Einführung
Maschinelles Lernen ist ein Teilgebiet der Künstlichen Intelligenz (KI). Das Ziel des maschinellen Lernens besteht im Allgemeinen darin, die Struktur von Daten zu verstehen und diese Daten in Modelle einzupassen, die von Menschen verstanden und genutzt werden können.
Obwohl maschinelles Lernen ein Bereich innerhalb der Informatik ist, unterscheidet es sich von traditionellen rechnerischen Ansätzen. Beim herkömmlichen Rechnen sind Algorithmen Sätze von explizit programmierten Anweisungen, die von Computern zum Berechnen oder Lösen von Problemen verwendet werden. Algorithmen für maschinelles Lernen ermöglichen es Computern stattdessen, Dateneingaben zu trainieren und statistische Analysen zu verwenden, um Werte auszugeben, die in einen bestimmten Bereich fallen. Aus diesem Grund erleichtert das maschinelle Lernen Computern das Erstellen von Modellen aus Beispieldaten, um Entscheidungsprozesse auf der Grundlage von Dateneingaben zu automatisieren.
Jeder heutige Technologie-Anwender hat vom maschinellen Lernen profitiert. Mithilfe der Gesichtserkennungstechnologie können Benutzer mithilfe von Social Media-Plattformen Fotos von Freunden markieren und freigeben. Die OCR-Technologie (Optical Character Recognition) wandelt Textbilder in bewegliche Schrift um. Empfehlungs-Engines, die durch maschinelles Lernen angetrieben werden, schlagen vor, welche Filme oder Fernsehsendungen basierend auf den Benutzerpräferenzen als Nächstes angesehen werden sollen. Selbstfahrende Autos, deren Navigation auf maschinellem Lernen beruht, werden den Verbrauchern möglicherweise bald zur Verfügung stehen.
Maschinelles Lernen ist ein sich ständig entwickelndes Gebiet. Aus diesem Grund sollten Sie beim Arbeiten mit maschinellen Lernmethoden oder beim Analysieren der Auswirkungen maschineller Lernprozesse einige Aspekte berücksichtigen.
In diesem Lernprogramm werden die gängigen Methoden des maschinellen Lernens (überwachtes und unbeaufsichtigtes Lernen) sowie die gängigen algorithmischen Ansätze des maschinellen Lernens, einschließlich des k-Nearest-Neighbor-Algorithmus, des Entscheidungsbaum-Lernens und des Tiefenlernens, vorgestellt. Wir werden untersuchen, welche Programmiersprachen beim maschinellen Lernen am häufigsten verwendet werden, und Ihnen dabei einige der positiven und negativen Eigenschaften der einzelnen Sprachen erläutern. Darüber hinaus werden Verzerrungen erörtert, die durch Algorithmen für maschinelles Lernen aufrechterhalten werden, und es wird überlegt, was beachtet werden kann, um diese Verzerrungen beim Erstellen von Algorithmen zu vermeiden.
Methoden des maschinellen Lernens
Im maschinellen Lernen werden Aufgaben im Allgemeinen in breite Kategorien eingeteilt. Diese Kategorien basieren darauf, wie das Lernen empfangen wird oder wie dem entwickelten System Feedback zum Lernen gegeben wird.
Zwei der am weitesten verbreiteten Methoden des maschinellen Lernens sind * überwachtes Lernen *, bei dem Algorithmen auf der Grundlage beispielhafter Eingabe- und Ausgabedaten trainiert werden, die vom Menschen gekennzeichnet sind, und * unbeaufsichtigtes Lernen *, bei dem dem Algorithmus keine gekennzeichneten Daten zur Verfügung gestellt werden, damit er sie finden kann Struktur innerhalb seiner Eingabedaten. Lassen Sie uns diese Methoden genauer untersuchen.
Überwachtes Lernen
Beim überwachten Lernen werden dem Computer Beispieleingaben bereitgestellt, die mit den gewünschten Ausgaben beschriftet sind. Der Zweck dieser Methode besteht darin, dass der Algorithmus lernen kann, indem er seine tatsächliche Ausgabe mit den gelernten Ausgaben vergleicht, um Fehler zu finden, und das Modell entsprechend modifiziert. Betreutes Lernen verwendet daher Muster, um Label-Werte für zusätzliche unbeschriftete Daten vorherzusagen.
Beispielsweise kann bei überwachtem Lernen ein Algorithmus mit Bildern von Haien, die mit "+ fish " gekennzeichnet sind, und mit Bildern von Ozeanen, die mit " water " gekennzeichnet sind, mit Daten versorgt werden. Durch das Trainieren dieser Daten sollte der überwachte Lernalgorithmus in der Lage sein, unbeschriftete Haifischbilder später als " Fisch " und unbeschriftete Ozeanbilder als " Wasser +" zu identifizieren.
Ein häufiger Anwendungsfall für überwachtes Lernen besteht darin, historische Daten zu verwenden, um statistisch wahrscheinliche zukünftige Ereignisse vorherzusagen. Es kann historische Börseninformationen verwenden, um bevorstehende Schwankungen zu antizipieren, oder um Spam-E-Mails herauszufiltern. Beim überwachten Lernen können gekennzeichnete Fotos von Hunden als Eingabedaten verwendet werden, um nicht gekennzeichnete Fotos von Hunden zu klassifizieren.
Unbeaufsichtigtes Lernen
Beim unbeaufsichtigten Lernen sind die Daten nicht gekennzeichnet, sodass der Lernalgorithmus Gemeinsamkeiten zwischen seinen Eingabedaten findet. Da unbeschriftete Daten häufiger vorkommen als beschriftete Daten, sind maschinelle Lernmethoden, die unbeaufsichtigtes Lernen ermöglichen, besonders wertvoll.
Das Ziel des unbeaufsichtigten Lernens kann so einfach sein wie das Auffinden von verborgenen Mustern in einem Datensatz, es kann jedoch auch das Ziel des Merkmalslernens sein, das es der Rechenmaschine ermöglicht, automatisch die Darstellungen zu ermitteln, die zum Klassifizieren von Rohdaten erforderlich sind.
Unbeaufsichtigtes Lernen wird üblicherweise für Transaktionsdaten verwendet. Möglicherweise verfügen Sie über einen großen Datensatz von Kunden und deren Einkäufen, aber als Mensch werden Sie wahrscheinlich nicht in der Lage sein, zu verstehen, welche ähnlichen Attribute aus Kundenprofilen und deren Arten von Einkäufen abgeleitet werden können. Mit diesen Daten, die einem unbeaufsichtigten Lernalgorithmus zugeführt werden, kann festgestellt werden, dass Frauen einer bestimmten Altersgruppe, die geruchslose Seifen kaufen, wahrscheinlich schwanger sind. Daher kann eine Marketingkampagne in Bezug auf Schwangerschafts- und Babyprodukte gezielt auf diese Zielgruppe ausgerichtet werden ihre Anzahl der Einkäufe zu erhöhen.
Ohne eine „richtige“ Antwort zu erhalten, können unbeaufsichtigte Lernmethoden komplexe Daten untersuchen, die umfangreicher und scheinbar nicht miteinander verbunden sind, um sie auf potenziell sinnvolle Weise zu organisieren. Unbeaufsichtigtes Lernen wird häufig zur Erkennung von Anomalien verwendet, einschließlich bei betrügerischen Kreditkartenkäufen und Empfehlungssystemen, die empfehlen, welche Produkte als Nächstes gekauft werden sollen. Beim unbeaufsichtigten Lernen können Fotos von Hunden ohne Tags als Eingabedaten für den Algorithmus verwendet werden, um Ähnlichkeiten zu finden und Hundefotos zusammen zu klassifizieren.
Ansätze
Maschinelles Lernen ist eng mit rechnergestützter Statistik verbunden. Daher ist es hilfreich, über Hintergrundwissen in Statistik zu verfügen, um Algorithmen für maschinelles Lernen zu verstehen und zu nutzen.
Für diejenigen, die möglicherweise keine Statistik studiert haben, kann es hilfreich sein, zunächst Korrelation und Regression zu definieren, da sie häufig zur Untersuchung der Beziehung zwischen quantitativen Variablen verwendet werden. * Korrelation * ist ein Maß für die Assoziation zwischen zwei Variablen, die weder als abhängig noch als unabhängig bezeichnet werden. * Regression * auf einer Basisebene wird verwendet, um die Beziehung zwischen einer abhängigen und einer unabhängigen Variablen zu untersuchen. Da Regressionsstatistiken verwendet werden können, um die abhängige Variable zu antizipieren, wenn die unabhängige Variable bekannt ist, werden durch die Regression Vorhersagefunktionen aktiviert.
Ansätze zum maschinellen Lernen werden kontinuierlich weiterentwickelt. Für unsere Zwecke werden wir einige der gängigen Ansätze durchgehen, die zum Zeitpunkt des Schreibens beim maschinellen Lernen verwendet werden.
k-nächster Nachbar
Der Algorithmus für den nächsten k-Nachbarn ist ein Mustererkennungsmodell, das sowohl zur Klassifizierung als auch zur Regression verwendet werden kann. Oft als k-NN abgekürzt, ist das * k * im k-nächsten Nachbarn eine positive ganze Zahl, die typischerweise klein ist. In der Klassifikation oder in der Regression besteht die Eingabe aus den k nächstgelegenen Trainingsbeispielen innerhalb eines Raums.
Wir werden uns auf die k-NN-Klassifikation konzentrieren. Bei dieser Methode ist die Ausgabe die Klassenzugehörigkeit. Dadurch wird der Klasse, die unter ihren k nächsten Nachbarn am häufigsten vorkommt, ein neues Objekt zugewiesen. Im Fall von k = 1 wird das Objekt der Klasse des einzigen nächsten Nachbarn zugeordnet.
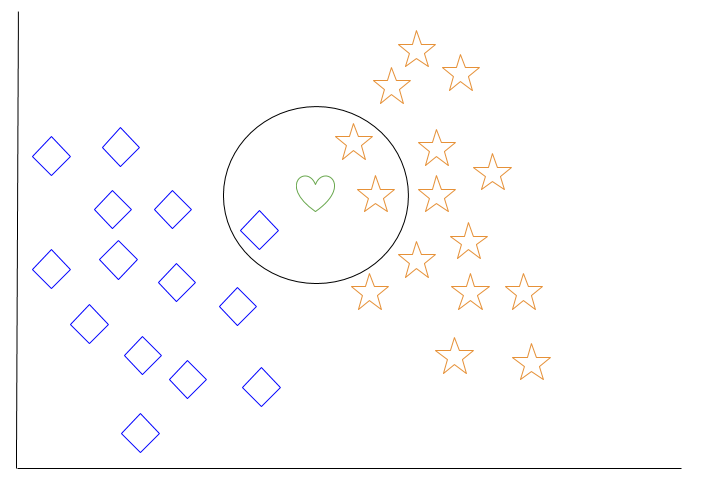
Schauen wir uns ein Beispiel für einen k-nächsten Nachbarn an. In der folgenden Abbildung sind Objekte mit blauen Diamanten und Objekte mit orangefarbenen Sternen dargestellt. Diese gehören zu zwei getrennten Klassen: der Diamantklasse und der Sternklasse.
image: https: //assets.digitalocean.com/articles/machine-learning/intro-to-ml/k-NN-1-graph.png [k-next neighbour initial data set]
Wenn dem Raum ein neues Objekt hinzugefügt wird - in diesem Fall ein grünes Herz - soll der Algorithmus für maschinelles Lernen das Herz einer bestimmten Klasse zuordnen.
image: https: //assets.digitalocean.com/articles/machine-learning/intro-to-ml/k-NN-2-graph.png
Wenn wir k = 3 wählen, findet der Algorithmus die drei nächsten Nachbarn des grünen Herzens, um es entweder der Diamantklasse oder der Sternklasse zuzuordnen.
In unserem Diagramm sind die drei nächsten Nachbarn des grünen Herzens ein Diamant und zwei Sterne. Daher klassifiziert der Algorithmus das Herz mit der Sternenklasse.
Bild: https://assets.digitalocean.com/articles/machine-learning/intro-to-ml/k-NN-3-graph.png [k-nächster Nachbar-Datensatz mit vollständiger Klassifizierung]
{kind=link}
Unter den grundlegendsten Algorithmen des maschinellen Lernens wird der k-nächste Nachbar als eine Art von "faulem Lernen" angesehen, da eine Verallgemeinerung über die Trainingsdaten hinaus erst erfolgt, wenn eine Anfrage an das System gestellt wird.
Entscheidungsbaum Lernen
Für die allgemeine Verwendung werden Entscheidungsbäume verwendet, um Entscheidungen visuell darzustellen und Entscheidungen zu zeigen oder zu informieren. Bei der Arbeit mit maschinellem Lernen und Data Mining werden Entscheidungsbäume als Vorhersagemodell verwendet. Diese Modelle bilden Beobachtungen zu Daten auf Schlussfolgerungen über den Zielwert der Daten ab.
Ziel des Lernens von Entscheidungsbäumen ist es, ein Modell zu erstellen, das den Wert eines Ziels anhand von Eingabevariablen vorhersagt.
Im Vorhersagemodell werden die durch Beobachtung ermittelten Datenattribute durch die Zweige dargestellt, während die Rückschlüsse auf den Zielwert der Daten in den Blättern dargestellt werden.
Beim „Lernen“ eines Baums werden die Quelldaten auf der Grundlage eines Attributwerttests, der für jede der abgeleiteten Teilmengen rekursiv wiederholt wird, in Teilmengen unterteilt. Sobald die Teilmenge an einem Knoten den gleichen Wert wie der Zielwert hat, ist der Rekursionsprozess abgeschlossen.
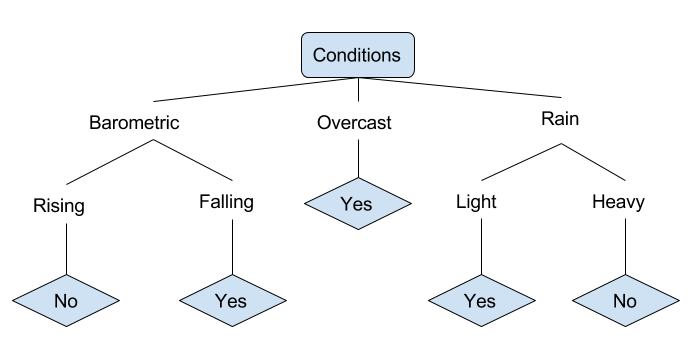
Schauen wir uns ein Beispiel für verschiedene Bedingungen an, die bestimmen, ob jemand angeln gehen soll oder nicht. Dies schließt sowohl Wetterbedingungen als auch Luftdruckbedingungen ein.
image: https://assets.digitalocean.com/articles/machine-learning/intro-to-ml/decision-tree-diagram.png [Beispiel für einen Entscheidungsbaum zum Angeln]
{kind=link}
Im vereinfachten Entscheidungsbaum oben wird ein Beispiel klassifiziert, indem es durch den Baum zum entsprechenden Blattknoten sortiert wird. Dies gibt dann die dem jeweiligen Blatt zugeordnete Klassifizierung zurück, die in diesem Fall entweder ein "+ Ja " oder ein " Nein +" ist. Der Baum klassifiziert die Bedingungen eines Tages danach, ob er zum Angeln geeignet ist oder nicht.
Ein echter Klassifizierungsbaumdatensatz hätte viel mehr Funktionen als oben beschrieben, aber Beziehungen sollten einfach zu bestimmen sein. Wenn Sie mit Entscheidungsbaumlernen arbeiten, müssen verschiedene Bestimmungen getroffen werden, einschließlich der zu wählenden Funktionen, der zu verwendenden Aufteilungsbedingungen und des Verständnisses, wann der Entscheidungsbaum ein klares Ende erreicht hat.
Tiefes Lernen
Deep Learning versucht nachzuahmen, wie das menschliche Gehirn Licht- und Tonreize in Sehen und Hören umwandeln kann. Eine Deep-Learning-Architektur ist von biologischen neuronalen Netzwerken inspiriert und besteht aus mehreren Schichten in einem künstlichen neuronalen Netzwerk, das aus Hardware und GPUs besteht.
Deep Learning verwendet eine Kaskade nichtlinearer Verarbeitungseinheitsebenen, um Merkmale (oder Darstellungen) der Daten zu extrahieren oder zu transformieren. Der Ausgang einer Schicht dient als Eingang der nachfolgenden Schicht. Beim vertieften Lernen können Algorithmen entweder überwacht werden und zur Klassifizierung von Daten dienen, oder sie können unbeaufsichtigt werden und eine Musteranalyse durchführen.
Unter den Algorithmen für maschinelles Lernen, die derzeit verwendet und entwickelt werden, absorbiert Deep Learning die meisten Daten und konnte den Menschen bei einigen kognitiven Aufgaben schlagen. Aufgrund dieser Eigenschaften ist Deep Learning zum Ansatz mit erheblichem Potenzial im Bereich der künstlichen Intelligenz geworden
Sowohl das Computer-Sehen als auch die Spracherkennung haben bedeutende Fortschritte bei Deep-Learning-Ansätzen erzielt. IBM Watson ist ein bekanntes Beispiel für ein System, das Deep Learning nutzt.
Programmiersprachen
Wenn Sie eine Sprache auswählen, auf die Sie sich mit maschinellem Lernen spezialisieren möchten, sollten Sie die in aktuellen Stellenanzeigen aufgeführten Fähigkeiten sowie die in verschiedenen Sprachen verfügbaren Bibliotheken berücksichtigen, die für maschinelle Lernprozesse verwendet werden können.
Aus https://www.ibm.com/developerworks/community/blogs/jfp/entry/What_Language_Is_Best_For_Machine_Learning_And_Data_Science, das im Dezember 2016 aus Stellenanzeigen entnommen wurde, kann entnommen werden, dass Python das am meisten nachgefragte Programm ist Sprache im Bereich des maschinellen Lernens. Auf Python folgt Java, dann R, dann C ++.
Die Popularität von * Python * kann auf die zunehmende Entwicklung von Deep-Learning-Frameworks zurückzuführen sein, die in letzter Zeit für diese Sprache verfügbar sind, einschließlich TensorFlow, PyTorch, und Keras. Als Sprache mit lesbarer Syntax und der Fähigkeit, als Skriptsprache verwendet zu werden, erweist sich Python als leistungsstark und unkompliziert sowohl für die Vorverarbeitung von Daten als auch für die direkte Arbeit mit Daten. Die maschinelle Lernbibliothek scikit-learn basiert auf mehreren vorhandenen Python-Paketen, mit denen Python-Entwickler möglicherweise bereits vertraut sind: http://www.numpy.org/ [NumPy], SciPy und Matplotlib.
Um mit Python zu beginnen, können Sie unsere Tutorial-Reihe unter "https://www.digitalocean.com/community/tutorial_series/how-to-code-in-python-3[How To Code in Python 3]" lesen Lesen Sie speziell unter „https://www.digitalocean.com/community/tutorials/how-to-build-a-machine-learning-classifier-in-python-with-scikit-learn[How To Build a Machine Learning Classifier in Python mit scikit-learn] ”oder“ Wie wird ein neuronaler Stiltransfer mit ausgeführt? Python 3 und PyTorch. “
-
Java * wird häufig in der Unternehmensprogrammierung verwendet und wird im Allgemeinen von Entwicklern von Front-End-Desktopanwendungen verwendet, die auch auf Unternehmensebene an maschinellem Lernen arbeiten. Normalerweise ist es nicht die erste Wahl für Programmieranfänger, die sich mit maschinellem Lernen auseinandersetzen möchten, aber diejenigen, die über einen Hintergrund in der Java-Entwicklung verfügen, ziehen es vor, sich auf maschinelles Lernen anzuwenden. In Bezug auf Anwendungen für maschinelles Lernen in der Industrie wird Java eher für die Netzwerksicherheit als für Python verwendet, einschließlich in Anwendungsfällen für Cyberangriffe und Betrugserkennung.
Zu den maschinellen Lernbibliotheken für Java gehören Deeplearning4j, eine Open-Source-Bibliothek mit verteilten Deep-Learning-Funktionen, die sowohl für Java als auch für Scala geschrieben wurde. MALLET ( MA chine L verdienen für L anguag * E * T oolkit) ermöglicht Anwendungen für maschinelles Lernen zu Text, einschließlich Verarbeitung natürlicher Sprache, Themenmodellierung, Dokumentklassifizierung und Clustering; und Weka, eine Sammlung von Algorithmen für maschinelles Lernen, die für Data Mining-Aufgaben verwendet werden.
-
R * ist eine Open-Source-Programmiersprache, die hauptsächlich für statistische Berechnungen verwendet wird. Es hat in den letzten Jahren an Popularität gewonnen und wird von vielen Wissenschaftlern bevorzugt. R wird normalerweise nicht in industriellen Produktionsumgebungen verwendet, ist jedoch in industriellen Anwendungen aufgrund des zunehmenden Interesses an Data Science gestiegen. Beliebte Pakete für maschinelles Lernen in R sind caret (Abkürzung für C lassification A und RE gression T raining) zum Erstellen von Vorhersagemodellen, randomForest zur Klassifizierung und Regression und https://cran.r-project.org/web/ packages / e1071 / index.html [e1071] mit Funktionen für Statistik und Wahrscheinlichkeitstheorie.
-
C * ist die Sprache der Wahl für maschinelles Lernen und künstliche Intelligenz in Spiel- oder Roboteranwendungen (einschließlich Roboterbewegung). Entwickler von Embedded-Computing-Hardware und Elektronikingenieure bevorzugen C oder C in Anwendungen für maschinelles Lernen aufgrund ihrer Sprachkenntnisse und Kontrolle. Einige Bibliotheken für maschinelles Lernen, die Sie mit C ++ verwenden können, umfassen die skalierbaren Bibliotheken mlpack, Dlib, die umfassende Algorithmen für maschinelles Lernen bieten, und die modular und Open-Source Shark.
Menschliche Vorurteile
Obwohl Daten und Computeranalysen den Eindruck erwecken, dass wir objektive Informationen erhalten, ist dies nicht der Fall. Datenbasis bedeutet nicht, dass die maschinellen Lernergebnisse neutral sind. Human Bias spielt eine Rolle bei der Erfassung, Organisation und letztendlich bei den Algorithmen, die bestimmen, wie maschinelles Lernen mit diesen Daten interagiert.
Wenn zum Beispiel Personen Bilder für „Fische“ als Daten zum Trainieren eines Algorithmus bereitstellen und diese Personen überwiegend Bilder von Goldfischen auswählen, klassifiziert ein Computer einen Hai möglicherweise nicht als Fisch. Dies würde eine Voreingenommenheit gegenüber Haien als Fischen hervorrufen, und Haie würden nicht als Fische gezählt.
Wenn ein Computer historische Fotos von Wissenschaftlern als Trainingsdaten verwendet, klassifiziert er Wissenschaftler möglicherweise nicht richtig, die auch farbige oder weibliche Personen sind. Tatsächlich haben aktuelle Peer-Review-Studien ergeben, dass KI- und maschinelle Lernprogramme menschenähnliche Vorurteile aufweisen, die Rassen- und Geschlechtervorurteile beinhalten. Siehe zum Beispiel "http://science.sciencemag.org/content/356/6334/183[Semantics, die automatisch aus Sprachkorpora abgeleitet werden, enthalten menschenähnliche Verzerrungen" und "https://homes.cs.washington.edu/". % 7Emy89 / publications / bias.pdf [Männer kaufen auch gerne ein: Verringerung der geschlechtsspezifischen Verzerrung durch Einschränkungen auf Korpusebene] “[PDF].
Da maschinelles Lernen im Geschäftsleben zunehmend genutzt wird, können ungeklärte Vorurteile systembedingte Probleme aufrechterhalten, die Menschen möglicherweise daran hindern, sich für Kredite zu qualifizieren, Anzeigen für hochbezahlte Stellenangebote zu schalten oder Zustellungsoptionen am selben Tag zu erhalten.
Da menschliche Voreingenommenheit andere negativ beeinflussen kann, ist es äußerst wichtig, sich dessen bewusst zu sein und auch darauf hinzuarbeiten, es so weit wie möglich zu beseitigen. Eine Möglichkeit, dies zu erreichen, besteht darin, sicherzustellen, dass an einem Projekt verschiedene Personen arbeiten und dass verschiedene Personen es testen und überprüfen. Andere forderten, dass https://www.theguardian.com/technology/2017/jan/27/ai-artificial-intelligence-watchdog-notwendig ist, um diskriminierende automatisierte Entscheidungen zu verhindern, und dass Dritte die Algorithmen überwachen und prüfen ], building alternative systems, die Verzerrungen erkennen können und https: //www.fidelitylabs.com/2017/06/14/combating-machine-learning-bias/[ethics reviews] im rahmen der datenwissenschaftlichen projektplanung. Die Sensibilisierung für Vorurteile, die Berücksichtigung unserer eigenen unbewussten Vorurteile und die Strukturierung von Gerechtigkeit in unseren Projekten und Pipelines für maschinelles Lernen können dazu beitragen, Vorurteile in diesem Bereich zu bekämpfen.
image: https://assets.digitalocean.com/articles/machine-learning/intro-to-ml/machine-learning-book.png [DigitalOcean Machine Learning]
{kind=link}
Fazit
In diesem Lernprogramm wurden einige Anwendungsfälle des maschinellen Lernens, gängige Methoden und gängige Ansätze auf diesem Gebiet sowie geeignete Programmiersprachen für das maschinelle Lernen besprochen. Außerdem wurden einige Aspekte behandelt, die berücksichtigt werden sollten, wenn unbewusste Vorurteile in Algorithmen repliziert werden.
Da maschinelles Lernen ein Bereich ist, der ständig weiterentwickelt wird, ist es wichtig zu berücksichtigen, dass sich Algorithmen, Methoden und Ansätze weiterhin ändern werden.
Zusätzlich zum Lesen unserer Tutorials unter „https://www.digitalocean.com/community/tutorials/anleitungshandbuch-in-python-mit-scikit-lernen-So erstellen Sie ein Machine Learning Classifier in Python mit scikit-learn] “oder„ How To Perform Neuronaler Stiltransfer mit Python 3 und PyTorch. Weitere Informationen zum Arbeiten mit Daten in der Technologiebranche finden Sie in unseren Data Analysis -Tutorials .