandenen Datensatz verlassen haben, anstatt Ihre eigenen Daten zum Trainieren der Modelle bereitzustellen. Die verwendeten Daten und Modelle haben erhebliche Auswirkungen auf die Funktionsweise eines Programms.
Stellen Sie sich zum Beispiel eine Jobsuchmaschine vor, in der die Models mit Daten über Kandidaten geschult wurden. wie Rasse, Geschlecht, Alter, Kultur, Muttersprache oder andere Faktoren. Und vielleicht haben die Entwickler ein Modell trainiert, das die Sparsamkeit erzwingt, was dazu führt, dass der Merkmalsraum auf einen Unterraum reduziert wird, in dem das Geschlecht den größten Teil der Varianz erklärt. Infolgedessen beeinflusst das Modell die Stellensuche von Kandidaten und sogar die Auswahl von Unternehmen, die hauptsächlich auf dem Geschlecht basieren. Betrachten Sie nun komplexere Situationen, in denen das Modell weniger interpretierbar ist und Sie nicht wissen, was einer bestimmten Funktion entspricht. Weitere Informationen hierzu finden Sie unter Gleiche Chancen beim maschinellen Lernen von Professor Moritz Hardt an der UC Berkeley.
Es kann ein überwältigendes Ausmaß an Unsicherheit beim maschinellen Lernen geben. Um diese Zufälligkeit und Komplexität zu verstehen, müssen Sie sowohl mathematische Intuitionen als auch probabilistische Denkfähigkeiten entwickeln. Als Praktiker liegt es an Ihnen, sich mit den theoretischen Grundlagen des maschinellen Lernens vertraut zu machen.