Async IO in Python: Eine vollständige exemplarische Vorgehensweise
Async IO ist ein gleichzeitiges Programmierdesign, das in Python dedizierte Unterstützung erhalten hat und sich schnell von Python 3.4 bis 3.7 undprobably beyond entwickelt.
Sie denken vielleicht mit Furcht: „Parallelität, Parallelität, Threading, Multiprocessing. Das ist schon viel zu verstehen. Wo passt asynchrones E / A hin? “
Dieses Tutorial soll Ihnen bei der Beantwortung dieser Frage helfen und Ihnen einen besseren Einblick in Pythons Ansatz zur asynchronen E / A geben.
Folgendes werden Sie behandeln:
-
Asynchronous IO (async IO): Ein sprachunabhängiges Paradigma (Modell), das Implementierungen in einer Vielzahl von Programmiersprachen aufweist
-
async/await: Zwei neue Python-Schlüsselwörter, mit denen Coroutinen definiert werden -
asyncio: Das Python-Paket, das eine Grundlage und API zum Ausführen und Verwalten von Coroutinen bietet
Coroutinen (spezialisierte Generatorfunktionen) sind das Herzstück von asynchronem E / A in Python, und wir werden später darauf eingehen.
Note: In diesem Artikel verwende ich den Begriffasync IO, um das sprachunabhängige Design von asynchronen E / A zu bezeichnen, während sichasyncio auf das Python-Paket bezieht.
Bevor Sie beginnen, müssen Sie sicherstellen, dass Sie für die Verwendung vonasyncio und anderen in diesem Lernprogramm enthaltenen Bibliotheken eingerichtet sind.
Free Bonus:5 Thoughts On Python Mastery, ein kostenloser Kurs für Python-Entwickler, der Ihnen die Roadmap und die Denkweise zeigt, die Sie benötigen, um Ihre Python-Fähigkeiten auf die nächste Stufe zu bringen.
Einrichten Ihrer Umgebung
Sie benötigen Python 3.7 oder höher, um diesen Artikel vollständig zu befolgen, sowie die Paketeaiohttp undaiofiles:
$ python3.7 -m venv ./py37async
$ source ./py37async/bin/activate # Windows: .\py37async\Scripts\activate.bat
$ pip install --upgrade pip aiohttp aiofiles # Optional: aiodnsWeitere Informationen zur Installation von Python 3.7 und zum Einrichten einer virtuellen Umgebung finden Sie unterPython 3 Installation & Setup Guide oderVirtual Environments Primer.
Lassen Sie uns damit einspringen.
Die 10.000-Fuß-Ansicht von Async IO
Async IO ist etwas weniger bekannt als seine bewährten Cousins Multiprocessing und Threading. In diesem Abschnitt erhalten Sie ein umfassenderes Bild davon, was asynchrones E / A ist und wie es in die umgebende Landschaft passt.
Wo passt Async IO hin?
Parallelität und Parallelität sind expansive Themen, in die man nicht leicht hineinwaten kann. Während sich dieser Artikel auf asynchrone E / A und deren Implementierung in Python konzentriert, lohnt es sich, sich eine Minute Zeit zu nehmen, um asynchrone E / A mit ihren Gegenstücken zu vergleichen, um einen Kontext darüber zu erhalten, wie asynchrone E / A in das größere, manchmal schwindelerregende Rätsel passt.
Parallelism besteht aus der gleichzeitigen Ausführung mehrerer Operationen. Multiprocessing ist ein Mittel, um Parallelität zu bewirken, und beinhaltet die Verteilung von Aufgaben auf die Zentraleinheiten eines Computers (CPUs oder Kerne). Multiprocessing eignet sich gut für CPU-gebundene Aufgaben: Eng gebundenefor-Schleifen und mathematische Berechnungen fallen normalerweise in diese Kategorie.
Concurrency ist ein etwas breiterer Begriff als Parallelität. Es wird vorgeschlagen, dass mehrere Aufgaben überlappend ausgeführt werden können. (Es gibt ein Sprichwort, dass Parallelität keine Parallelität impliziert.)
Threading ist ein gleichzeitiges Ausführungsmodell, bei dem mehrerethreads abwechselnd Aufgaben ausführen. Ein Prozess kann mehrere Threads enthalten. Python hat dank seinerGIL eine komplizierte Beziehung zum Threading, aber das geht über den Rahmen dieses Artikels hinaus.
Was Sie über Threading wissen müssen, ist, dass es für E / A-gebundene Aufgaben besser ist. Während eine CPU-gebundene Aufgabe dadurch gekennzeichnet ist, dass die Kerne des Computers von Anfang bis Ende ständig hart arbeiten, wird ein E / A-gebundener Job von vielen Wartezeiten auf die Fertigstellung der Eingabe / Ausgabe dominiert.
Zusammenfassend lässt sich sagen, dass die Parallelität sowohl Multiprocessing (ideal für CPU-gebundene Aufgaben) als auch Threading (geeignet für E / A-gebundene Aufgaben) umfasst. Multiprocessing ist eine Form der Parallelität, wobei Parallelität eine bestimmte Art (Teilmenge) der Parallelität ist. Die Python-Standardbibliothek bietet langjährigesupport for both of these über ihre Paketemultiprocessing,threading undconcurrent.futures.
Jetzt ist es Zeit, ein neues Mitglied in den Mix aufzunehmen. In den letzten Jahren wurde ein separates Design umfassender in CPython integriert: asynchrone E / A, die über das Paketasyncioder Standardbibliothek und die neuen Sprachschlüsselwörterasync undawaitaktiviert werden. Async IO ist kein neu erfundenes Konzept. Es existiert oder wird in andere Sprachen und Laufzeitumgebungen wieGo,C# oderScala integriert.
Dasasyncio-Paket wird von der Python-Dokumentation alsa library to write concurrent code in Rechnung gestellt. Async IO ist jedoch weder Threading noch Multiprocessing. Es ist nicht auf beiden aufgebaut.
Tatsächlich handelt es sich bei asynchronem E / A um ein Single-Threaded-Single-Process-Design: Es verwendetcooperative multitasking, einen Begriff, den Sie am Ende dieses Lernprogramms ausarbeiten werden. Mit anderen Worten, es wurde gesagt, dass asynchrone E / A trotz der Verwendung eines einzelnen Threads in einem einzelnen Prozess ein Gefühl der Parallelität vermittelt. Coroutinen (ein zentrales Merkmal von asynchronem E / A) können gleichzeitig geplant werden, sind jedoch nicht von Natur aus gleichzeitig.
Um es noch einmal zu wiederholen: Async IO ist ein Stil der gleichzeitigen Programmierung, aber keine Parallelität. Es ist enger an Threading als an Multiprocessing ausgerichtet, unterscheidet sich jedoch stark von beiden und ist ein eigenständiges Mitglied in der Trickkiste von Concurrency.
Damit bleibt noch ein Begriff. Was bedeutet es für etwas,asynchronous zu sein? Dies ist keine strenge Definition, aber für unsere Zwecke hier kann ich mir zwei Eigenschaften vorstellen:
-
Asynchrone Routinen können pausieren, während sie auf ihr endgültiges Ergebnis warten, und andere Routinen in der Zwischenzeit ausführen lassen.
-
Asynchroner Code erleichtert über den obigen Mechanismus die gleichzeitige Ausführung. Anders ausgedrückt: Asynchroner Code vermittelt das Erscheinungsbild von Parallelität.
Hier ist ein Diagramm, um alles zusammenzustellen. Die weißen Begriffe stellen Konzepte dar, und die grünen Begriffe stellen Wege dar, wie sie implementiert oder bewirkt werden:
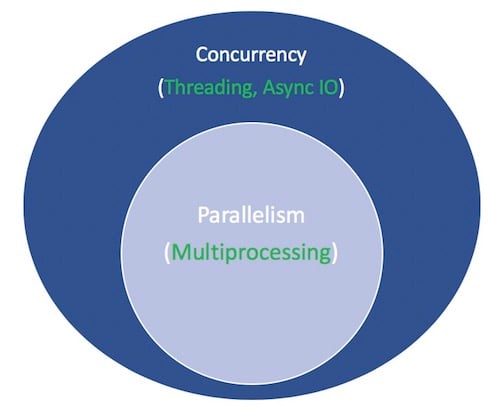
Ich werde hier bei den Vergleichen zwischen gleichzeitigen Programmiermodellen aufhören. Dieses Lernprogramm konzentriert sich auf die Unterkomponente, die asynchrone E / A ist, deren Verwendung und die APIs, die um sie herum entstanden sind. Für eine gründliche Erkundung von Threading versus Multiprocessing versus async IO, machen Sie hier eine Pause und sehen Sie sich Jim Andersonsoverview of concurrency in Python an. Jim ist viel lustiger als ich und hat in mehr Meetings als ich gesessen, um zu booten.
Async IO erklärt
Async IO mag zunächst kontraintuitiv und paradox erscheinen. Wie verwendet etwas, das gleichzeitigen Code erleichtert, einen einzelnen Thread und einen einzelnen CPU-Kern? Ich war noch nie sehr gut darin, Beispiele zu zaubern, deshalb möchte ich eines aus Miguel Grinbergs PyCon-Vortrag 2017 umschreiben, der alles sehr schön erklärt:
Schachmeisterin Judit Polgár veranstaltet eine Schachausstellung, in der sie mehrere Amateurspieler spielt. Sie hat zwei Möglichkeiten, die Ausstellung zu leiten: synchron und asynchron.
Annahmen:
24 Gegner
Judit bewegt jedes Schachspiel in 5 Sekunden
Die Gegner brauchen jeweils 55 Sekunden, um sich zu bewegen
Spiele durchschnittlich 30 Paarzüge (insgesamt 60 Züge)
Synchronous version: Judit spielt jeweils ein Spiel, niemals zwei gleichzeitig, bis das Spiel abgeschlossen ist. Jedes Spiel dauert(55 + 5) * 30 == 1800ekunden oder 30 Minuten. Die gesamte Ausstellung dauert24 * 30 == 720 Minuten oder12 hours.
Asynchronous version: Judit bewegt sich von Tisch zu Tisch und macht an jedem Tisch einen Zug. Sie verlässt den Tisch und lässt den Gegner während der Wartezeit seinen nächsten Zug machen. Ein Zug in allen 24 Spielen dauert Judit24 * 5 == 120ekunden oder 2 Minuten. Die gesamte Ausstellung ist jetzt auf120 * 30 == 3600 Sekunden oder nur1 hour reduziert. (Source)
Es gibt nur eine Judit Polgár, die nur zwei Hände hat und jeweils nur einen Zug alleine macht. Durch asynchrones Spielen wird die Ausstellungszeit jedoch von 12 Stunden auf eins verkürzt. Kooperatives Multitasking ist also eine ausgefallene Art zu sagen, dass die Ereignisschleife eines Programms (dazu später mehr) mit mehreren Aufgaben kommuniziert, damit jede abwechselnd zum optimalen Zeitpunkt ausgeführt werden kann.
Async IO benötigt lange Wartezeiten, in denen Funktionen ansonsten blockiert würden, und ermöglicht die Ausführung anderer Funktionen während dieser Ausfallzeit. (Eine Funktion, die blockiert, verhindert effektiv, dass andere vom Start bis zur Rückkehr ausgeführt werden.)
Async IO ist nicht einfach
Ich habe gehört, dass es heißt: "Verwenden Sie asynchrone E / A, wenn Sie können. Verwenden Sie Threading, wenn Sie müssen. " Die Wahrheit ist, dass das Erstellen von dauerhaftem Multithread-Code schwierig und fehleranfällig sein kann. Async IO vermeidet einige der potenziellen Geschwindigkeitsbegrenzungen, die sonst bei einem Thread-Design auftreten könnten.
Das heißt aber nicht, dass asynchrone E / A in Python einfach ist. Seien Sie gewarnt: Wenn Sie sich etwas unter die Oberfläche wagen, kann auch die asynchrone Programmierung schwierig sein! Das asynchrone Modell von Python basiert auf Konzepten wie Rückrufen, Ereignissen, Transporten, Protokollen und Zukünften - nur die Terminologie kann einschüchternd sein. Die Tatsache, dass sich die API ständig geändert hat, macht es nicht einfacher.
Glücklicherweise istasyncio bis zu einem Punkt gereift, an dem die meisten seiner Funktionen nicht mehr vorläufig sind, während die Dokumentation einer umfassenden Überarbeitung unterzogen wurde und einige Qualitätsressourcen zu diesem Thema ebenfalls auftauchen.
Dasasyncio-Paket undasync /await
Nachdem Sie nun einige Hintergrundinformationen zu Async IO als Design haben, wollen wir uns mit der Implementierung von Python befassen. Dasasyncio-Paket von Python (eingeführt in Python 3.4) und die beiden Schlüsselwörterasync undawaitdienen unterschiedlichen Zwecken, helfen Ihnen jedoch beim Deklarieren, Erstellen, Ausführen und Verwalten von asynchronem Code.
Dieasync /await Syntax und native Coroutinen
A Word of Caution: Seien Sie vorsichtig, was Sie dort im Internet lesen. Die asynchrone E / A-API von Python hat sich schnell von Python 3.4 zu Python 3.7 entwickelt. Einige alte Muster werden nicht mehr verwendet, und einige Dinge, die zuerst nicht erlaubt waren, sind jetzt durch neue Einführungen zulässig. Soweit ich weiß, wird dieses Tutorial bald auch dem Club der Veralteten beitreten.
Das Herzstück von async IO sind Coroutinen. Eine Coroutine ist eine spezielle Version einer Python-Generatorfunktion. Beginnen wir mit einer Basisliniendefinition und bauen sie dann auf, während Sie hier fortfahren: Eine Coroutine ist eine Funktion, die ihre Ausführung unterbrechen kann, bevorreturn erreicht wird, und die Kontrolle für einige Zeit indirekt an eine andere Coroutine übergeben kann.
Später werden Sie viel tiefer in die Frage eintauchen, wie genau der traditionelle Generator in eine Coroutine umgewandelt wird. Im Moment ist der einfachste Weg, um herauszufinden, wie Coroutinen funktionieren, die Herstellung einiger.
Nehmen wir den immersiven Ansatz und schreiben Sie einen asynchronen E / A-Code. Dieses kurze Programm istHello World von asynchronem E / A, trägt jedoch wesentlich zur Veranschaulichung seiner Kernfunktionalität bei:
#!/usr/bin/env python3
# countasync.py
import asyncio
async def count():
print("One")
await asyncio.sleep(1)
print("Two")
async def main():
await asyncio.gather(count(), count(), count())
if __name__ == "__main__":
import time
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"{__file__} executed in {elapsed:0.2f} seconds.")Beachten Sie beim Ausführen dieser Datei, was anders aussieht, als wenn Sie die Funktionen mit nurdef undtime.sleep() definieren würden:
$ python3 countasync.py
One
One
One
Two
Two
Two
countasync.py executed in 1.01 seconds.Die Reihenfolge dieser Ausgabe ist das Herzstück der asynchronen E / A. Bei jedem Aufruf voncount() handelt es sich um eine einzelne Ereignisschleife oder einen Koordinator. Wenn jede Aufgabeawait asyncio.sleep(1) erreicht, schreit die Funktion bis zur Ereignisschleife und gibt ihr die Kontrolle zurück. Sie sagt: "Ich werde 1 Sekunde lang schlafen." Mach weiter und lass in der Zwischenzeit etwas anderes Sinnvolles tun. “
Vergleichen Sie dies mit der synchronen Version:
#!/usr/bin/env python3
# countsync.py
import time
def count():
print("One")
time.sleep(1)
print("Two")
def main():
for _ in range(3):
count()
if __name__ == "__main__":
s = time.perf_counter()
main()
elapsed = time.perf_counter() - s
print(f"{__file__} executed in {elapsed:0.2f} seconds.")Bei der Ausführung ändert sich die Reihenfolge und Ausführungszeit geringfügig, aber kritisch:
$ python3 countsync.py
One
Two
One
Two
One
Two
countsync.py executed in 3.01 seconds.Während die Verwendung vontime.sleep() undasyncio.sleep() banal erscheint, werden sie als Ersatz für alle zeitintensiven Prozesse verwendet, die Wartezeiten erfordern. (Das Alltäglichste, worauf Sie warten können, ist einsleep()-Aufruf, der im Grunde nichts bewirkt.) Das heißt,time.sleep() kann jeden zeitaufwändigen Blockierungsfunktionsaufruf darstellen, währendasyncio.sleep() daran gewöhnt ist Stellen Sie sich für einen nicht blockierenden Anruf ein (der jedoch auch einige Zeit in Anspruch nimmt).
Wie Sie im nächsten Abschnitt sehen werden, besteht der Vorteil des Wartens auf etwas, einschließlichasyncio.sleep(), darin, dass die umgebende Funktion die Kontrolle vorübergehend an eine andere Funktion abtreten kann, die leichter in der Lage ist, sofort etwas zu tun. Im Gegensatz dazu isttime.sleep() oder ein anderer blockierender Aufruf nicht mit asynchronem Python-Code kompatibel, da er für die Dauer der Ruhezeit alles in seinen Spuren stoppt.
Die Regeln von Async IO
Zu diesem Zeitpunkt ist eine formalere Definition vonasync,await und den von ihnen erstellten Coroutine-Funktionen angebracht. Dieser Abschnitt ist etwas dicht, aber es ist wichtig,async /await zu erreichen. Kommen Sie also darauf zurück, wenn Sie Folgendes benötigen:
-
Die Syntax
async defführt entweder einnative coroutine oder einasynchronous generator ein. Die Ausdrückeasync withundasync forsind ebenfalls gültig und werden später angezeigt. -
Das Schlüsselwort
awaitgibt die Funktionssteuerung an die Ereignisschleife zurück. (Die Ausführung der umgebenden Coroutine wird angehalten.) Wenn Python im Bereichg()auf einenawait f()-Ausdruck stößt, teiltawaitder Ereignisschleife auf folgende Weise mit: „Unterbrechen Sie die Ausführung vong()bis alles, worauf ich warte - das Ergebnis vonf()- zurückgegeben wird. In der Zwischenzeit lass etwas anderes laufen. “
Im Code sieht dieser zweite Aufzählungspunkt ungefähr so aus:
async def g():
# Pause here and come back to g() when f() is ready
r = await f()
return rEs gibt auch strenge Regeln, wann und wie Sieasync /await verwenden können und wann nicht. Diese können nützlich sein, unabhängig davon, ob Sie die Syntax noch verwenden oder bereitsasync /await verwenden:
-
Eine Funktion, die Sie mit
async defeinführen, ist eine Coroutine. Es könnenawait,returnoderyieldverwendet werden, aber alle diese sind optional. Die Angabe vonasync def noop(): passist gültig:-
Durch Verwendung von
awaitund / oderreturnwird eine Coroutine-Funktion erstellt. Um eine Coroutine-Funktion aufzurufen, müssen Sieawaitverwenden, um die Ergebnisse zu erhalten. -
Es ist weniger üblich (und in Python erst seit kurzem legal),
yieldin einemasync def-Block zu verwenden. Dadurch wird einasynchronous generator erstellt, über das Sie mitasync foriterieren. Vergessen Sie vorerst asynchrone Generatoren und konzentrieren Sie sich darauf, die Syntax für Coroutine-Funktionen zu ändern, dieawaitund / oderreturnverwenden. -
Alles, was mit
async defdefiniert ist, darf nichtyield fromverwenden, wodurch einSyntaxErrorerhöht wird.
-
-
Genau wie es ein
SyntaxErrorist,yieldaußerhalb einerdef-Funktion zu verwenden, ist es einSyntaxError,awaitaußerhalb einerasync def-Coroutine zu verwenden . Sie können nurawaitim Körper von Coroutinen verwenden.
Hier sind einige knappe Beispiele, die die oben genannten Regeln zusammenfassen sollen:
async def f(x):
y = await z(x) # OK - `await` and `return` allowed in coroutines
return y
async def g(x):
yield x # OK - this is an async generator
async def m(x):
yield from gen(x) # No - SyntaxError
def m(x):
y = await z(x) # Still no - SyntaxError (no `async def` here)
return yWenn Sieawait f() verwenden, mussf() ein Objekt sein, dasawaitable ist. Das ist nicht sehr hilfreich, oder? Im Moment wissen Sie nur, dass ein zu erwartendes Objekt entweder (1) eine andere Coroutine oder (2) ein Objekt ist, das eine.__await__()-Dunder-Methode definiert, die einen Iterator zurückgibt. Wenn Sie ein Programm schreiben, sollten Sie sich für die meisten Zwecke nur um Fall 1 kümmern müssen.
Das bringt uns zu einer weiteren technischen Unterscheidung, die möglicherweise auftaucht: Eine ältere Methode zum Markieren einer Funktion als Coroutine besteht darin, eine normaledef-Funktion mit@asyncio.coroutine zu dekorieren. Das Ergebnis ist eingenerator-based coroutine. Diese Konstruktion ist veraltet, seit die Syntaxasync /awaitin Python 3.5 eingeführt wurde.
Diese beiden Coroutinen sind im Wesentlichen äquivalent (beide sind zu erwarten), aber die erste istgenerator-based, während die zweitenative coroutine ist:
import asyncio
@asyncio.coroutine
def py34_coro():
"""Generator-based coroutine, older syntax"""
yield from stuff()
async def py35_coro():
"""Native coroutine, modern syntax"""
await stuff()Wenn Sie selbst Code schreiben, bevorzugen Sie native Coroutinen, um explizit und nicht implizit zu sein. Generatorbasierte Coroutinen sind in Python 3.10removed.
In der zweiten Hälfte dieses Tutorials werden wir nur zur Erklärung auf generatorbasierte Coroutinen eingehen. Der Grund, warumasync /await eingeführt wurden, besteht darin, Coroutinen zu einer eigenständigen Funktion von Python zu machen, die leicht von einer normalen Generatorfunktion unterschieden werden kann, wodurch Mehrdeutigkeiten verringert werden.
Lassen Sie sich nicht in generatorbasierten Coroutinen festfahren, diedeliberately outdated malasync /await betragen haben. Sie haben ihre eigenen kleinen Regeln (zum Beispiel könnenawait nicht in einer generatorbasierten Coroutine verwendet werden), die weitgehend irrelevant sind, wenn Sie sich an die Syntax vonasync /awaithalten.
Nehmen wir ohne weiteres einige weitere Beispiele an.
Hier ist ein Beispiel dafür, wie asynchrone E / A die Wartezeit verkürzt: Bei einer Coroutinemakerandom(), die weiterhin zufällige Ganzzahlen im Bereich [0, 10] erzeugt, bis eine von ihnen einen Schwellenwert überschreitet, möchten Sie mehrere Aufrufe von zulassen Diese Coroutine muss nicht darauf warten, dass sie nacheinander abgeschlossen wird. Sie können den Mustern aus den beiden obigen Skripten mit geringfügigen Änderungen weitgehend folgen:
#!/usr/bin/env python3
# rand.py
import asyncio
import random
# ANSI colors
c = (
"\033[0m", # End of color
"\033[36m", # Cyan
"\033[91m", # Red
"\033[35m", # Magenta
)
async def makerandom(idx: int, threshold: int = 6) -> int:
print(c[idx + 1] + f"Initiated makerandom({idx}).")
i = random.randint(0, 10)
while i <= threshold:
print(c[idx + 1] + f"makerandom({idx}) == {i} too low; retrying.")
await asyncio.sleep(idx + 1)
i = random.randint(0, 10)
print(c[idx + 1] + f"---> Finished: makerandom({idx}) == {i}" + c[0])
return i
async def main():
res = await asyncio.gather(*(makerandom(i, 10 - i - 1) for i in range(3)))
return res
if __name__ == "__main__":
random.seed(444)
r1, r2, r3 = asyncio.run(main())
print()
print(f"r1: {r1}, r2: {r2}, r3: {r3}")Die kolorierte Ausgabe sagt viel mehr aus als ich und gibt Ihnen einen Eindruck davon, wie dieses Skript ausgeführt wird:
Dieses Programm verwendet eine Hauptkoroutine,makerandom(), und führt sie gleichzeitig über 3 verschiedene Eingänge aus. Die meisten Programme enthalten kleine, modulare Coroutinen und eine Wrapper-Funktion, mit der jede der kleineren Coroutinen miteinander verkettet wird. main() wird dann verwendet, um Aufgaben (Futures) zu erfassen, indem die zentrale Coroutine über einen iterierbaren oder Pool verteilt wird.
In diesem Miniaturbeispiel beträgt der Poolrange(3). In einem ausführlicheren Beispiel, das später vorgestellt wird, handelt es sich um eine Reihe von URLs, die gleichzeitig angefordert, analysiert und verarbeitet werden müssen, undmain() kapselt die gesamte Routine für jede URL.
Während das Erstellen von zufälligen Ganzzahlen (das mehr als alles andere an die CPU gebunden ist) als Kandidat fürasyncio möglicherweise nicht die beste Wahl ist, ist es das Vorhandensein vonasyncio.sleep() in dem Beispiel, das eine imitieren soll IO-gebundener Prozess, bei dem ungewisse Wartezeiten auftreten. Beispielsweise könnte der Aufruf vonasyncio.sleep()das Senden und Empfangen nicht so zufälliger Ganzzahlen zwischen zwei Clients in einer Nachrichtenanwendung darstellen.
Asynchrone E / A-Entwurfsmuster
Async IO enthält einen eigenen Satz möglicher Skriptdesigns, die Sie in diesem Abschnitt kennenlernen werden.
Coroutinen verketten
Ein wesentliches Merkmal von Coroutinen ist, dass sie miteinander verkettet werden können. (Denken Sie daran, dass ein Coroutine-Objekt erwartet wird, sodass eine andere Coroutine esawait kann.) Auf diese Weise können Sie Programme in kleinere, verwaltbare und recycelbare Coroutinen aufteilen:
#!/usr/bin/env python3
# chained.py
import asyncio
import random
import time
async def part1(n: int) -> str:
i = random.randint(0, 10)
print(f"part1({n}) sleeping for {i} seconds.")
await asyncio.sleep(i)
result = f"result{n}-1"
print(f"Returning part1({n}) == {result}.")
return result
async def part2(n: int, arg: str) -> str:
i = random.randint(0, 10)
print(f"part2{n, arg} sleeping for {i} seconds.")
await asyncio.sleep(i)
result = f"result{n}-2 derived from {arg}"
print(f"Returning part2{n, arg} == {result}.")
return result
async def chain(n: int) -> None:
start = time.perf_counter()
p1 = await part1(n)
p2 = await part2(n, p1)
end = time.perf_counter() - start
print(f"-->Chained result{n} => {p2} (took {end:0.2f} seconds).")
async def main(*args):
await asyncio.gather(*(chain(n) for n in args))
if __name__ == "__main__":
import sys
random.seed(444)
args = [1, 2, 3] if len(sys.argv) == 1 else map(int, sys.argv[1:])
start = time.perf_counter()
asyncio.run(main(*args))
end = time.perf_counter() - start
print(f"Program finished in {end:0.2f} seconds.")Achten Sie sorgfältig auf die Ausgabe, bei derpart1() für eine variable Zeitspanne schläft undpart2() mit den Ergebnissen arbeitet, sobald sie verfügbar sind:
$ python3 chained.py 9 6 3
part1(9) sleeping for 4 seconds.
part1(6) sleeping for 4 seconds.
part1(3) sleeping for 0 seconds.
Returning part1(3) == result3-1.
part2(3, 'result3-1') sleeping for 4 seconds.
Returning part1(9) == result9-1.
part2(9, 'result9-1') sleeping for 7 seconds.
Returning part1(6) == result6-1.
part2(6, 'result6-1') sleeping for 4 seconds.
Returning part2(3, 'result3-1') == result3-2 derived from result3-1.
-->Chained result3 => result3-2 derived from result3-1 (took 4.00 seconds).
Returning part2(6, 'result6-1') == result6-2 derived from result6-1.
-->Chained result6 => result6-2 derived from result6-1 (took 8.01 seconds).
Returning part2(9, 'result9-1') == result9-2 derived from result9-1.
-->Chained result9 => result9-2 derived from result9-1 (took 11.01 seconds).
Program finished in 11.01 seconds.In diesem Setup entspricht die Laufzeit vonmain() der maximalen Laufzeit der Aufgaben, die zusammengetragen und geplant werden.
Verwenden einer Warteschlange
Das Paketasyncio enthältqueue classes, die den Klassen des Modulsqueue ähnlich sind. In unseren bisherigen Beispielen brauchten wir eigentlich keine Warteschlangenstruktur. Inchained.py besteht jede Aufgabe (Zukunft) aus einer Reihe von Coroutinen, die explizit aufeinander warten und eine einzelne Eingabe pro Kette durchlaufen.
Es gibt eine alternative Struktur, die auch mit asynchronem E / A arbeiten kann: Eine Reihe von Produzenten, die nicht miteinander verknüpft sind, fügen einer Warteschlange Elemente hinzu. Jeder Hersteller kann der Warteschlange zu gestaffelten, zufälligen und unangekündigten Zeiten mehrere Artikel hinzufügen. Eine Gruppe von Verbrauchern zieht Artikel aus der Warteschlange, während sie gierig und ohne auf ein anderes Signal zu warten auftauchen.
Bei diesem Design gibt es keine Verkettung eines einzelnen Verbrauchers mit einem Hersteller. Die Verbraucher kennen die Anzahl der Hersteller oder sogar die kumulierte Anzahl der Artikel, die der Warteschlange hinzugefügt werden, nicht im Voraus.
Ein einzelner Hersteller oder Verbraucher benötigt eine variable Zeit, um Artikel in die Warteschlange zu stellen bzw. daraus zu extrahieren. Die Warteschlange dient als Durchsatz, der mit den Produzenten und Verbrauchern kommunizieren kann, ohne dass diese direkt miteinander sprechen.
Note: Während Warteschlangen aufgrund der Thread-Sicherheit vonqueue.Queue() häufig in Thread-Programmen verwendet werden, sollten Sie sich bei asynchronen E / A-Vorgängen nicht um die Thread-Sicherheit kümmern müssen. (Die Ausnahme ist, wenn Sie beide kombinieren, dies wird jedoch in diesem Lernprogramm nicht durchgeführt.)
Ein Anwendungsfall für Warteschlangen (wie hier) besteht darin, dass die Warteschlange als Sender für Produzenten und Verbraucher fungiert, die ansonsten nicht direkt miteinander verkettet oder verbunden sind.
Die synchrone Version dieses Programms würde ziemlich düster aussehen: Eine Gruppe blockierender Produzenten fügt der Warteschlange nacheinander Elemente hinzu, jeweils ein Produzent. Erst wenn alle Hersteller fertig sind, kann die Warteschlange von jeweils einem Verbraucher Artikel für Artikel verarbeitet werden. Es gibt eine Menge Latenz in diesem Design. Artikel können untätig in der Warteschlange stehen, anstatt sofort abgeholt und verarbeitet zu werden.
Eine asynchrone Version,asyncq.py, ist unten. Der herausfordernde Teil dieses Workflows besteht darin, dass den Verbrauchern ein Signal gegeben werden muss, dass die Produktion abgeschlossen ist. Andernfalls bleibtawait q.get() auf unbestimmte Zeit hängen, da die Warteschlange vollständig verarbeitet wurde, die Verbraucher jedoch keine Ahnung haben, dass die Produktion abgeschlossen ist.
(Vielen Dank für die Hilfe eines StackOverflowuser für die Korrektur vonmain(): Der Schlüssel istawait q.join(), der blockiert, bis alle Elemente in der Warteschlange empfangen und verarbeitet wurden, und dann, um die Verbraucheraufgaben abzubrechen, die sonst auflegen und endlos auf das Erscheinen zusätzlicher Warteschlangenelemente warten würden.)
Hier ist das vollständige Skript:
#!/usr/bin/env python3
# asyncq.py
import asyncio
import itertools as it
import os
import random
import time
async def makeitem(size: int = 5) -> str:
return os.urandom(size).hex()
async def randsleep(a: int = 1, b: int = 5, caller=None) -> None:
i = random.randint(0, 10)
if caller:
print(f"{caller} sleeping for {i} seconds.")
await asyncio.sleep(i)
async def produce(name: int, q: asyncio.Queue) -> None:
n = random.randint(0, 10)
for _ in it.repeat(None, n): # Synchronous loop for each single producer
await randsleep(caller=f"Producer {name}")
i = await makeitem()
t = time.perf_counter()
await q.put((i, t))
print(f"Producer {name} added <{i}> to queue.")
async def consume(name: int, q: asyncio.Queue) -> None:
while True:
await randsleep(caller=f"Consumer {name}")
i, t = await q.get()
now = time.perf_counter()
print(f"Consumer {name} got element <{i}>"
f" in {now-t:0.5f} seconds.")
q.task_done()
async def main(nprod: int, ncon: int):
q = asyncio.Queue()
producers = [asyncio.create_task(produce(n, q)) for n in range(nprod)]
consumers = [asyncio.create_task(consume(n, q)) for n in range(ncon)]
await asyncio.gather(*producers)
await q.join() # Implicitly awaits consumers, too
for c in consumers:
c.cancel()
if __name__ == "__main__":
import argparse
random.seed(444)
parser = argparse.ArgumentParser()
parser.add_argument("-p", "--nprod", type=int, default=5)
parser.add_argument("-c", "--ncon", type=int, default=10)
ns = parser.parse_args()
start = time.perf_counter()
asyncio.run(main(**ns.__dict__))
elapsed = time.perf_counter() - start
print(f"Program completed in {elapsed:0.5f} seconds.")Die ersten paar Coroutinen sind Hilfsfunktionen, die eine zufällige Zeichenfolge, einen Leistungszähler in Sekundenbruchteilen und eine zufällige Ganzzahl zurückgeben. Ein Produzent stellt 1 bis 5 Artikel in die Warteschlange. Jedes Element ist ein Tupel von(i, t), wobeii eine zufällige Zeichenfolge ist undt der Zeitpunkt ist, zu dem der Produzent versucht, das Tupel in die Warteschlange zu stellen.
Wenn ein Verbraucher einen Artikel herauszieht, berechnet er einfach die verstrichene Zeit, in der der Artikel in der Warteschlange stand, anhand des Zeitstempels, mit dem der Artikel eingelegt wurde.
Beachten Sie, dassasyncio.sleep() verwendet wird, um eine andere, komplexere Coroutine nachzuahmen, die Zeit verschlingt und alle anderen Ausführungen blockiert, wenn es sich um eine reguläre Blockierungsfunktion handelt.
Hier ist ein Testlauf mit zwei Herstellern und fünf Verbrauchern:
$ python3 asyncq.py -p 2 -c 5
Producer 0 sleeping for 3 seconds.
Producer 1 sleeping for 3 seconds.
Consumer 0 sleeping for 4 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 2 sleeping for 3 seconds.
Consumer 3 sleeping for 5 seconds.
Consumer 4 sleeping for 4 seconds.
Producer 0 added <377b1e8f82> to queue.
Producer 0 sleeping for 5 seconds.
Producer 1 added <413b8802f8> to queue.
Consumer 1 got element <377b1e8f82> in 0.00013 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 2 got element <413b8802f8> in 0.00009 seconds.
Consumer 2 sleeping for 4 seconds.
Producer 0 added <06c055b3ab> to queue.
Producer 0 sleeping for 1 seconds.
Consumer 0 got element <06c055b3ab> in 0.00021 seconds.
Consumer 0 sleeping for 4 seconds.
Producer 0 added <17a8613276> to queue.
Consumer 4 got element <17a8613276> in 0.00022 seconds.
Consumer 4 sleeping for 5 seconds.
Program completed in 9.00954 seconds.In diesem Fall werden die Elemente in Sekundenbruchteilen verarbeitet. Eine Verzögerung kann zwei Gründe haben:
-
Standard, weitgehend unvermeidbarer Overhead
-
Situationen, in denen alle Verbraucher schlafen, wenn ein Artikel in der Warteschlange angezeigt wird
In Bezug auf den zweiten Grund ist es glücklicherweise völlig normal, auf Hunderte oder Tausende von Verbrauchern zu skalieren. Sie sollten kein Problem mitpython3 asyncq.py -p 5 -c 100 haben. Der Punkt hier ist, dass theoretisch unterschiedliche Benutzer auf unterschiedlichen Systemen die Verwaltung von Produzenten und Verbrauchern steuern können, wobei die Warteschlange als zentraler Durchsatz dient.
Bisher wurden Sie direkt ins Feuer geworfen und haben drei verwandte Beispiele fürasyncio gesehen, die Coroutinen aufrufen, die mitasync undawait definiert sind. Wenn Sie die Mechanik der Entstehung moderner Coroutinen in Python nicht vollständig verfolgen oder nur näher darauf eingehen möchten, beginnen Sie mit dem ersten Abschnitt.
Async IOs Wurzeln in Generatoren
Zuvor haben Sie ein Beispiel für die Coroutinen auf Generatorbasis im alten Stil gesehen, die durch explizitere native Coroutinen veraltet sind. Das Beispiel ist es wert, mit einem kleinen Tweak noch einmal gezeigt zu werden:
import asyncio
@asyncio.coroutine
def py34_coro():
"""Generator-based coroutine"""
# No need to build these yourself, but be aware of what they are
s = yield from stuff()
return s
async def py35_coro():
"""Native coroutine, modern syntax"""
s = await stuff()
return s
async def stuff():
return 0x10, 0x20, 0x30Was passiert als Experiment, wenn Siepy34_coro() oderpy35_coro() alleine, ohneawait oder ohne Aufruf vonasyncio.run() oder anderemasyncio „Porzellan“ aufrufen? ”Funktionen? Wenn Sie eine Coroutine isoliert aufrufen, wird ein Coroutine-Objekt zurückgegeben:
>>>
>>> py35_coro()
Dies ist an seiner Oberfläche nicht sehr interessant. Das Ergebnis des alleinigen Aufrufs einer Coroutine ist ein zu erwartendescoroutine object.
Zeit für ein Quiz: Welche andere Funktion von Python sieht so aus? (Welche Funktion von Python macht eigentlich nicht viel, wenn es alleine aufgerufen wird?)
Hoffentlich denken Sie angenerators als Antwort auf diese Frage, da Coroutinen verbesserte Generatoren unter der Haube sind. Das Verhalten ist in dieser Hinsicht ähnlich:
>>>
>>> def gen():
... yield 0x10, 0x20, 0x30
...
>>> g = gen()
>>> g # Nothing much happens - need to iterate with `.__next__()`
>>> next(g)
(16, 32, 48) Generatorfunktionen sind zufällig die Grundlage für asynchrone E / A (unabhängig davon, ob Sie Coroutinen mitasync def und nicht mit dem älteren@asyncio.coroutine-Wrapper deklarieren). Technisch gesehen istawaityield from ähnlicher alsyield. (Aber denken Sie daran, dassyield from x() nur syntaktischer Zucker ist, umfor i in x(): yield i zu ersetzen.)
Ein kritisches Merkmal von Generatoren in Bezug auf asynchrone E / A ist, dass sie nach Belieben effektiv gestoppt und neu gestartet werden können. Beispielsweise können Siebreak nicht mehr über ein Generatorobjekt iterieren und später die Iteration für die verbleibenden Werte fortsetzen. Wenn eine Generatorfunktionyield erreicht, liefert sie diesen Wert, bleibt dann aber im Leerlauf, bis sie aufgefordert wird, ihren nachfolgenden Wert zu liefern.
Dies kann anhand eines Beispiels konkretisiert werden:
>>>
>>> from itertools import cycle
>>> def endless():
... """Yields 9, 8, 7, 6, 9, 8, 7, 6, ... forever"""
... yield from cycle((9, 8, 7, 6))
>>> e = endless()
>>> total = 0
>>> for i in e:
... if total < 30:
... print(i, end=" ")
... total += i
... else:
... print()
... # Pause execution. We can resume later.
... break
9 8 7 6 9 8 7 6 9 8 7 6 9 8
>>> # Resume
>>> next(e), next(e), next(e)
(6, 9, 8)Das Schlüsselwortawaitverhält sich ähnlich und markiert einen Haltepunkt, an dem sich die Coroutine aufhält und andere Coroutinen arbeiten lässt. "Angehalten" bedeutet in diesem Fall eine Coroutine, die die Kontrolle vorübergehend abgetreten hat, aber nicht vollständig beendet oder beendet wurde. Beachten Sie, dassyield und im weiteren Sinneyield from undawait einen Haltepunkt in der Ausführung eines Generators markieren.
Dies ist der grundlegende Unterschied zwischen Funktionen und Generatoren. Eine Funktion ist alles oder nichts. Sobald es gestartet ist, stoppt es nicht, bis es einreturn erreicht, und überträgt diesen Wert dann an den Aufrufer (die Funktion, die ihn aufruft). Ein Generator hingegen hält jedes Mal an, wenn er einyield trifft, und geht nicht weiter. Es kann diesen Wert nicht nur auf den aufrufenden Stapel übertragen, sondern auch seine lokalen Variablen behalten, wenn Sie ihn fortsetzen, indem Sienext() darauf aufrufen.
Es gibt eine zweite und weniger bekannte Funktion von Generatoren, die ebenfalls von Bedeutung ist. Sie können einen Wert auch über die.send()-Methode an einen Generator senden. Dadurch können Generatoren (und Coroutinen) sich gegenseitig anrufen (await), ohne zu blockieren. Ich werde nicht weiter auf die Grundlagen dieser Funktion eingehen, da sie hauptsächlich für die Implementierung von Coroutinen hinter den Kulissen von Bedeutung ist, aber Sie sollten sie niemals direkt selbst verwenden müssen.
Wenn Sie mehr erforschen möchten, können Sie beiPEP 342 beginnen, wo Coroutinen offiziell eingeführt wurden. Brett CannonsHow the Heck Does Async-Await Work in Python ist ebenso eine gute Lektüre wie diePYMOTW writeup on asyncio. Schließlich gibt es noch David BeazleysCurious Course on Coroutines and Concurrency, die tief in den Mechanismus eintauchen, mit dem Coroutinen laufen.
Versuchen wir, alle oben genannten Artikel in ein paar Sätzen zusammenzufassen: Es gibt einen besonders unkonventionellen Mechanismus, mit dem diese Coroutinen tatsächlich ausgeführt werden. Ihr Ergebnis ist ein Attribut des Ausnahmeobjekts, das beim Aufruf der Methode.send()ausgelöst wird. All dies hat einige weitere Details, aber es wird Ihnen wahrscheinlich nicht helfen, diesen Teil der Sprache in der Praxis zu verwenden. Lassen Sie uns also vorerst fortfahren.
Um die Dinge zusammenzubinden, hier einige wichtige Punkte zum Thema Coroutinen als Generatoren:
-
Coroutinen sindrepurposed generators, die die Besonderheiten der Generatormethoden ausnutzen.
-
Alte generatorbasierte Coroutinen verwenden
yield from, um auf ein Coroutinenergebnis zu warten. Die moderne Python-Syntax in nativen Coroutinen ersetzt einfachyield fromdurchawait, um auf ein Coroutine-Ergebnis zu warten.awaitist analog zuyield from, und es hilft oft, es als solches zu betrachten. -
Die Verwendung von
awaitist ein Signal, das einen Haltepunkt markiert. Dadurch kann eine Coroutine die Ausführung vorübergehend unterbrechen und das Programm kann später darauf zurückgreifen.
Weitere Funktionen:async for und Async-Generatoren + Verständnis
Neben einfachenasync /await ermöglicht Python auchasync for, überasynchronous iterator zu iterieren. Der Zweck eines asynchronen Iterators besteht darin, dass er in jeder Phase, in der er iteriert wird, asynchronen Code aufrufen kann.
Eine natürliche Erweiterung dieses Konzepts ist einasynchronous generator. Denken Sie daran, dass Sieawait,return oderyield in einer nativen Coroutine verwenden können. Die Verwendung vonyield innerhalb einer Coroutine wurde in Python 3.6 (über PEP 525) möglich, mit dem asynchrone Generatoren eingeführt wurden, um die Verwendung vonawait undyield in demselben Coroutine-Funktionskörper zu ermöglichen:
>>>
>>> async def mygen(u: int = 10):
... """Yield powers of 2."""
... i = 0
... while i < u:
... yield 2 ** i
... i += 1
... await asyncio.sleep(0.1)Last but not least aktiviert Pythonasynchronous comprehension mitasync for. Wie sein synchroner Cousin ist dies größtenteils syntaktischer Zucker:
>>>
>>> async def main():
... # This does *not* introduce concurrent execution
... # It is meant to show syntax only
... g = [i async for i in mygen()]
... f = [j async for j in mygen() if not (j // 3 % 5)]
... return g, f
...
>>> g, f = asyncio.run(main())
>>> g
[1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
>>> f
[1, 2, 16, 32, 256, 512]Dies ist eine entscheidende Unterscheidung:neither asynchronous generators nor comprehensions make the iteration concurrent. Alles, was sie tun, ist das Erscheinungsbild ihrer synchronen Gegenstücke, aber mit der Möglichkeit, dass die betreffende Schleife die Kontrolle über die Ereignisschleife aufgibt, damit eine andere Coroutine ausgeführt werden kann.
Mit anderen Worten, asynchrone Iteratoren und asynchrone Generatoren sind nicht dafür ausgelegt, eine Funktion gleichzeitig über eine Sequenz oder einen Iterator abzubilden. Sie sind lediglich so konzipiert, dass die umschließende Coroutine es anderen Aufgaben ermöglicht, an die Reihe zu kommen. Die Anweisungenasync for undasync with werden nur insoweit benötigt, als die Verwendung von einfachenfor oderwith die Natur vonawait in der Coroutine „brechen“ würde. Diese Unterscheidung zwischen Asynchronität und Parallelität ist von entscheidender Bedeutung.
Die Ereignisschleife undasyncio.run()
Sie können sich eine Ereignisschleife als einewhile True-Schleife vorstellen, die Coroutinen überwacht, Feedback zum Leerlauf erhält und sich nach Dingen umschaut, die in der Zwischenzeit ausgeführt werden können. Es ist in der Lage, eine inaktive Coroutine zu aktivieren, wenn das verfügbar ist, worauf diese Coroutine wartet.
Bisher wurde die gesamte Verwaltung der Ereignisschleife implizit von einem Funktionsaufruf übernommen:
asyncio.run(main()) # Python 3.7+asyncio.run(), eingeführt in Python 3.7, ist dafür verantwortlich, die Ereignisschleife abzurufen, Aufgaben auszuführen, bis sie als abgeschlossen markiert sind, und dann die Ereignisschleife zu schließen.
Es gibt eine langwierigere Möglichkeit, die Ereignisschleife vonasynciomitget_event_loop()zu verwalten. Das typische Muster sieht folgendermaßen aus:
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(main())
finally:
loop.close()In älteren Beispielen werden wahrscheinlichloop.get_event_loop() herumschweben, aber wenn Sie nicht die Kontrolle über die Verwaltung der Ereignisschleife genau einstellen müssen, solltenasyncio.run() für die meisten Programme ausreichen.
Wenn Sie innerhalb eines Python-Programms mit der Ereignisschleife interagieren müssen, istloop ein altmodisches Python-Objekt, das die Introspektion mitloop.is_running() undloop.is_closed() unterstützt. Sie können es manipulieren, wenn Sie eine genauere Steuerung benötigen, z. B. inscheduling a callback, indem Sie die Schleife als Argument übergeben.
Entscheidender ist es, ein wenig unter der Oberfläche die Mechanik der Ereignisschleife zu verstehen. Hier sind einige Punkte, die es wert sind, über die Ereignisschleife hervorgehoben zu werden.
#1: Coroutinen machen nicht viel alleine, bis sie an die Ereignisschleife gebunden sind.
Sie haben diesen Punkt bereits in der Erklärung zu Generatoren gesehen, aber es lohnt sich, ihn noch einmal zu wiederholen. Wenn Sie eine Hauptkoroutine haben, die auf andere wartet, hat es wenig Wirkung, sie einfach isoliert zu nennen:
>>>
>>> import asyncio
>>> async def main():
... print("Hello ...")
... await asyncio.sleep(1)
... print("World!")
>>> routine = main()
>>> routine
Denken Sie daran,asyncio.run() zu verwenden, um die Ausführung tatsächlich zu erzwingen, indem Sie die Coroutine (zukünftiges Objekt) vonmain()für die Ausführung in der Ereignisschleife planen:
>>>
>>> asyncio.run(routine)
Hello ...
World!(Andere Coroutinen können mitawait ausgeführt werden. Es ist typisch, nurmain() inasyncio.run() einzuwickeln, und verkettete Coroutinen mitawait werden von dort aufgerufen.)
#2: Standardmäßig wird eine asynchrone E / A-Ereignisschleife in einem einzelnen Thread und auf einem einzelnen CPU-Kern ausgeführt. Normalerweise ist das Ausführen einer Single-Threaded-Ereignisschleife in einem CPU-Kern mehr als ausreichend. Es ist auch möglich, Ereignisschleifen über mehrere Kerne hinweg auszuführen. Schauen Sie sich diesetalk by John Reese an, um mehr zu erfahren, und seien Sie gewarnt, dass Ihr Laptop spontan verbrennen kann.
#3. Ereignisschleifen sind steckbar. Das heißt, Sie könnten, wenn Sie es wirklich wollten, Ihre eigene Ereignisschleifenimplementierung schreiben und sie trotzdem Aufgaben ausführen lassen. Dies wird im Paketuvloop, das eine Implementierung der Ereignisschleife in Cython darstellt, wunderbar demonstriert.
Dies ist mit dem Begriff „steckbare Ereignisschleife“ gemeint: Sie können jede funktionierende Implementierung einer Ereignisschleife verwenden, die nicht mit der Struktur der Coroutinen selbst zusammenhängt. Dasasyncio-Paket selbst wird mittwo different event loop implementations geliefert, wobei der Standard auf demselectors-Modul basiert. (Die zweite Implementierung ist nur für Windows erstellt.)
Ein vollständiges Programm: Asynchrone Anforderungen
Du hast es bis hierher geschafft und jetzt ist es Zeit für den lustigen und schmerzlosen Teil. In diesem Abschnitt erstellen Sie einen Web-Scraping-URL-Kollektorareq.py mitaiohttp, einem blitzschnellen asynchronen HTTP-Client / Server-Framework. (Wir brauchen nur den Client-Teil.) Mit einem solchen Tool können Verbindungen zwischen einem Cluster von Sites zugeordnet werden, wobei die Linksdirected graph bilden.
Note: Möglicherweise fragen Sie sich, warum dasrequests-Paket von Python nicht mit asynchronem E / A kompatibel ist. requests basiert aufurllib3, das wiederum die Modulehttp undsocketvon Python verwendet.
Standardmäßig blockieren Socket-Vorgänge. Dies bedeutet, dass Pythonawait requests.get(url) nicht mag, da.get() nicht erwartet werden kann. Im Gegensatz dazu ist fast alles inaiohttp eine erwartete Coroutine, wiesession.request() undresponse.text(). Ansonsten ist es ein großartiges Paket, aber Sie tun sich selbst einen schlechten Dienst, indem Sierequests in asynchronem Code verwenden.
Die übergeordnete Programmstruktur sieht folgendermaßen aus:
-
Lesen Sie eine Folge von URLs aus einer lokalen Datei,
urls.txt. -
Senden Sie GET-Anforderungen für die URLs und dekodieren Sie den resultierenden Inhalt. Wenn dies fehlschlägt, halten Sie dort für eine URL an.
-
Suchen Sie nach den URLs innerhalb der
href-Tags im HTML-Code der Antworten. -
Schreiben Sie die Ergebnisse in
foundurls.txt. -
Führen Sie alle oben genannten Schritte so asynchron und gleichzeitig wie möglich aus. (Verwenden Sie
aiohttpfür die Anforderungen undaiofilesfür die Dateianhänge. Dies sind zwei Hauptbeispiele für E / A, die für das asynchrone E / A-Modell gut geeignet sind.)
Hier sind die Inhalte vonurls.txt. Es ist nicht riesig und enthält hauptsächlich stark frequentierte Websites:
$ cat urls.txt
https://regex101.com/
https://docs.python.org/3/this-url-will-404.html
https://www.nytimes.com/guides/
https://www.mediamatters.org/
https://1.1.1.1/
https://www.politico.com/tipsheets/morning-money
https://www.bloomberg.com/markets/economics
https://www.ietf.org/rfc/rfc2616.txtDie zweite URL in der Liste sollte eine 404-Antwort zurückgeben, die Sie ordnungsgemäß verarbeiten müssen. Wenn Sie eine erweiterte Version dieses Programms ausführen, müssen Sie sich wahrscheinlich mit viel haarigeren Problemen wie diesen befassen, z. B. Servertrennungen und endlosen Weiterleitungen.
Die Anforderungen selbst sollten in einer einzigen Sitzung gestellt werden, um die Wiederverwendung des internen Verbindungspools der Sitzung zu nutzen.
Werfen wir einen Blick auf das vollständige Programm. Wir werden die Dinge Schritt für Schritt durchgehen:
#!/usr/bin/env python3
# areq.py
"""Asynchronously get links embedded in multiple pages' HMTL."""
import asyncio
import logging
import re
import sys
from typing import IO
import urllib.error
import urllib.parse
import aiofiles
import aiohttp
from aiohttp import ClientSession
logging.basicConfig(
format="%(asctime)s %(levelname)s:%(name)s: %(message)s",
level=logging.DEBUG,
datefmt="%H:%M:%S",
stream=sys.stderr,
)
logger = logging.getLogger("areq")
logging.getLogger("chardet.charsetprober").disabled = True
HREF_RE = re.compile(r'href="(.*?)"')
async def fetch_html(url: str, session: ClientSession, **kwargs) -> str:
"""GET request wrapper to fetch page HTML.
kwargs are passed to `session.request()`.
"""
resp = await session.request(method="GET", url=url, **kwargs)
resp.raise_for_status()
logger.info("Got response [%s] for URL: %s", resp.status, url)
html = await resp.text()
return html
async def parse(url: str, session: ClientSession, **kwargs) -> set:
"""Find HREFs in the HTML of `url`."""
found = set()
try:
html = await fetch_html(url=url, session=session, **kwargs)
except (
aiohttp.ClientError,
aiohttp.http_exceptions.HttpProcessingError,
) as e:
logger.error(
"aiohttp exception for %s [%s]: %s",
url,
getattr(e, "status", None),
getattr(e, "message", None),
)
return found
except Exception as e:
logger.exception(
"Non-aiohttp exception occured: %s", getattr(e, "__dict__", {})
)
return found
else:
for link in HREF_RE.findall(html):
try:
abslink = urllib.parse.urljoin(url, link)
except (urllib.error.URLError, ValueError):
logger.exception("Error parsing URL: %s", link)
pass
else:
found.add(abslink)
logger.info("Found %d links for %s", len(found), url)
return found
async def write_one(file: IO, url: str, **kwargs) -> None:
"""Write the found HREFs from `url` to `file`."""
res = await parse(url=url, **kwargs)
if not res:
return None
async with aiofiles.open(file, "a") as f:
for p in res:
await f.write(f"{url}\t{p}\n")
logger.info("Wrote results for source URL: %s", url)
async def bulk_crawl_and_write(file: IO, urls: set, **kwargs) -> None:
"""Crawl & write concurrently to `file` for multiple `urls`."""
async with ClientSession() as session:
tasks = []
for url in urls:
tasks.append(
write_one(file=file, url=url, session=session, **kwargs)
)
await asyncio.gather(*tasks)
if __name__ == "__main__":
import pathlib
import sys
assert sys.version_info >= (3, 7), "Script requires Python 3.7+."
here = pathlib.Path(__file__).parent
with open(here.joinpath("urls.txt")) as infile:
urls = set(map(str.strip, infile))
outpath = here.joinpath("foundurls.txt")
with open(outpath, "w") as outfile:
outfile.write("source_url\tparsed_url\n")
asyncio.run(bulk_crawl_and_write(file=outpath, urls=urls))Dieses Skript ist länger als unsere ursprünglichen Spielzeugprogramme.
Die KonstanteHREF_RE ist ein regulärer Ausdruck, um zu extrahieren, wonach wir letztendlich suchen,href Tags in HTML:
>>>
>>> HREF_RE.search('Go to Real Python')
Die Coroutinefetch_html() ist ein Wrapper um eine GET-Anforderung, um die Anforderung zu erstellen und den resultierenden Seiten-HTML-Code zu dekodieren. Es stellt die Anfrage, wartet auf die Antwort und wird bei einem Nicht-200-Status sofort ausgelöst:
resp = await session.request(method="GET", url=url, **kwargs)
resp.raise_for_status()Wenn der Status in Ordnung ist, gibtfetch_html() den Seiten-HTML-Code (astr) zurück. Insbesondere wird in dieser Funktion keine Ausnahmebehandlung durchgeführt. Die Logik besteht darin, diese Ausnahme an den Aufrufer weiterzugeben und dort behandeln zu lassen:
html = await resp.text()Wirawaitsession.request() undresp.text(), weil sie auf Coroutinen warten. Der Anforderungs- / Antwortzyklus wäre ansonsten der langwierige, zeitaufwändige Teil der Anwendung, aber mit asynchronem E / A lässtfetch_html() die Ereignisschleife für andere leicht verfügbare Jobs wie das Parsen und Schreiben bereits vorhandener URLs arbeiten wurde geholt.
Als nächstes folgt in der Kette der Coroutinenparse(), das auffetch_html() auf eine bestimmte URL wartet und dann allehref-Tags aus dem HTML-Code dieser Seite extrahiert, um sicherzustellen, dass alle gültig und gültig sind Formatieren als absoluter Pfad.
Zugegeben, der zweite Teil vonparse() blockiert, besteht jedoch aus einer schnellen Regex-Übereinstimmung und stellt sicher, dass die entdeckten Links zu absoluten Pfaden gemacht werden.
In diesem speziellen Fall sollte dieser synchrone Code schnell und unauffällig sein. Denken Sie jedoch daran, dass jede Zeile innerhalb einer bestimmten Coroutine andere Coroutinen blockiert, es sei denn, diese Zeile verwendetyield,await oderreturn. Wenn das Parsen ein intensiverer Prozess war, sollten Sie diesen Teil in einem eigenen Prozess mitloop.run_in_executor() ausführen.
Als nächstes nimmt die Coroutinewrite() ein Dateiobjekt und eine einzelne URL und wartet aufparse(), umset der analysierten URLs zurückzugeben, wobei jede zusammen mit ihrer Quell-URL asynchron in die Datei geschrieben wird durch Verwendung vonaiofiles, einem Paket für asynchrone Datei-E / A.
Schließlich dientbulk_crawl_and_write() als Haupteinstiegspunkt in die Coroutinenkette des Skripts. Es wird eine einzelne Sitzung verwendet, und für jede URL wird eine Aufgabe erstellt, die letztendlich ausurls.txt gelesen wird.
Hier sind einige zusätzliche Punkte, die Erwähnung verdienen:
-
Der Standardwert
ClientSessionhatadapter mit maximal 100 offenen Verbindungen. Um dies zu ändern, übergeben Sie eine Instanz vonasyncio.connector.TCPConnectoranClientSession. Sie können auch Grenzwerte pro Host festlegen. -
Sie können maxtimeouts sowohl für die gesamte Sitzung als auch für einzelne Anforderungen angeben.
-
Dieses Skript verwendet auch
async with, was mitasynchronous context manager funktioniert. Ich habe diesem Konzept keinen ganzen Abschnitt gewidmet, da der Übergang von synchronen zu asynchronen Kontextmanagern ziemlich einfach ist. Letzterer muss.__aenter__()und.__aexit__()anstelle von.__exit__()und.__enter__()definieren. Wie zu erwarten, kannasync withnur in einer Coroutine-Funktion verwendet werden, die mitasync defdeklariert ist.
Wenn Sie mehr darüber erfahren möchten, sind an diecompanion files für dieses Tutorial bei GitHub auch Kommentare und Dokumentzeichenfolgen angehängt.
Hier ist die Ausführung in ihrer ganzen Pracht:areq.py erhält, analysiert und speichert Ergebnisse für 9 URLs in weniger als einer Sekunde:
$ python3 areq.py
21:33:22 DEBUG:asyncio: Using selector: KqueueSelector
21:33:22 INFO:areq: Got response [200] for URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Found 115 links for https://www.mediamatters.org/
21:33:22 INFO:areq: Got response [200] for URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Got response [200] for URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.ietf.org/rfc/rfc2616.txt
21:33:22 ERROR:areq: aiohttp exception for https://docs.python.org/3/this-url-will-404.html [404]: Not Found
21:33:22 INFO:areq: Found 120 links for https://www.nytimes.com/guides/
21:33:22 INFO:areq: Found 143 links for https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Wrote results for source URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Found 0 links for https://www.ietf.org/rfc/rfc2616.txt
21:33:22 INFO:areq: Got response [200] for URL: https://1.1.1.1/
21:33:22 INFO:areq: Wrote results for source URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Wrote results for source URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Found 3 links for https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Wrote results for source URL: https://www.bloomberg.com/markets/economics
21:33:23 INFO:areq: Found 36 links for https://1.1.1.1/
21:33:23 INFO:areq: Got response [200] for URL: https://regex101.com/
21:33:23 INFO:areq: Found 23 links for https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://1.1.1.1/Das ist nicht zu schäbig! Zur Überprüfung der Integrität können Sie die Zeilenanzahl auf der Ausgabe überprüfen. In meinem Fall ist es 626, aber denken Sie daran, dass dies schwanken kann:
$ wc -l foundurls.txt
626 foundurls.txt
$ head -n 3 foundurls.txt
source_url parsed_url
https://www.bloomberg.com/markets/economics https://www.bloomberg.com/feedback
https://www.bloomberg.com/markets/economics https://www.bloomberg.com/notices/tosNext Steps: Wenn Sie den Einsatz erhöhen möchten, machen Sie diesen Webcrawler rekursiv. Sie könnenaio-redis verwenden, um zu verfolgen, welche URLs in der Baumstruktur gecrawlt wurden, um zu vermeiden, dass sie zweimal angefordert werden, und Links mit dernetworkx-Bibliothek von Python verbinden.
Denken Sie daran, nett zu sein. Das Senden von 1000 gleichzeitigen Anfragen an eine kleine, ahnungslose Website ist schlecht, schlecht, schlecht. Es gibt Möglichkeiten, die Anzahl der gleichzeitigen Anforderungen, die Sie in einem Stapel stellen, zu begrenzen, z. B. bei Verwendung dersempahore-Objekte vonasyncio oder eines Musterslike this one. Wenn Sie diese Warnung nicht beachten, erhalten Sie möglicherweise eine große Anzahl vonTimeoutError-Ausnahmen und verletzen nur Ihr eigenes Programm.
Async IO im Kontext
Nachdem Sie eine gesunde Portion Code gesehen haben, treten wir einen Moment zurück und überlegen, wann asynchrones E / A eine ideale Option ist und wie Sie den Vergleich durchführen können, um zu dieser Schlussfolgerung zu gelangen, oder auf andere Weise ein anderes Modell der Parallelität auswählen.
Wann und warum ist Async IO die richtige Wahl?
Dieses Tutorial ist kein Ort für eine erweiterte Abhandlung über asynchrone E / A im Vergleich zu Threading im Vergleich zu Multiprocessing. Es ist jedoch hilfreich, eine Vorstellung davon zu haben, wann asynchrones E / A wahrscheinlich der beste Kandidat der drei ist.
Der Kampf um asynchrone E / A gegen Multiprocessing ist überhaupt kein Kampf. Tatsächlich können sieused in concert sein. Wenn Sie mehrere, ziemlich einheitliche CPU-gebundene Aufgaben haben (ein gutes Beispiel istgrid search in Bibliotheken wiescikit-learn oderkeras), sollte Multiprocessing eine naheliegende Wahl sein.
Es ist eine schlechte Idee,async vor jede Funktion zu setzen, wenn alle Funktionen blockierende Aufrufe verwenden. (Dies kann Ihren Code tatsächlich verlangsamen.) Wie bereits erwähnt, gibt es jedoch Stellen, an denen asynchrone E / A und Mehrfachverarbeitunglive in harmony können.
Der Wettbewerb zwischen asynchronem E / A und Threading ist etwas direkter. Ich erwähnte in der Einleitung, dass "das Einfädeln schwierig ist". Die ganze Geschichte ist, dass selbst in Fällen, in denen das Threading einfach zu implementieren scheint, es unter anderem aufgrund der Rennbedingungen und der Speichernutzung zu berüchtigten, nicht nachvollziehbaren Fehlern führen kann.
Threading lässt sich auch weniger elegant skalieren als asynchrone E / A-Vorgänge, da Threads eine Systemressource mit begrenzter Verfügbarkeit sind. Das Erstellen von Tausenden von Threads schlägt auf vielen Computern fehl, und ich empfehle nicht, es zuerst zu versuchen. Das Erstellen von Tausenden von asynchronen E / A-Aufgaben ist vollständig möglich.
Asynchrone E / A leuchtet, wenn Sie mehrere E / A-gebundene Aufgaben haben, bei denen die Aufgaben andernfalls durch Blockieren der E / A-gebundenen Wartezeit dominiert würden, z.
-
Netzwerk-E / A, unabhängig davon, ob Ihr Programm der Server oder der Client ist
-
Serverlose Designs wie ein Peer-to-Peer-Netzwerk für mehrere Benutzer wie ein Gruppenchatroom
-
Read/write operations where you want to mimic a “fire-and-forget” style but worry less about holding a lock on whatever you’re reading and writing to
Der Hauptgrund, es nicht zu verwenden, ist, dassawait nur einen bestimmten Satz von Objekten unterstützt, die einen bestimmten Satz von Methoden definieren. Wenn Sie asynchrone Lesevorgänge mit einem bestimmten DBMS ausführen möchten, müssen Sie nicht nur einen Python-Wrapper für dieses DBMS finden, sondern auch einen, der die Syntaxasync /awaitunterstützt. Coroutinen, die synchrone Aufrufe enthalten, blockieren die Ausführung anderer Coroutinen und Aufgaben.
Eine Auswahlliste der Bibliotheken, die mitasync /await arbeiten, finden Sie unterlist am Ende dieses Lernprogramms.
Async IO ist es, aber welches?
Dieses Lernprogramm konzentriert sich auf asynchrone E / A, die Syntax vonasync /await und die Verwendung vonasyncio für die Verwaltung von Ereignisschleifen und die Angabe von Aufgaben. asyncio ist sicherlich nicht die einzige asynchrone E / A-Bibliothek da draußen. Diese Beobachtung von Nathaniel J. Smith sagt viel:
[In] ein paar Jahren könnte
asynciozu einer jener stdlib-Bibliotheken werden, die versierte Entwickler meiden, wieurllib2.…
Ich behaupte im Endeffekt, dass
asyncioein Opfer seines eigenen Erfolgs ist: Als es entworfen wurde, verwendete es den bestmöglichen Ansatz; Aber seitdem hat die vonasyncioinspirierte Arbeit - wie das Hinzufügen vonasync/await- die Landschaft verändert, so dass wir es noch besser machen können, und jetzt istasynciobehindert durch seine früheren Verpflichtungen. (Source)
Zu diesem Zweck sindcurio undtrio einige bekannte Alternativen, die das tun, wasasyncio tut, wenn auch mit unterschiedlichen APIs und unterschiedlichen Ansätzen. Persönlich denke ich, dass wenn Sie ein mittelgroßes, unkompliziertes Programm erstellen, die Verwendung vonasyncio ausreichend und verständlich ist und Sie vermeiden können, eine weitere große Abhängigkeit außerhalb der Standardbibliothek von Python hinzuzufügen.
Schauen Sie sich jedoch auf jeden Fallcurio undtrio an, und Sie werden möglicherweise feststellen, dass sie dasselbe auf eine Weise erledigen, die für Sie als Benutzer intuitiver ist. Viele der hier vorgestellten paketunabhängigen Konzepte sollten auch für alternative asynchrone E / A-Pakete gelten.
Krimskrams
In den nächsten Abschnitten werden Sie einige verschiedene Teile vonasyncio undasync /await behandeln, die bisher nicht genau in das Lernprogramm passen, aber dennoch wichtig für das Erstellen und sind ein vollständiges Programm verstehen.
Andere Funktionen der obersten Ebeneasyncio
Nebenasyncio.run() haben Sie einige andere Funktionen auf Paketebene gesehen, z. B.asyncio.create_task() undasyncio.gather().
Mitcreate_task() können Sie die Ausführung eines Coroutine-Objekts planen, gefolgt vonasyncio.run():
>>>
>>> import asyncio
>>> async def coro(seq) -> list:
... """'IO' wait time is proportional to the max element."""
... await asyncio.sleep(max(seq))
... return list(reversed(seq))
...
>>> async def main():
... # This is a bit redundant in the case of one task
... # We could use `await coro([3, 2, 1])` on its own
... t = asyncio.create_task(coro([3, 2, 1])) # Python 3.7+
... await t
... print(f't: type {type(t)}')
... print(f't done: {t.done()}')
...
>>> t = asyncio.run(main())
t: type
t done: True Dieses Muster hat eine gewisse Subtilität: Wenn Sieawait tnicht innerhalb vonmain() liegen, wird es möglicherweise beendet, bevormain() selbst signalisiert, dass es vollständig ist. Daasyncio.run(main())calls loop.run_until_complete(main()) ist, ist die Ereignisschleife nur betroffen (ohneawait t vorhanden), dassmain() ausgeführt wird, nicht dass die Aufgaben, die innerhalb vonmain() erstellt werden, ausgeführt werden erledigt. Ohneawait t sind die anderen Aufgaben der Schleifewill be cancelled, möglicherweise bevor sie abgeschlossen sind. Wenn Sie eine Liste der aktuell ausstehenden Aufgaben benötigen, können Sieasyncio.Task.all_tasks() verwenden.
Note:asyncio.create_task() wurde in Python 3.7 eingeführt. Verwenden Sie in Python 3.6 oder niedrigerasyncio.ensure_future() anstelle voncreate_task().
Separat gibt esasyncio.gather(). gather() ist zwar nicht besonders wichtig, soll aber eine Sammlung von Coroutinen (Futures) in eine einzige Zukunft bringen. Infolgedessen wird ein einzelnes zukünftiges Objekt zurückgegeben. Wenn Sieawait asyncio.gather() angeben und mehrere Aufgaben oder Coroutinen angeben, warten Sie darauf, dass alle abgeschlossen sind. (Dies entspricht etwasqueue.join() aus unserem früheren Beispiel.) Das Ergebnis vongather() ist eine Liste der Ergebnisse über die Eingaben hinweg:
>>>
>>> import time
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0])) # Python 3.7+
... print('Start:', time.strftime('%X'))
... a = await asyncio.gather(t, t2)
... print('End:', time.strftime('%X')) # Should be 10 seconds
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
... return a
...
>>> a = asyncio.run(main())
Start: 16:20:11
End: 16:20:21
Both tasks done: True
>>> aSie haben wahrscheinlich bemerkt, dassgather() auf die gesamte Ergebnismenge der Futures oder Coroutinen wartet, die Sie übergeben. Alternativ können Sieasyncio.as_completed() durchlaufen, um Aufgaben nach Abschluss in der Reihenfolge ihres Abschlusses abzurufen. Die Funktion gibt einen Iterator zurück, der Aufgaben nach Abschluss liefert. Im Folgenden wird das Ergebnis voncoro([3, 2, 1]) verfügbar sein, bevorcoro([10, 5, 0]) abgeschlossen ist, was beigather() nicht der Fall ist:
>>>
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0]))
... print('Start:', time.strftime('%X'))
... for res in asyncio.as_completed((t, t2)):
... compl = await res
... print(f'res: {compl} completed at {time.strftime("%X")}')
... print('End:', time.strftime('%X'))
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
...
>>> a = asyncio.run(main())
Start: 09:49:07
res: [1, 2, 3] completed at 09:49:10
res: [0, 5, 10] completed at 09:49:17
End: 09:49:17
Both tasks done: TrueZuletzt können Sie auchasyncio.ensure_future() sehen. Sie sollten es selten benötigen, da es sich um eine Installations-API auf niedrigerer Ebene handelt, die größtenteils durchcreate_task() ersetzt wird, die später eingeführt wurde.
Die Priorität vonawait
Während sie sich etwas ähnlich verhalten, hat das Schlüsselwortawaiteine signifikant höhere Priorität alsyield. Das bedeutet, dass es in eineryield from-Anweisung Klammern gibt, die in einer analogenawait-Anweisung nicht erforderlich sind, da sie enger gebunden ist. Weitere Informationen finden Sie unterexamples of await expressions aus PEP 492.
Fazit
Sie können jetztasync /await und die daraus erstellten Bibliotheken verwenden. Hier ist eine Zusammenfassung dessen, was Sie behandelt haben:
-
Asynchrone E / A als sprachunabhängiges Modell und als Möglichkeit, Parallelität zu bewirken, indem Coroutinen indirekt miteinander kommunizieren
-
Die Besonderheiten der neuen Schlüsselwörter
asyncundawaitvon Python, mit denen Coroutinen markiert und definiert werden -
asyncio, das Python-Paket, das die API zum Ausführen und Verwalten von Coroutinen bereitstellt
Ressourcen
Python-Versionsspezifikationen
Async IO in Python hat sich schnell entwickelt, und es kann schwierig sein, den Überblick darüber zu behalten, was wann kam. Hier ist eine Liste der Änderungen und Einführungen von Python-Nebenversionen in Bezug aufasyncio:
-
3.3: The
yield fromexpression allows for generator delegation. -
3.4:
asynciowas introduced in the Python standard library with provisional API status. -
3.5:
asyncandawaitbecame a part of the Python grammar, used to signify and wait on coroutines. Sie waren noch keine reservierten Schlüsselwörter. (Sie können weiterhin Funktionen oder Variablen mit den Namenasyncundawaitdefinieren.) -
3.6: Asynchronous generators and asynchronous comprehensions were introduced. Die API von
asynciowurde eher als stabil als als vorläufig deklariert. -
3.7:
asyncandawaitbecame reserved keywords. (Sie können nicht als Bezeichner verwendet werden.) Sie sollen den Dekorator vonasyncio.coroutine()ersetzen.asyncio.run()wurde untera bunch of other features in das Paketasyncioaufgenommen.
Wenn Sie sicher sein möchten (undasyncio.run() verwenden möchten), verwenden Sie Python 3.7 oder höher, um alle Funktionen zu erhalten.
Artikel
Hier ist eine kuratierte Liste zusätzlicher Ressourcen:
-
Echtes Python:Speed up your Python Program with Concurrency
-
Echtes Python:What is the Python Global Interpreter Lock?
-
CPython: Das
asyncio-Paketsource -
Python-Dokumente:Data model > Coroutines
-
TalkPython:Async Techniques and Examples in Pythonhttps://github.com/talkpython/async-techniques-python-course
-
Brett Cannon:How the Heck Does Async-Await Work in Python 3.5?
-
PYMOTW:
asyncio -
A. Jesse Jiryu Davis und Guido van Rossum:A Web Crawler With asyncio Coroutines
-
Andy Pearce:The State of Python Coroutines:
yield from -
Nathaniel J. Smith:Some Thoughts on Asynchronous API Design in a Post-
async/awaitWorld -
Armin Ronacher:I don’t understand Python’s Asyncio
-
Andy Balaam:series on
asyncio(4 Beiträge) -
Stapelüberlauf:Python
asyncio.semaphoreinasync-awaitfunction -
Yeray Diaz:
In einigen Abschnitten von PythonWhat’s Newwird die Motivation für Sprachänderungen ausführlicher erläutert:
-
What’s New in Python 3.3 (
yield fromund PEP 380) -
What’s New in Python 3.6 (PEP 525 & 530)
Von David Beazley:
YouTube-Gespräche:
-
John Reese - Mit AsyncIO und Multiprocessing außerhalb der GIL denken - PyCon 2018
-
Keynote David Beazley - Themen von Interesse (Python Asyncio)
-
David Beazley - Python-Parallelität von Grund auf: LIVE! - PyCon 2015
-
Raymond Hettinger, Python-Kernentwickler, denkt an Parallelität
-
Miguel Grinberg Asynchronous Python für die komplette PyCon 2017 für Anfänger
-
Yury Selivanov asyncawait und asyncio in Python 3 6 und darüber hinaus PyCon 2017
-
Angst und Warten in Async: Eine wilde Reise zum Herzen des Coroutine-Traums
-
Was ist Async, wie funktioniert es und wann sollte ich es verwenden? (PyCon APAC 2014)
Verwandte PEPs
| PEP | Datum erstellt |
|---|---|
2005-05 |
|
2009-02 |
|
2011-05 |
|
PEP 3156 - Neustart der asynchronen E / A-Unterstützung: das "Asyncio" -Modul |
2012-12 |
2015-04 |
|
2016-07 |
|
2016-09 |
Bibliotheken, die mitasync /await arbeiten
Vonaio-libs:
-
aiohttp: Asynchrones HTTP-Client / Server-Framework -
aioredis: Async IO Redis-Unterstützung -
aiopg: Async IO PostgreSQL-Unterstützung -
aiomcache: Async IO Memcached Client -
aiokafka: Async IO Kafka-Client -
aiozmq: Async IO ZeroMQ-Unterstützung -
aiojobs: Jobplaner zum Verwalten von Hintergrundaufgaben -
async_lru: Einfacher LRU-Cache für asynchrone E / A.
Vonmagicstack:
Von anderen Gastgebern:
-
trio: Freundlicherasynciosoll ein radikal einfacheres Design präsentieren -
aiofiles: Asynchrone Datei-E / A. -
asks: Asynchrone anforderungsähnliche http-Bibliothek -
asyncio-redis: Async IO Redis-Unterstützung -
aioprocessing: Integriert das Modulmultiprocessingmitasyncio -
umongo: Async IO MongoDB-Client -
unsync: Unsynchronisieren Sieasyncio -
aiostream: Wieitertools, aber asynchron