Einführung
Da Websites und Webanwendungen immer umfangreicher und komplexer werden, ist die Leistung für Entwickler und Benutzer gleichermaßen von großer Bedeutung. Da studies zeigt, dass schnellere Websites zu mehr Nutzern, mehr Verkäufen und mehr Verkehr führen, ist es wichtig, darauf zu achten, wie schnell Sie Ihre Website an Ihre Nutzer liefern und wiedergeben können ihren Browser.
Der allgemeine Begriff für diesen Wissensbereich lautet "Web-Leistungsoptimierung", und in den letzten Jahren wurden viele bewährte Methoden, Techniken und Technologien entwickelt, um das Web-Erlebnis zu verbessern. Viele dieser Techniken konzentrieren sich auf die Reduzierung der Downloadgröße von Webseiten, die Optimierung von JavaScript und die Begrenzung der Anzahl der einzelnen HTTP-Anforderungen, die eine Seite benötigt.
In diesem Artikel gehen wir auf die andere Seite der Webleistung ein: Wie schnell kann Ihr Server auf die Anforderungen Ihrer Benutzer reagieren? Wir werden die allgemeine Landschaft der Auslastungstests überprüfen, einen Plan durchgehen, um die maximale praktische Antwortrate Ihres Servers zu ermitteln, und einige Open-Source-Auslastungstestsoftware diskutieren.
Glossar
Bevor wir beginnen, klären wir einige relevante Begriffe und Konzepte:
-
* Latenz * ist ein Maß dafür, * wie schnell * ein Server auf Anforderungen des Clients reagiert. Die Latenz wird in der Regel in Millisekunden (ms) gemessen und häufig als * Reaktionszeit * bezeichnet. Niedrigere Zahlen bedeuten schnellere Antworten. Die Latenz wird auf der Clientseite vom Zeitpunkt des Sendens der Anforderung bis zum Empfang der Antwort gemessen. Der Netzwerkaufwand ist in dieser Nummer enthalten.
-
* Durchsatz * ist * wie viele Anforderungen * der Server in einem bestimmten Zeitintervall verarbeiten kann, normalerweise als * Anforderungen pro Sekunde * angegeben.
-
* Percentiles * (Perzentile) sind eine Methode zum Gruppieren der Ergebnisse nach ihrem Prozentsatz des gesamten Stichprobenumfangs. Wenn Ihre Antwortzeit für das 50. Perzentil 100 ms beträgt, bedeutet dies, dass 50% der Anforderungen innerhalb von 100 ms oder weniger zurückgegeben wurden. Die folgende Grafik zeigt, warum es nützlich ist, Ihre Messungen prozentual zu betrachten: + image: https: //assets.digitalocean.com/articles/load-testing/p99.png [Ein Beispieldiagramm der Latenz im Vergleich zu Zeit, die eine große Spitze im 99. Perzentil zeigt] + Die obige Grafik zeigt die Latenz eines Webservers über einen bestimmten Zeitraum. Auch wenn die durchschnittliche Antwortzeit ziemlich konstant ist, weist die 99. Perzentillinie einen großen Spitzenwert auf. Dies bedeutet, dass 1% der Nutzeranfragen sogar schlechter abschnitten als diese 99-Perzentil-Messung, während der Durchschnitt relativ stabil blieb. Aus diesem Grund lohnt es sich, Perzentile zu betrachten, um ein genaueres Gefühl dafür zu bekommen, was Ihre Benutzer wirklich erleben.
Grundlagen zum Laden von Tests
Beim Auslastungstest wird simulierter HTTP-Datenverkehr an einen Server gesendet, um die Leistung zu messen und einige wichtige Fragen zu beantworten, z.
-
Verfügt der Server über genügend Ressourcen (CPU, Arbeitsspeicher usw.), um die erwartete Auslastung zu bewältigen?
-
Reagiert der Server schnell genug, um eine gute Benutzererfahrung zu bieten?
-
Läuft unsere Anwendung effizient?
-
Müssen wir unsere Serverhardware skalieren oder auf mehrere Server skalieren?
-
Gibt es Seiten oder API-Aufrufe, die besonders ressourcenintensiv sind?
Lasttests werden durchgeführt, indem Lasttestsoftware auf einem Computer (oder einem Cluster von Computern) ausgeführt wird, um eine große Anzahl von Anforderungen an einen Webserver auf einem zweiten Computer (oder einer anderen komplexeren Web-Serving-Infrastruktur) zu generieren. Es gibt viele solcher Tools, und wir werden später auf eine bestimmte Software eingehen. Im Moment werden wir Lasttests mit Begriffen diskutieren, die unabhängig von der von Ihnen ausgewählten Software relevant sind.
Eine häufige Verwendung von Lasttestsoftware besteht darin, die * maximalen Anforderungen pro Sekunde * zu ermitteln, die ein Server verarbeiten kann. Dies geschieht, indem so viele Anforderungen wie möglich an einen Server gesendet werden und überprüft wird, wie viele erfolgreich zurückgegeben werden können.
Dies ist ein erster Schritt, um die maximale Kapazität Ihres Servers zu ermitteln. Es werden jedoch nur wenige Informationen zur Latenz und zur tatsächlichen täglichen Leistung Ihrer Benutzer angezeigt. Ein stark ausgelasteter Server kann möglicherweise tausend Antworten pro Sekunde zurückgeben. Wenn jedoch jede Antwort zehn Sekunden dauert, sind Ihre Benutzer wahrscheinlich unzufrieden.
Das folgende Diagramm zeigt eine Ansicht der Beziehung zwischen Durchsatz (Antworten pro Sekunde) und Latenz:
image: https://assets.digitalocean.com/articles/load-testing/latency2.png [Ein Beispieldiagramm für Latenz im Vergleich zu Anfragen, die eine positive Korrelation zwischen den beiden zeigen]
{kind=link}
Dies ist nur ein Beispiel, und jedes Setup hat ein eindeutiges Antwortprofil. Der allgemeine Trend ist jedoch, dass eine höhere Last (mehr Anforderungen pro Sekunde) zu einer höheren Latenz führt. Um eine realistischere Vorstellung von der Latenzzeit unseres Servers bei einer bestimmten Auslastung zu erhalten, müssen wir mehrere Tests mit unterschiedlichen Anforderungsraten durchführen. Nicht jede Lasttestsoftware ist dazu in der Lage, aber später werden wir uns mit + wrk2 + befassen, einem Befehlszeilen-Lasttest-Tool, das diese Funktion ausführen kann.
Nachdem wir nun ein allgemeines Verständnis für Lasttests haben, wollen wir einen bestimmten Plan diskutieren, um die Leistung unseres Servers zu untersuchen.
Ein Lasttestplan
Es gibt einige allgemeine Schritte, die Sie ausführen können, um sich ein Bild von der Leistung Ihres Servers und Ihrer Webanwendung zu machen und auf das Laden zu reagieren. Zunächst werden wir sicherstellen, dass wir während des Auslastungstests die richtigen Systemressourcen überwachen. Anschließend ermitteln wir die absolute maximale Anzahl von Anfragen pro Sekunde, die unser Server ausführen kann. Schließlich finden wir den maximalen Durchsatz, bei dem die Latenz unseres Servers zu einer inakzeptablen Leistung für unsere Benutzer führen würde.
Schritt 1 - Ressourcen überwachen
Unsere Auslastungstestsoftware gibt uns Informationen zu Anforderungen und Latenzzeiten. Es ist jedoch hilfreich, einige andere Systemmetriken zu überwachen, um festzustellen, ob der Server bei hohem Datenverkehrsaufkommen ressourcenbeschränkt ist.
Wir beschäftigen uns hauptsächlich mit der CPU-Auslastung und dem freien Speicher. Wenn Sie diese Informationen unter hoher Auslastung betrachten, können Sie fundiertere Entscheidungen darüber treffen, wie die Infrastruktur skaliert werden soll und wo Sie sich bei der Entwicklung Ihrer Anwendung konzentrieren müssen.
Wenn Sie bereits ein Überwachungssystem eingerichtet haben (z. B. Prometheus oder https://www.digitalocean.com/community/tutorials/an-einführung-zum-verfolgen- von-statistiken-mit-graphit-statistiken-und-sammelreifenGraphit und Sammeln]) fertig. Wenn nicht, melden Sie sich über SSH bei Ihrem Webserver an und verwenden Sie die folgenden Befehlszeilentools, um in Echtzeit zu überwachen.
Um den verfügbaren Speicher zu überprüfen, können Sie den Befehl + free + verwenden. Kombinieren Sie es mit + watch +, um die Ausgabe regelmäßig (standardmäßig alle zwei Sekunden) zu aktualisieren:
watch free -hDas + -h + Flag weist + free + an, die Zahlen in einem für Menschen lesbaren Format anstelle von Bytes auszugeben:
Output total used free shared buffers cached
Mem: 489M 261M 228M 352K 7.5M 213M
-/+ buffers/cache: 39M
Swap: 0B 0B 0BDie in der obigen Ausgabe hervorgehobene Zahl gibt den freien Speicher nach Abzug der Puffer- und Cache-Nutzung an. Neuere Versionen von "+ free +" haben die Ausgabe geändert:
Output total used free shared buff/cache available
Mem: 488M 182M 34M 14M 271M
Swap: 0B 0B 0BDie neue Spalte "+ verfügbar +" wird geringfügig anders berechnet, stellt jedoch im Allgemeinen dieselbe Metrik dar: Speicher, der derzeit für Anwendungen zur Verfügung steht.
Um die CPU-Auslastung über die Befehlszeile zu überwachen, ist mpstat ein gutes Dienstprogramm, das eine aktualisierte Ansicht der Menge der CPU-Ressourcen im Leerlauf bietet. mpstat ist unter Ubuntu nicht standardmäßig installiert. Sie können es mit dem folgenden Befehl installieren:
sudo apt-get install sysstatWenn Sie "+ mpstat +" starten, müssen Sie die Anzahl der Sekunden angeben, die zwischen den Aktualisierungen liegen sollen:
mpstat 2Dies gibt alle zwei Sekunden eine Kopfzeile und dann eine Reihe von Statistiken aus:
OutputLinux 4.4.0-66-generic (example-server) 08/21/2017 _x86_64_ (4 CPU)
08:06:26 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice
08:06:28 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:06:30 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00+% idle + zeigt uns den Prozentsatz der nicht verwendeten CPU-Ressourcen. Der Grund, warum wir uns ansehen, wie viel * im Leerlauf * statt wie viel * verwendet wird *, ist, dass die CPU-Auslastung häufig in verschiedene Kategorien wie * Benutzer * CPU und * System * CPU aufgeteilt wird. Anstatt diese spontan zu addieren, betrachten wir die Leerlaufseite der Gleichung.
Nachdem wir nun die Ressourcen unseres Servers beobachten können, führen wir einen ersten Auslastungstest durch, um die maximale Antwortrate unseres Servers zu ermitteln.
Schritt 2 - Ermitteln der maximalen Rücklaufquote
Wie bereits erwähnt, eignen sich die meisten Lasttestsoftware besonders gut, um die maximale Antwortrate Ihres Webservers zu ermitteln. Die einzigen Optionen, die Sie festlegen müssen, sind häufig die gewünschte Währung und die Dauer des Tests.
Parallelität ist ein Maß dafür, wie viele parallele Verbindungen zum Server hergestellt werden. 100 ist eine sichere Standardeinstellung. Sie können jedoch eine fundiertere Auswahl treffen, indem Sie die Einstellungen Ihres Webservers für "+ MaxClients ", " MaxThreads +" oder ähnliche Einstellungen überprüfen, um festzustellen, wie viele gleichzeitige Verbindungen verarbeitet werden können.
Zusätzlich zum Festlegen dieser Optionen müssen Sie eine URL auswählen, die für den Test verwendet werden soll. Wenn Ihre Software jeweils nur eine URL verarbeiten kann, empfiehlt es sich, mehrere Tests mit wenigen unterschiedlichen URLs durchzuführen, da die Verarbeitungsanforderungen beispielsweise zwischen Ihrer Homepage und einer Produktseite, für deren Laden mehrere Datenbankabfragen erforderlich sind, stark variieren können .
Alternativ können Sie mit einigen Lasttestsoftware mehrere zu testende URLs gleichzeitig angeben. Dies ist eine gute Möglichkeit, den realen Verkehr genauer zu simulieren. Wenn Sie über vorhandene Site-Nutzungsdaten (aus Analysesoftware oder Serverprotokollen) verfügen, können Sie Ihre Test-URLs eng mit den beobachteten Werten abstimmen.
Wenn Sie die zu testende (n) URL (s) aussortiert haben, führen Sie den Auslastungstest aus. Stellen Sie sicher, dass Ihre Software Anforderungen so schnell wie möglich sendet. Wenn Sie Software verwenden, für die Sie die Anforderungsrate auswählen müssen, wählen Sie einen Wert, der mit ziemlicher Sicherheit zu groß ist. Wenn Ihre Software eine konfigurierbare Verzögerung zwischen Anforderungen aufweist, reduzieren Sie diese auf Null.
Sie sollten sehen, dass Ihre CPU- und Speicherressourcen verbraucht werden. Ihr CPU-Leerlauf erreicht möglicherweise 0% und Ihr Lasttest-Client kann einige Verbindungsfehler erhalten, da Ihr Server Probleme hat, mit allen Anforderungen Schritt zu halten. Dies ist normal, da der Server an seine Grenzen stößt.
Wenn alles vorbei ist, gibt Ihre Software einige Statistiken aus, darunter * Anfragen pro Sekunde *. Beachten Sie auch die * Reaktionszeit *: Sie ist wahrscheinlich sehr schlecht, da der Server extrem überfordert sein sollte. Aus diesem Grund ist die Anzahl der Anfragen pro Sekunde kein guter Indikator für den tatsächlichen maximalen Durchsatz Ihres Servers, aber ein guter Ausgangspunkt für weitere Untersuchungen.
Als Nächstes rufen wir die Last zurück und testen erneut, um weitere Informationen zur Leistung unseres Servers zu erhalten, wenn dieser nicht an sein absolutes Limit stößt.
Schritt 3 - Finden Sie den maximalen praktischen Durchsatz
Für diesen Schritt benötigen wir eine Lasttestsoftware, mit der die Last ein wenig zurückgesetzt werden kann, um die Leistung unseres Servers bei unterschiedlichen Durchsatzraten zu testen. Einige Softwareprogramme ermöglichen dies, indem Sie eine Verzögerung zwischen den einzelnen Anforderungen angeben. Dies erschwert jedoch das Festlegen eines genauen Durchsatzes.
Glücklicherweise können Sie mit + wrk2 + ein genaues Ziel für Anforderungen pro Sekunde angeben. Dazu werden zunächst einige Kalibrierungsanforderungen ausgeführt, um das richtige Timing zu erreichen.
Nehmen Sie Ihre maximale Anforderungsrate aus dem vorherigen Schritt und halbieren Sie sie. Führen Sie einen weiteren Test mit dieser neuen Rate durch und notieren Sie die Antwortzeit. Ist es noch im akzeptablen Bereich?
Wenn ja, erhöhen Sie die Rate wieder in Richtung des Maximalwerts. Testen Sie dabei, bis Ihre Latenz den von Ihnen als akzeptabel erachteten Maximalwert erreicht hat. Dies ist die tatsächliche maximale Antwortrate, die Ihr Server verarbeiten kann, bevor die Leistung Ihrer Benutzer beeinträchtigt wird.
Als Nächstes schauen wir uns einige Open-Source-Softwarepakete an, die uns bei der Implementierung unseres Lasttestplans helfen.
Laden Sie die Testsoftware
Es gibt viele Open-Source-Softwarepakete, die zum Testen der Last zur Verfügung stehen. Darüber hinaus gibt es viele kommerzielle Dienste, die eine Lasttestinfrastruktur für Sie ausführen und aus den Testdaten automatisch Diagramme und Berichte erstellen. Diese Dienste sind möglicherweise eine gute Wahl für Unternehmen, die zum Testen einer umfangreichen Infrastruktur eine hohe Auslastung benötigen, da die meisten von ihnen Computercluster ausführen, um wesentlich mehr Anforderungen zu generieren als ein einzelner Server.
Einige der Open Source-Tools können jedoch auch im Cluster-Modus ausgeführt werden. Lassen Sie uns einige der beliebtesten Open Source-Tools durchgehen und ihre Funktionen zusammenfassen:
ab
ab (auch als ApacheBench bekannt) ist ein einfaches Befehlszeilentool mit einem Thread zum Benchmarking eines HTTP-Servers. Obwohl es ursprünglich als Teil des Apache HTTP-Servers vertrieben wurde, können Sie mit ab jeden HTTP- oder HTTPS-Server testen.
Da es sich um ein Single-Thread-Verfahren handelt, können nicht mehrere Prozessoren zum Senden einer großen Menge von Anforderungen verwendet werden. Dies kann einschränkend sein, wenn Sie versuchen, einen leistungsstarken Webserver vollständig zu laden.
Ein grundlegender Aufruf des Befehls "+ ab +" sieht folgendermaßen aus:
ab -n 1000 -c 100Sie geben die Anzahl der Anfragen (+ -n +) und die Parallelität (+ -c +) an und geben dann eine einzelne URL an, die abgerufen werden soll. Die Ausgabe - unten auszugsweise - enthält Anforderungen pro Sekunde, Anforderungszeit und eine Auflistung verschiedener Perzentile für die Antwortzeit:
Output. . .
Time per request: 1.361 [ms] (mean, across all concurrent requests)
Transfer rate: 60645.11 [Kbytes/sec] received
Percentage of the requests served within a certain time (ms)JMeter
JMeter ist eine leistungsstarke und funktionsreiche App für Auslastungstests und Funktionstests von Apache Software Foundation. Funktionstests bedeuten, dass JMeter auch testen kann, ob Ihre Website oder Anwendung die richtige Ausgabe erzeugt.
JMeter verfügt über eine Java-GUI zum Einrichten von Testplänen:
image: https://assets.digitalocean.com/articles/load-testing/jmeter.png [Die JMeter-Standardschnittstelle]
{kind=link}
Testpläne können mit dem Web-Proxy von JMeter zur Verkehrsaufzeichnung und einem normalen Browser aufgezeichnet werden. Auf diese Weise können Sie mit Datenverkehr testen, der die reale Nutzung genauer simuliert.
JMeter kann Perzentilinformationen in HTML-Berichten und anderen Formaten ausgeben.
Siege
Siege ist ein weiteres Tool zum Testen der Befehlszeilenlast, ähnlich wie ab, jedoch mit einigen anderen Funktionen. Die Belagerung erfolgt mit mehreren Threads, was einen relativ hohen Durchsatz ermöglicht. Außerdem können Sie eine Liste mit mehreren URLs bereitstellen, die einer Lastprüfung unterzogen werden sollen. Ein grundlegender Aufruf folgt:
siege -c 100 -t 30sDies erfordert 100 gleichzeitige Anforderungen ("+ -c 100 ") und einen 30-Sekunden-Test (" -t 30s +"). Siege gibt die durchschnittliche Antwortzeit und die Anforderungsrate aus:
Output. . .
Transactions: 5810 hits
Availability: 100.00 %
Elapsed time: 29.47 secs
Data transferred: 135.13 MB
Throughput: 4.59 MB/sec
Concurrency: 2.23
. . .Siege bietet keine Aufschlüsselung der Perzentile für die Latenzstatistik.
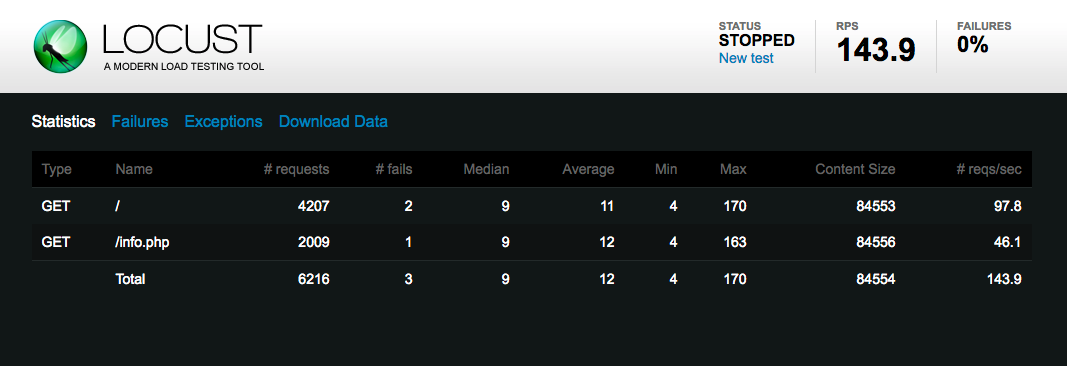
Locust
Locust ist ein Python-basiertes Lasttest-Tool mit einer Echtzeit-Web-Benutzeroberfläche zur Überwachung der Ergebnisse:
image: https://assets.digitalocean.com/articles/load-testing/locust.png [Die Seite mit den Locust-Testergebnissen]
{kind=link}
Sie schreiben Locust-Testszenarien in Python-Code und ermöglichen so eine leistungsstarke Konfiguration, die für diejenigen geeignet ist, die bereits mit der Sprache vertraut sind.
Locust kann auch im verteilten Modus ausgeführt werden, in dem Sie einen Cluster von Locust-Servern ausführen und diese auf koordinierte Weise laden lassen können. Dies erleichtert das Testen der Auslastung einer leistungsfähigen Web-Serving-Infrastruktur.
Locust kann detaillierte Statistiken und Perzentilinformationen in herunterladbaren CSV-Dateien bereitstellen.
wrk2
wrk2 ist ein Multithread-Tool zum Testen der Befehlszeilenlast, mit dem eine Last mit einer festgelegten Anforderungsrate erzeugt werden kann. Es kann detaillierte Latenzstatistiken bereitstellen und ist mit der Programmiersprache Lua skriptfähig.
wrk2 wird mit dem Befehl "+ wrk " aufgerufen (es ist eine Verzweigung des ursprünglichen " wrk +"):
wrk -t4 -c100 -d30s -R100 --latencyDie obigen Optionen geben vier Threads ("+ -t4 ", Sie sollten die Anzahl der Prozessorkerne auf Ihrem Computer verwenden), 100 gleichzeitige Anforderungen (" -c100 "), eine Testperiode von 30 Sekunden (" -d30s ") an. und eine Anforderungsrate von 100 Anforderungen pro Sekunde (" -R100 "). Zuletzt fordern wir eine detaillierte Latenzausgabe mit ` - Latenz +` an:
Output. . .
Latency Distribution (HdrHistogram - Recorded Latency)
50.000% 5.79ms
75.000% 7.58ms
90.000% 10.19ms
99.000% 29.30ms
99.900% 30.69ms
99.990% 31.36ms
99.999% 31.36ms
100.000% 31.36ms
. . .Die obige Ausgabe ist ein Auszug - es werden auch detailliertere Latenzperzentile gedruckt.
Fazit
In diesem Artikel haben wir einige Terminologien und Grundkonzepte für Auslastungstests besprochen, einen Plan durchlaufen, um die maximalen praktischen Anforderungen pro Sekunde zu ermitteln, Systemressourcen für zukünftige Entscheidungen über Hardware- und Entwicklungsbemühungen beobachtet und einige der verfügbaren Open Source-Lösungen untersucht Lasttestsoftware.
Nachdem Sie die Leistung Ihrer Infrastruktur gemessen haben, können Sie anhand dieser Informationen versuchen, die Antwortzeiten zu verbessern und die Serverauslastung zu verringern. Möglicherweise möchten Sie Ihre Webserver-Hardware mit mehreren Servern und einem Lastenausgleich erweitern oder verkleinern. Sie können versuchen, Ihre Webserverkonfiguration zu optimieren, um die Anzahl der zulässigen Verbindungen oder die Anzahl der verwendeten Arbeitsprozesse oder Threads zu optimieren. Sie können sich auch mit dem Zwischenspeichern von Daten befassen, auf die häufig zugegriffen wird, um die Datenbankbelastung und die Abfragezeit zu verringern.
Die oben genannten Themen und mehr finden Sie unter our collection of * Server Optimization * tagged tutorials.