Einführung
Das Paket Pythonpandaswird zur Datenmanipulation und -analyse verwendet, damit Sie auf intuitive Weise mit beschrifteten oder relationalen Daten arbeiten können.
Das Paketpandasbietet Tabellenkalkulationsfunktionen. Da Sie jedoch mit Python arbeiten, ist es viel schneller und effizienter als ein herkömmliches grafisches Tabellenkalkulationsprogramm.
In diesem Tutorial werden wir uns mit dem Einrichten eines großen Datensatzes für die Arbeit, den Funktionengroupby() undpivot_table() vonpandas und schließlich mit der Visualisierung von Daten befassen.
Um sich mit dem Paketpandasvertraut zu machen, lesen Sie unser TutorialAn Introduction to the pandas Package and its Data Structures in Python 3.
Voraussetzungen
In diesem Handbuch wird beschrieben, wie Sie mit Daten inpandas auf einem lokalen Desktop oder einem Remote-Server arbeiten. Das Arbeiten mit großen Datenmengen kann speicherintensiv sein. In beiden Fällen benötigt der Computer mindestens2GB of memory, um einige der Berechnungen in diesem Handbuch durchzuführen.
In diesem Tutorial verwenden wirJupyter Notebook, um mit den Daten zu arbeiten. Wenn Sie es noch nicht haben, sollten Sie unserentutorial to install and set up Jupyter Notebook for Python 3 folgen.
Daten einrichten
In diesem Tutorial werden wir mit Daten der US-amerikanischen Sozialversicherung zu Babynamen arbeiten, die inSocial Security websiteals 8-MB-Zip-Datei verfügbar sind.
Aktivieren Sie unsere Python 3-Programmierumgebung auf unserenlocal machine oder auf unserenserver aus dem richtigen Verzeichnis:
cd environments. my_env/bin/activateErstellen wir nun ein neues Verzeichnis für unser Projekt. Wir können esnames nennen und dann in das Verzeichnis wechseln:
mkdir names
cd namesIn diesem Verzeichnis können wir die Zip-Datei mit dem Befehlcurl von der Social Security-Website abrufen:
curl -O https://www.ssa.gov/oact/babynames/names.zipÜberprüfen Sie nach dem Herunterladen der Datei, ob alle Pakete installiert sind, die wir verwenden werden:
-
numpyzur Unterstützung mehrdimensionaler Arrays -
matplotlibzur Visualisierung von Daten -
pandasfür unsere Datenanalyse -
seaborn, um unsere statistischen Matplotlib-Grafiken ästhetischer zu gestalten
Wenn Sie noch keines der Pakete installiert haben, installieren Sie sie mitpip, wie in:
pip install pandas
pip install matplotlib
pip install seabornDas Paketnumpywird auch installiert, wenn Sie es noch nicht haben.
Jetzt können wir Jupyter Notebook starten:
jupyter notebookSobald Sie sich auf der Weboberfläche von Jupyter Notebook befinden, wird dort die Dateinames.zipangezeigt.
Um eine neue Notebook-Datei zu erstellen, wählen Sie im Pulldown-Menü oben rechtsNew>Python 3 aus:
Dies öffnet ein Notizbuch.
Beginnen wir mitimportingder Pakete, die wir verwenden werden. Am oberen Rand unseres Notizbuchs sollten wir Folgendes schreiben:
import numpy as np
import matplotlib.pyplot as pp
import pandas as pd
import seabornWir können diesen Code ausführen und in einen neuen Codeblock wechseln, indem wirALT + ENTER eingeben.
Lassen Sie uns auch Python Notebook anweisen, unsere Diagramme inline zu halten:
matplotlib inlineFühren Sie den Code aus und geben SieALT + ENTER ein.
Von hier aus werden wir das Zip-Archiv dekomprimieren, das CSV-Dataset inpandas laden und dannpandasDataFrames verketten.
Zip-Archiv dekomprimieren
Um das Zip-Archiv in das aktuelle Verzeichnis zu dekomprimieren, importieren wir das Modulzipfile und rufen dann die FunktionZipFile mit dem Namen der Datei auf (in unserem Fallnames.zip):
import zipfile
zipfile.ZipFile('names.zip').extractall('.')Wir können den Code ausführen und fortfahren, indem wirALT + ENTER eingeben.
Wenn Sie jetzt in das Verzeichnisnameszurückblicken, haben Sie.txt Dateien mit Namensdaten im CSV-Format. Diese Dateien entsprechen den Daten für die Jahre 1881 bis 2015. Jede dieser Dateien folgt einer ähnlichen Namenskonvention. Die Datei 2015 heißt beispielsweiseyob2015.txt, während die Datei 1927yob1927.txt heißt.
Um sich das Format einer dieser Dateien anzusehen, öffnen wir eine mit Python und zeigen die ersten fünf Zeilen an:
open('yob2015.txt','r').readlines()[:5]Führen Sie den Code aus und fahren Sie mitALT + ENTER fort.
Output['Emma,F,20355\n',
'Olivia,F,19553\n',
'Sophia,F,17327\n',
'Ava,F,16286\n',
'Isabella,F,15504\n']Die Art und Weise, wie die Daten formatiert werden, ist der Name zuerst (wie inEmma oderOlivia), das Geschlecht als nächstes (wie inF für den weiblichen Namen undM für den männlichen Namen). und dann die Anzahl der Babys, die in diesem Jahr mit diesem Namen geboren wurden (es gab 20.355 Babys namens Emma, die 2015 geboren wurden).
Mit diesen Informationen können wir die Daten inpandas laden.
Laden Sie CSV-Daten inpandas
Um durch Kommas getrennte Wertedaten inpandas zu laden, verwenden wir die Funktionpd.read_csv() und übergeben den Namen der Textdatei sowie die Spaltennamen, für die wir uns entscheiden. Wir weisen dies einer Variablen zu, in diesem Fallnames2015, da wir die Daten aus der Geburtsjahresdatei 2015 verwenden.
names2015 = pd.read_csv('yob2015.txt', names = ['Name', 'Sex', 'Babies'])Geben SieALT + ENTER ein, um den Code auszuführen und fortzufahren.
Um sicherzustellen, dass dies funktioniert, zeigen wir den oberen Rand der Tabelle an:
names2015.head()Wenn wir den Code ausführen und mitALT + ENTER fortfahren, sehen wir eine Ausgabe, die folgendermaßen aussieht:

Unsere Tabelle enthält jetzt Informationen zu Namen, Geschlecht und Anzahl der Babys, die mit jedem Namen geboren wurden, geordnet nach Spalten.
Verketten Siepandas Objekte
Durch die Verkettung derpandas-Objekte können wir mit allen separaten Textdateien imnames-Verzeichnis arbeiten.
Um diese zu verketten, müssen wir zuerst eine Liste initialisieren, indem wir einem nicht ausgefülltenlist data typeeine Variable zuweisen:
all_years = []Sobald wir dies getan haben, werden wir einfor loop verwenden, um alle Dateien nach Jahr zu durchlaufen, die von 1880 bis 2015 reichen. Wir werden+1 bis Ende 2015 hinzufügen, damit 2015 in die Schleife aufgenommen wird.
all_years = []
for year in range(1880, 2015+1):Innerhalb der Schleife werden wir jeden Wert der Textdatei an die Liste anhängen und einstring formatter verwenden, um die verschiedenen Namen jeder dieser Dateien zu verarbeiten. Wir übergeben diese Werte an die Variableyear. Auch hier geben wir Spalten fürName,Sex und die Anzahl vonBabies an:
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))Zusätzlich erstellen wir für jedes Jahr eine Spalte, um die Reihenfolge beizubehalten. Dies können wir nach jeder Iteration tun, indem wir den Index von-1 verwenden, um im Verlauf der Schleife auf sie zu zeigen.
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
all_years[-1]['Year'] = yearSchließlich fügen wir es mit der Funktionpd.concat() dem Objektpandasmit Verkettung hinzu. Wir werden die Variableall_names verwenden, um diese Informationen zu speichern.
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
all_years[-1]['Year'] = year
all_names = pd.concat(all_years)Wir können die Schleife jetzt mitALT + ENTER ausführen und dann die Ausgabe überprüfen, indem wir den Schwanz (die untersten Zeilen) der resultierenden Tabelle aufrufen:
all_names.tail()
Unser Datensatz ist jetzt vollständig und bereit, zusätzliche Arbeiten inpandas auszuführen.
Daten gruppieren
Mitpandas können Sie Daten mit der Funktion.groupby() nach Spalten gruppieren. Mit unserer Variablenall_names für unseren vollständigen Datensatz können wirgroupby() verwenden, um die Daten in verschiedene Buckets aufzuteilen.
Gruppieren wir den Datensatz nach Geschlecht und Jahr. Wir können das so einrichten:
group_name = all_names.groupby(['Sex', 'Year'])Wir können den Code ausführen und mitALT + ENTER fortfahren.
Wenn wir an dieser Stelle nur die Variablegroup_nameaufrufen, erhalten wir folgende Ausgabe:
OutputDies zeigt uns, dass es sich um einDataFrameGroupBy-Objekt handelt. Dieses Objekt enthält Anweisungen zum Gruppieren der Daten, jedoch keine Anweisungen zum Anzeigen der Werte.
Um Werte anzuzeigen, müssen wir Anweisungen geben. Wir können beispielsweise.size(),.mean() und.sum() berechnen, um eine Tabelle zurückzugeben.
Beginnen wir mit.size():
group_name.size()Wenn wir den Code ausführen und mitALT + ENTER fortfahren, sieht unsere Ausgabe folgendermaßen aus:
OutputSex Year
F 1880 942
1881 938
1882 1028
1883 1054
1884 1172
...Diese Daten sehen gut aus, könnten aber besser lesbar sein. Wir können es lesbarer machen, indem wir die Funktion.unstackanhängen:
group_name.size().unstack()Wenn wir nun den Code ausführen und mit der Eingabe vonALT + ENTER fortfahren, sieht die Ausgabe folgendermaßen aus:

Aus diesen Daten geht hervor, wie viele weibliche und männliche Namen es pro Jahr gab. Im Jahr 1889 gab es zum Beispiel 1.479 weibliche und 1.111 männliche Namen. Im Jahr 2015 gab es 18.993 weibliche und 13.959 männliche Namen. Dies zeigt, dass die Namensvielfalt im Laufe der Zeit zunimmt.
Wenn wir die Gesamtzahl der geborenen Babys erhalten möchten, können wir die.sum()-Funktion verwenden. Wenden wir das auf einen kleineren Datensatz an, dennames2015, der aus der zuvor erstellten einzelnenyob2015.txt-Datei festgelegt wurde:
names2015.groupby(['Sex']).sum()Geben SieALT + ENTER ein, um den Code auszuführen und fortzufahren:
 ) .sum () Ausgabe]
) .sum () Ausgabe]
Dies zeigt uns die Gesamtzahl der 2015 geborenen männlichen und weiblichen Babys, obwohl nur Babys im Datensatz gezählt werden, deren Name mindestens fünfmal in diesem Jahr verwendet wurde.
Mit der Funktionpandas.groupby() können wir unsere Daten in aussagekräftige Gruppen unterteilen.
Pivot-Tabelle
Pivot-Tabellen sind nützlich, um Daten zusammenzufassen. Sie können Daten, die in einer Tabelle gespeichert sind, automatisch sortieren, zählen, summieren oder mitteln. Anschließend können sie die Ergebnisse dieser Aktionen in einer neuen Tabelle dieser zusammengefassten Daten anzeigen.
Inpandas wird die Funktionpivot_table() zum Erstellen von Pivot-Tabellen verwendet.
Um eine Pivot-Tabelle zu erstellen, rufen wir zuerst den DataFrame auf, mit dem wir arbeiten möchten, dann die Daten, die wir anzeigen möchten, und wie sie gruppiert sind.
In diesem Beispiel arbeiten wir mit denall_names-Daten und zeigen die Babies-Daten, gruppiert nach Name in einer Dimension und Jahr in der anderen:
pd.pivot_table(all_names, 'Babies', 'Name', 'Year')Wenn wirALT + ENTER eingeben, um den Code auszuführen und fortzufahren, wird die folgende Ausgabe angezeigt:
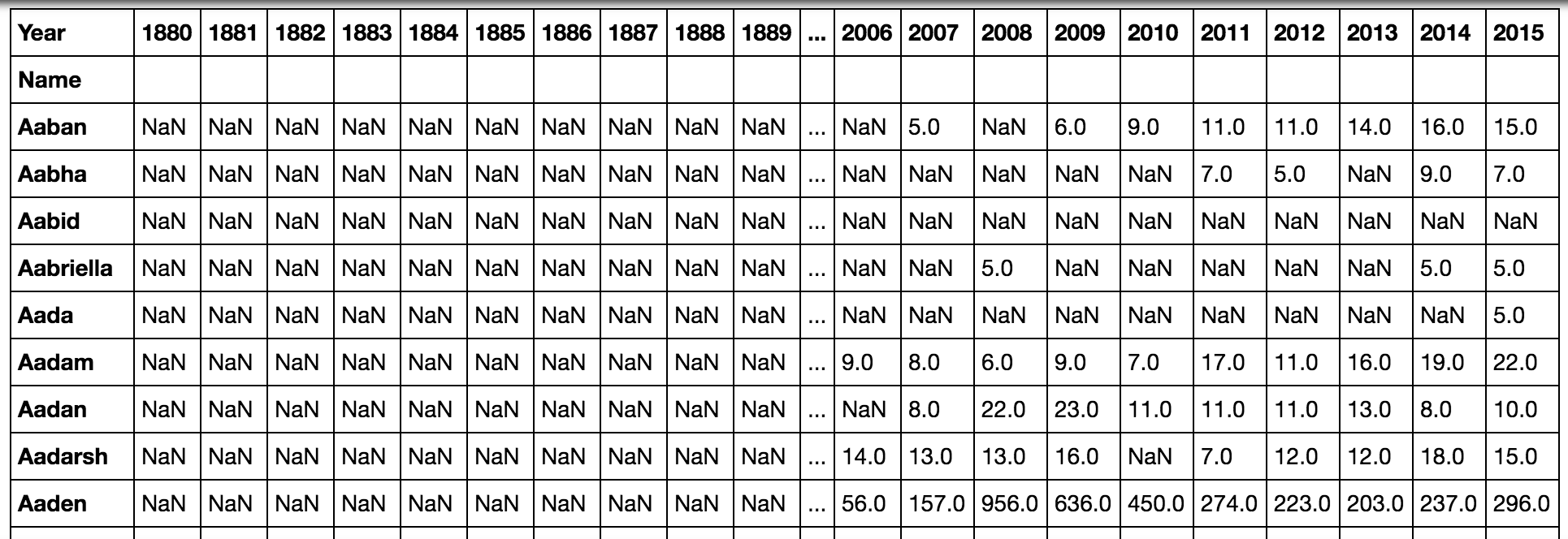
Da hier viele leere Werte angezeigt werden, möchten wir möglicherweise Name und Jahr als Spalten und nicht als Zeilen in einem Fall und Spalten in dem anderen behalten. Wir können das tun, indem wir die Daten in eckigen Klammern gruppieren:
pd.pivot_table(all_names, 'Babies', ['Name', 'Year'])Sobald wirALT + ENTER eingeben, um den Code auszuführen und fortzufahren, werden in dieser Tabelle nur Daten für Jahre angezeigt, die für jeden Namen aufgezeichnet wurden:
OutputName Year
Aaban 2007 5.0
2009 6.0
2010 9.0
2011 11.0
2012 11.0
2013 14.0
2014 16.0
2015 15.0
Aabha 2011 7.0
2012 5.0
2014 9.0
2015 7.0
Aabid 2003 5.0
Aabriella 2008 5.0
2014 5.0
2015 5.0Zusätzlich können wir Daten gruppieren, um Name und Geschlecht als eine Dimension und Jahr auf der anderen zu haben, wie in:
pd.pivot_table(all_names, 'Babies', ['Name', 'Sex'], 'Year')Wenn wir den Code ausführen und mitALT + ENTER fortfahren, wird die folgende Tabelle angezeigt:
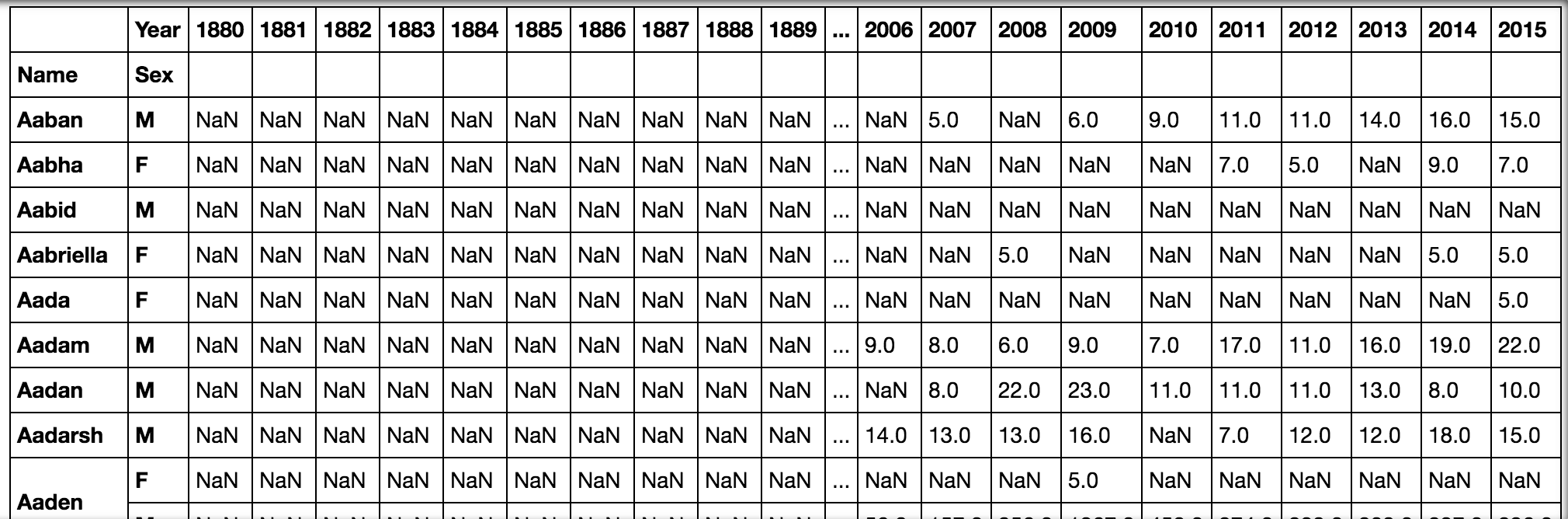 , 'Jahr') Ausgabe]
, 'Jahr') Ausgabe]
Mit Pivot-Tabellen können wir neue Tabellen aus vorhandenen Tabellen erstellen und so entscheiden, wie wir diese Daten gruppieren möchten.
Daten visualisieren
Durch die Verwendung vonpandas mit anderen Paketen wiematplotlib können wir Daten in unserem Notizbuch visualisieren.
Wir visualisieren Daten über die Popularität eines bestimmten Namens im Laufe der Jahre. Dazu müssen wir Indizes festlegen und sortieren, um die Daten zu überarbeiten, mit denen wir die sich ändernde Beliebtheit eines bestimmten Namens erkennen können.
Mit dem Paketpandaskönnen wir eine hierarchische oder mehrstufige Indizierung durchführen, mit der wir Daten mit einer beliebigen Anzahl von Dimensionen speichern und bearbeiten können.
Wir indizieren unsere Daten mit Informationen zu Geschlecht, Name und Jahr. Wir wollen auch den Index sortieren:
all_names_index = all_names.set_index(['Sex','Name','Year']).sort_index()Geben SieALT + ENTER ein, um die nächste Zeile auszuführen, in der das Notizbuch den neuen indizierten DataFrame anzeigt:
all_names_indexFühren Sie den Code aus und fahren Sie mitALT + ENTER fort. Die Ausgabe sieht folgendermaßen aus:

Als nächstes wollen wir eine Funktion schreiben, die die Popularität eines Namens im Laufe der Zeit aufzeichnet. Wir rufen die Funktionname_plot auf und übergebensex undname als Parameter, die wir beim Ausführen der Funktion aufrufen.
def name_plot(sex, name):Wir richten jetzt eine Variable namensdata ein, die die von uns erstellte Tabelle enthält. Wir werden auch den DataFrameloc vonpandasverwenden, um unsere Zeile anhand des Indexwerts auszuwählen. In unserem Fall möchten wir, dassloc auf einer Kombination von Feldern im MultiIndex basiert, die sich sowohl auf die Daten vonsex als auch vonnamebeziehen.
Schreiben wir diese Konstruktion in unsere Funktion:
def name_plot(sex, name):
data = all_names_index.loc[sex, name]Schließlich möchten wir die Werte mitmatplotlib.pyplot zeichnen, die wir alspp importiert haben. Wir werden dann die Werte der Geschlechts- und Namensdaten gegen den Index zeichnen, der für unsere Zwecke Jahre ist.
def name_plot(sex, name):
data = all_names_index.loc[sex, name]
pp.plot(data.index, data.values)Geben SieALT + ENTER ein, um die nächste Zelle auszuführen. Wir können die Funktion jetzt mit dem Geschlecht und dem Namen unserer Wahl aufrufen, z. B.F für den weiblichen Namen mit dem angegebenen NamenDanica.
name_plot('F', 'Danica')Wenn Sie jetztALT + ENTER eingeben, erhalten Sie die folgende Ausgabe:
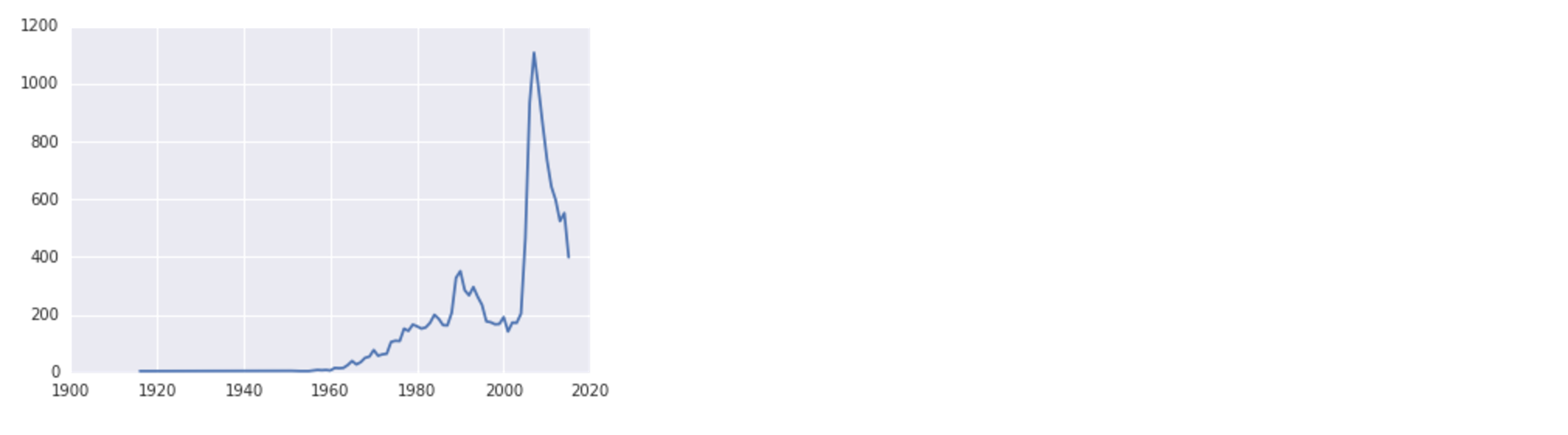
Beachten Sie, dass je nach verwendetem System möglicherweise eine Warnung bezüglich einer Schriftartersetzung angezeigt wird, die Daten jedoch weiterhin korrekt dargestellt werden.
In der Visualisierung können wir sehen, dass der weibliche Name Danica um 1990 einen kleinen Anstieg in der Beliebtheit hatte und kurz vor 2010 seinen Höhepunkt erreichte.
Die von uns erstellte Funktion kann verwendet werden, um Daten von mehr als einem Namen zu zeichnen, sodass wir Trends über die Zeit hinweg über verschiedene Namen hinweg sehen können.
Beginnen wir damit, unser Grundstück etwas größer zu machen:
pp.figure(figsize = (18, 8))Als nächstes erstellen wir eine Liste mit allen Namen, die wir zeichnen möchten:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']Jetzt können wir die Liste mit einerfor-Schleife durchlaufen und die Daten für jeden Namen zeichnen. Zunächst werden wir diese geschlechtsneutralen Namen als weibliche Namen ausprobieren:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('F', name)Fügen Sie zum besseren Verständnis dieser Daten eine Legende hinzu:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('F', name)
pp.legend(names)Wir gebenALT + ENTER ein, um den Code auszuführen und fortzufahren, und erhalten dann die folgende Ausgabe:
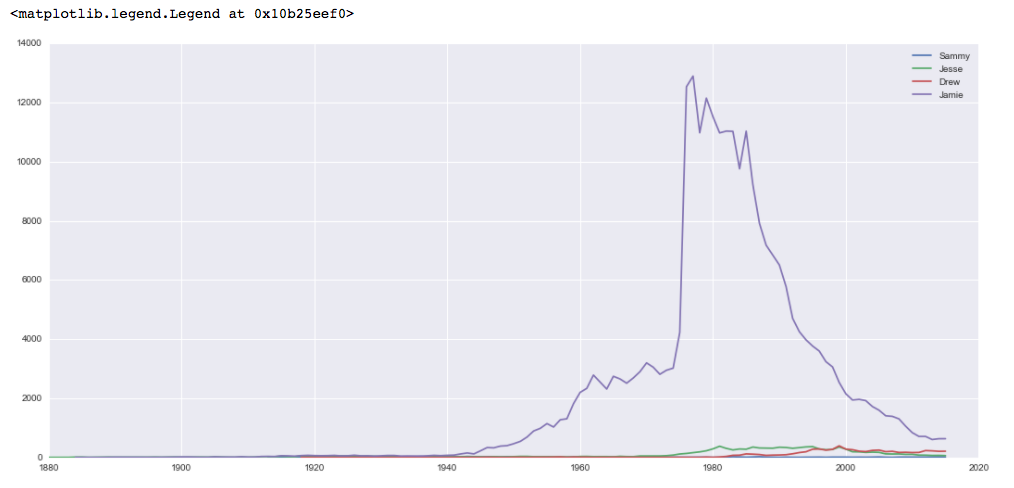
Während jeder der Namen als Frauennamen langsam an Beliebtheit gewonnen hat, war der Name Jamie in den Jahren um 1980 als Frauenname überwältigend beliebt.
Zeichnen wir die gleichen Namen, aber diesmal als männliche Namen:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('M', name)
pp.legend(names)Geben Sie erneutALT + ENTER ein, um den Code auszuführen und fortzufahren. Das Diagramm sieht folgendermaßen aus:
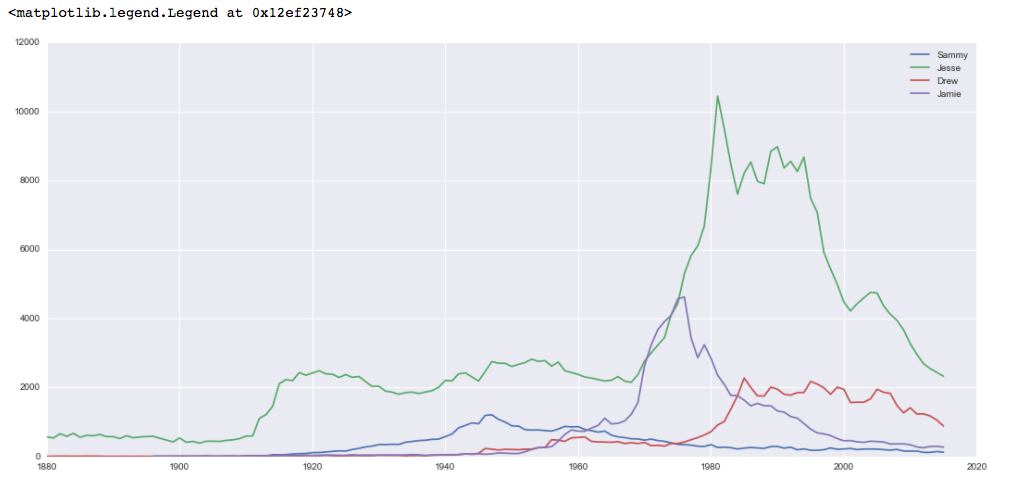
Diese Daten sind namentlich beliebter, wobei Jesse im Allgemeinen die beliebteste und in den 1980er und 1990er Jahren besonders beliebte Wahl ist.
Von hier aus können Sie weiter mit Namensdaten spielen, Visualisierungen über verschiedene Namen und deren Beliebtheit erstellen und andere Skripte erstellen, um die zu visualisierenden Daten zu betrachten.
Fazit
Dieses Tutorial führte Sie in die Arbeitsweise mit großen Datenmengen ein, angefangen beim Einrichten der Daten über das Gruppieren der Daten mitgroupby() undpivot_table(), das Indizieren der Daten mit einem MultiIndex bis hin zur Visualisierung der Daten vonpandasmit dem Paketmatplotlib.
Viele Organisationen und Institutionen bieten Datensätze an, mit denen Sie arbeiten können, um weiterhin mehr überpandas und Datenvisualisierung zu erfahren. Die US-Regierung liefert Daten beispielsweise überdata.gov.
Weitere Informationen zum Visualisieren von Daten mitmatplotlib finden Sie in unseren Anleitungen zuHow to Plot Data in Python 3 Using matplotlib undHow To Graph Word Frequency Using matplotlib with Python 3.