Einführung
Zeitreihen bieten die Möglichkeit, zukünftige Werte vorherzusagen. Basierend auf früheren Werten können Zeitreihen verwendet werden, um Trends in den Bereichen Wirtschaft, Wetter und Kapazitätsplanung vorherzusagen, um nur einige zu nennen. Aufgrund der spezifischen Eigenschaften von Zeitreihendaten sind in der Regel spezielle statistische Methoden erforderlich.
In diesem Tutorial wollen wir zuverlässige Prognosen für Zeitreihen erstellen. Wir werden zunächst die Konzepte von Autokorrelation, Stationarität und Saisonalität einführen und diskutieren und dann eine der am häufigsten verwendeten Methoden zur Vorhersage von Zeitreihen anwenden, die als ARIMA bezeichnet wird.
Eine der in Python verfügbaren Methoden zur Modellierung und Vorhersage zukünftiger Punkte einer Zeitreihe istSARIMAX, was fürSeasonal AutoRegressive Integrated Moving Averages with eXogenous regressors steht. Hier konzentrieren wir uns hauptsächlich auf die ARIMA-Komponente, mit der Zeitreihendaten angepasst werden, um zukünftige Punkte in der Zeitreihe besser zu verstehen und vorherzusagen.
Voraussetzungen
In diesem Handbuch wird beschrieben, wie Sie Zeitreihen auf einem lokalen Desktop oder einem Remote-Server analysieren. Das Arbeiten mit großen Datenmengen kann speicherintensiv sein. In beiden Fällen benötigt der Computer mindestens2GB of memory, um einige der Berechnungen in diesem Handbuch durchzuführen.
Um dieses Lernprogramm optimal nutzen zu können, ist es hilfreich, sich mit Zeitreihen und Statistiken vertraut zu machen.
In diesem Tutorial verwenden wirJupyter Notebook, um mit den Daten zu arbeiten. Wenn Sie es noch nicht haben, sollten Sie unserentutorial to install and set up Jupyter Notebook for Python 3 folgen.
[[Schritt-1 - Installieren von Paketen]] == Schritt 1 - Installieren von Paketen
Um unsere Umgebung für die Vorhersage von Zeitreihen einzurichten, gehen wir zunächst zu unserenlocal programming environment oderserver-based programming environment über:
cd environments. my_env/bin/activateErstellen wir von hier aus ein neues Verzeichnis für unser Projekt. Wir werden esARIMA nennen und dann in das Verzeichnis wechseln. Wenn Sie dem Projekt einen anderen Namen geben, müssen SieARIMA im gesamten Handbuch durch Ihren Namen ersetzen
mkdir ARIMA
cd ARIMAFür dieses Lernprogramm sind die Bibliothekenwarnings,itertools,pandas,numpy,matplotlib undstatsmodelserforderlich. Die Bibliothekenwarnings unditertoolsind im Standard-Python-Bibliothekssatz enthalten, sodass Sie sie nicht installieren müssen.
Wie bei anderen Python-Paketen können wir diese Anforderungen mitpip.
installieren. Wir können jetztpandas,statsmodels und das Datenplot-Paketmatplotlib installieren. Ihre Abhängigkeiten werden ebenfalls installiert:
pip install pandas numpy statsmodels matplotlibJetzt können wir mit den installierten Paketen arbeiten.
[[Schritt 2 - Importieren von Paketen und Laden von Daten] == Schritt 2 - Importieren von Paketen und Laden von Daten
Um mit unseren Daten zu arbeiten, starten wir Jupyter Notebook:
jupyter notebookUm eine neue Notebook-Datei zu erstellen, wählen Sie im Pulldown-Menü oben rechtsNew>Python 3 aus:
Dies öffnet ein Notizbuch.
Beginnen Sie wie empfohlen mitimporting the libraries, die Sie oben in Ihrem Notizbuch benötigen:
import warnings
import itertools
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')Wir haben auch einen Prozentsatz (t0) von fünfunddreißig für unsere Parzellen definiert.
Wir werden mit einem Datensatz namens "Atmosphärisches CO2 aus kontinuierlichen Luftproben am Mauna Loa Observatory, Hawaii, USA" arbeiten, der von März 1958 bis Dezember 2001 CO2-Proben sammelte. Wir können diese Daten wie folgt einbringen:
data = sm.datasets.co2.load_pandas()
y = data.dataLassen Sie uns unsere Daten ein wenig vorverarbeiten, bevor wir fortfahren. Es kann schwierig sein, mit wöchentlichen Daten zu arbeiten, da die Zeit dafür kürzer ist. Verwenden wir stattdessen die Monatsmittelwerte. Wir werden die Konvertierung mit der Funktionresampledurchführen. Der Einfachheit halber können wir auchfillna() function verwenden, um sicherzustellen, dass in unseren Zeitreihen keine Werte fehlen.
# The 'MS' string groups the data in buckets by start of the month
y = y['co2'].resample('MS').mean()
# The term bfill means that we use the value before filling in missing values
y = y.fillna(y.bfill())
print(y)Outputco2
1958-03-01 316.100000
1958-04-01 317.200000
1958-05-01 317.433333
...
2001-11-01 369.375000
2001-12-01 371.020000Untersuchen wir diese Zeitreihe e als Datenvisualisierung:
y.plot(figsize=(15, 6))
plt.show()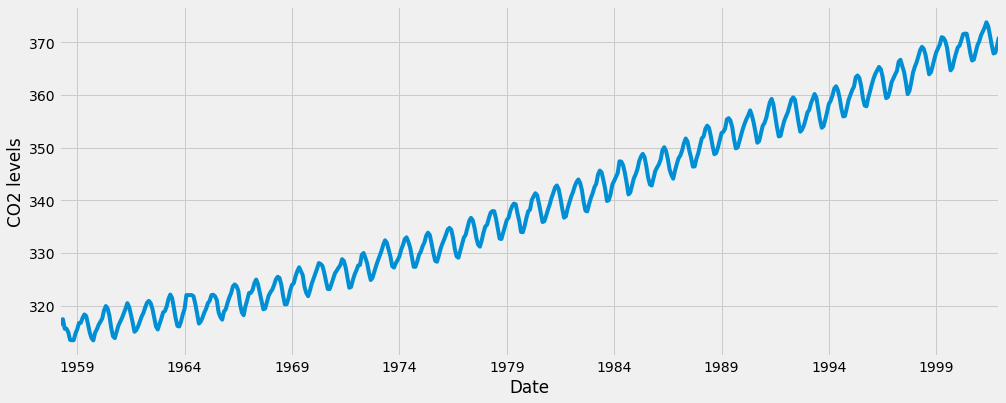
Einige unterscheidbare Muster erscheinen, wenn wir die Daten zeichnen. Die Zeitreihen weisen ein offensichtliches Saisonalitätsmuster sowie einen insgesamt zunehmenden Trend auf.
Weitere Informationen zur Vorverarbeitung von Zeitreihen finden Sie unter „https://www.digitalocean.com/community/tutorials/a-guide-to-time-series-visualization-with-python-3[A Guide to Time“ Serienvisualisierung mit Python 3] “, in der die obigen Schritte ausführlicher beschrieben werden.
Nachdem wir unsere Daten konvertiert und untersucht haben, fahren wir mit der Prognose von Zeitreihen mit ARIMA fort.
[[Schritt 3 - Das Arima-Zeitreihenmodell]] == Schritt 3 - Das ARIMA-Zeitreihenmodell
Eine der am häufigsten verwendeten Methoden bei der Vorhersage von Zeitreihen ist das ARIMA-Modell, das fürAutoregRessiveIntegratedMvingAverage steht. ARIMA ist ein Modell, das an Zeitreihendaten angepasst werden kann, um zukünftige Punkte in der Reihe besser zu verstehen oder vorherzusagen.
Es gibt drei verschiedene Ganzzahlen (p,d,q), die zur Parametrisierung von ARIMA-Modellen verwendet werden. Aus diesem Grund werden ARIMA-Modelle mit der NotationARIMA(p, d, q) bezeichnet. Zusammen berücksichtigen diese drei Parameter die Saisonalität, den Trend und das Rauschen in Datasets:
-
pist derauto-regressive Teil des Modells. Es ermöglicht uns, den Effekt vergangener Werte in unser Modell einzubeziehen. Intuitiv wäre dies vergleichbar mit der Aussage, dass es morgen wahrscheinlich warm ist, wenn es in den letzten 3 Tagen warm gewesen ist. -
dist derintegrated Teil des Modells. Dies schließt Begriffe in das Modell ein, die das Ausmaß der Differenzierung enthalten (d. H. Die Anzahl der vergangenen Zeitpunkte, die vom aktuellen Wert subtrahiert werden sollen, um auf die Zeitreihe angewendet zu werden. Intuitiv wäre dies vergleichbar mit der Aussage, dass es morgen wahrscheinlich die gleiche Temperatur sein wird, wenn der Temperaturunterschied in den letzten drei Tagen sehr gering war. -
qist dermoving average Teil des Modells. Dies ermöglicht es uns, den Fehler unseres Modells als eine lineare Kombination der Fehlerwerte festzulegen, die zu früheren Zeitpunkten in der Vergangenheit beobachtet wurden.
Beim Umgang mit saisonalen Effekten verwenden wir die ARIMAseasonal, die alsARIMA(p,d,q)(P,D,Q)s bezeichnet wird. Hier sind(p, d, q) die oben beschriebenen nicht-saisonalen Parameter, während(P, D, Q) der gleichen Definition folgen, jedoch auf die saisonale Komponente der Zeitreihe angewendet werden. Der Begriffs ist die Periodizität der Zeitreihen (4 für vierteljährliche Perioden,12 für jährliche Perioden usw.).
Die saisonale ARIMA-Methode kann aufgrund der Vielzahl der beteiligten Optimierungsparameter entmutigend wirken. Im nächsten Abschnitt wird beschrieben, wie der Prozess zur Ermittlung des optimalen Parametersatzes für das saisonale ARIMA-Zeitreihenmodell automatisiert wird.
[[Schritt-4 -—- Parameterauswahl-für-das-Arima-Zeitreihenmodell]] == Schritt 4 - Parameterauswahl für das ARIMA-Zeitreihenmodell
Bei der Anpassung von Zeitreihendaten an ein saisonales ARIMA-Modell besteht unser erstes Ziel darin, die Werte vonARIMA(p,d,q)(P,D,Q)szu ermitteln, die eine interessierende Metrik optimieren. Es gibt viele Richtlinien und Best Practices, um dieses Ziel zu erreichen. Die korrekte Parametrisierung von ARIMA-Modellen kann jedoch ein sorgfältiger manueller Prozess sein, der Fachwissen und Zeit erfordert. Andere statistische Programmiersprachen wieR bietenautomated ways to solve this issue, diese müssen jedoch noch auf Python portiert werden. In diesem Abschnitt beheben wir dieses Problem, indem wir Python-Code schreiben, um programmgesteuert die optimalen Parameterwerte für das Zeitreihenmodell vonARIMA(p,d,q)(P,D,Q)sauszuwählen.
Wir werden eine "Rastersuche" verwenden, um iterativ verschiedene Kombinationen von Parametern zu untersuchen. Für jede Kombination von Parametern passen wir ein neues saisonales ARIMA-Modell mit der FunktionSARIMAX()aus dem Modulstatsmodelsan und bewerten dessen Gesamtqualität. Sobald wir die gesamte Parameterlandschaft untersucht haben, wird unser optimaler Parametersatz derjenige sein, der die beste Leistung für unsere interessierenden Kriterien erbringt. Beginnen wir mit der Generierung der verschiedenen Parameterkombinationen, die wir bewerten möchten:
# Define the p, d and q parameters to take any value between 0 and 2
p = d = q = range(0, 2)
# Generate all different combinations of p, q and q triplets
pdq = list(itertools.product(p, d, q))
# Generate all different combinations of seasonal p, q and q triplets
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))OutputExamples of parameter combinations for Seasonal ARIMA...
SARIMAX: (0, 0, 1) x (0, 0, 1, 12)
SARIMAX: (0, 0, 1) x (0, 1, 0, 12)
SARIMAX: (0, 1, 0) x (0, 1, 1, 12)
SARIMAX: (0, 1, 0) x (1, 0, 0, 12)Wir können nun die oben definierten Tripletts von Parametern verwenden, um den Prozess des Trainings und der Bewertung von ARIMA-Modellen für verschiedene Kombinationen zu automatisieren. In Statistik und maschinellem Lernen wird dieser Prozess als Rastersuche (oder Hyperparameteroptimierung) für die Modellauswahl bezeichnet.
Bei der Auswertung und dem Vergleich statistischer Modelle, die mit unterschiedlichen Parametern ausgestattet sind, kann jedes anhand der Übereinstimmung mit den Daten oder der Fähigkeit, zukünftige Datenpunkte genau vorherzusagen, in eine Rangfolge gebracht werden. Wir werden den WertAIC (Akaike Information Criterion) verwenden, der bequem mit ARIMA-Modellen zurückgegeben wird, die mitstatsmodels ausgestattet sind. DerAIC misst, wie gut ein Modell zu den Daten passt, wobei die Gesamtkomplexität des Modells berücksichtigt wird. Einem Modell, das bei Verwendung vieler Features sehr gut zu den Daten passt, wird ein höherer AIC-Wert zugewiesen als einem Modell, das weniger Features verwendet, um die gleiche Anpassungsgüte zu erzielen. Daher sind wir daran interessiert, das Modell zu finden, das den niedrigstenAIC-Wert liefert.
Der folgende Codeblock durchläuft Kombinationen von Parametern und verwendet die FunktionSARIMAX vonstatsmodels, um das entsprechende saisonale ARIMA-Modell anzupassen. Hier gibt das Argumentorder die Parameter(p, d, q)an, während das Argumentseasonal_orderdie saisonale Komponente(P, D, Q, S)des saisonalen ARIMA-Modells angibt. Nach dem Anpassen jederSARIMAX()+`model, the code prints out its respective `+AIC Punktzahl.
warnings.filterwarnings("ignore") # specify to ignore warning messages
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continueDa einige Parameterkombinationen zu numerischen Fehlern führen können, haben wir Warnmeldungen explizit deaktiviert, um eine Überlastung der Warnmeldungen zu vermeiden. Diese falschen Angaben können auch zu Fehlern führen und eine Ausnahme auslösen. Wir stellen daher sicher, dass diese Ausnahmen abgefangen werden und die Parameterkombinationen, die diese Probleme verursachen, ignoriert werden.
Der obige Code sollte die folgenden Ergebnisse liefern, dies kann einige Zeit dauern:
OutputSARIMAX(0, 0, 0)x(0, 0, 1, 12) - AIC:6787.3436240402125
SARIMAX(0, 0, 0)x(0, 1, 1, 12) - AIC:1596.711172764114
SARIMAX(0, 0, 0)x(1, 0, 0, 12) - AIC:1058.9388921320026
SARIMAX(0, 0, 0)x(1, 0, 1, 12) - AIC:1056.2878315690562
SARIMAX(0, 0, 0)x(1, 1, 0, 12) - AIC:1361.6578978064144
SARIMAX(0, 0, 0)x(1, 1, 1, 12) - AIC:1044.7647912940095
...
...
...
SARIMAX(1, 1, 1)x(1, 0, 0, 12) - AIC:576.8647112294245
SARIMAX(1, 1, 1)x(1, 0, 1, 12) - AIC:327.9049123596742
SARIMAX(1, 1, 1)x(1, 1, 0, 12) - AIC:444.12436865161305
SARIMAX(1, 1, 1)x(1, 1, 1, 12) - AIC:277.7801413828764Die Ausgabe unseres Codes legt nahe, dassSARIMAX(1, 1, 1)x(1, 1, 1, 12) den niedrigstenAIC-Wert von 277,78 ergibt. Wir sollten dies daher als optimale Option unter allen Modellen betrachten, die wir in Betracht gezogen haben.
[[Schritt 5 - Anpassen eines Arima-Zeitreihenmodells]] == Schritt 5 - Anpassen eines ARIMA-Zeitreihenmodells
Mithilfe der Rastersuche haben wir den Parametersatz ermittelt, der das am besten zu unseren Zeitreihendaten passende Modell ergibt. Wir können dieses spezielle Modell genauer analysieren.
Wir beginnen damit, die optimalen Parameterwerte in ein neuesSARIMAX-Modell einzufügen:
mod = sm.tsa.statespace.SARIMAX(y,
order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print(results.summary().tables[1])Output==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.3182 0.092 3.443 0.001 0.137 0.499
ma.L1 -0.6255 0.077 -8.165 0.000 -0.776 -0.475
ar.S.L12 0.0010 0.001 1.732 0.083 -0.000 0.002
ma.S.L12 -0.8769 0.026 -33.811 0.000 -0.928 -0.826
sigma2 0.0972 0.004 22.634 0.000 0.089 0.106
==============================================================================Das Attributsummary, das sich aus der Ausgabe vonSARIMAX ergibt, gibt eine erhebliche Menge an Informationen zurück. Wir konzentrieren uns jedoch auf die Koeffiziententabelle. Die Spaltecoef zeigt das Gewicht (d.h. Bedeutung) jedes Features und wie sich jedes auf die Zeitreihen auswirkt. Die SpalteP>|z| informiert uns über die Bedeutung jedes Merkmalsgewichts. Hier hat jedes Gewicht einen p-Wert, der niedriger oder nahe an0.05 liegt, daher ist es sinnvoll, alle in unserem Modell beizubehalten.
Beim Anpassen von saisonalen ARIMA-Modellen (und anderen Modellen) ist es wichtig, eine Modelldiagnose durchzuführen, um sicherzustellen, dass keine der vom Modell getroffenen Annahmen verletzt wurde. Mit dem Objektplot_diagnosticskönnen wir schnell Modelldiagnosen erstellen und ungewöhnliche Verhaltensweisen untersuchen.
results.plot_diagnostics(figsize=(15, 12))
plt.show()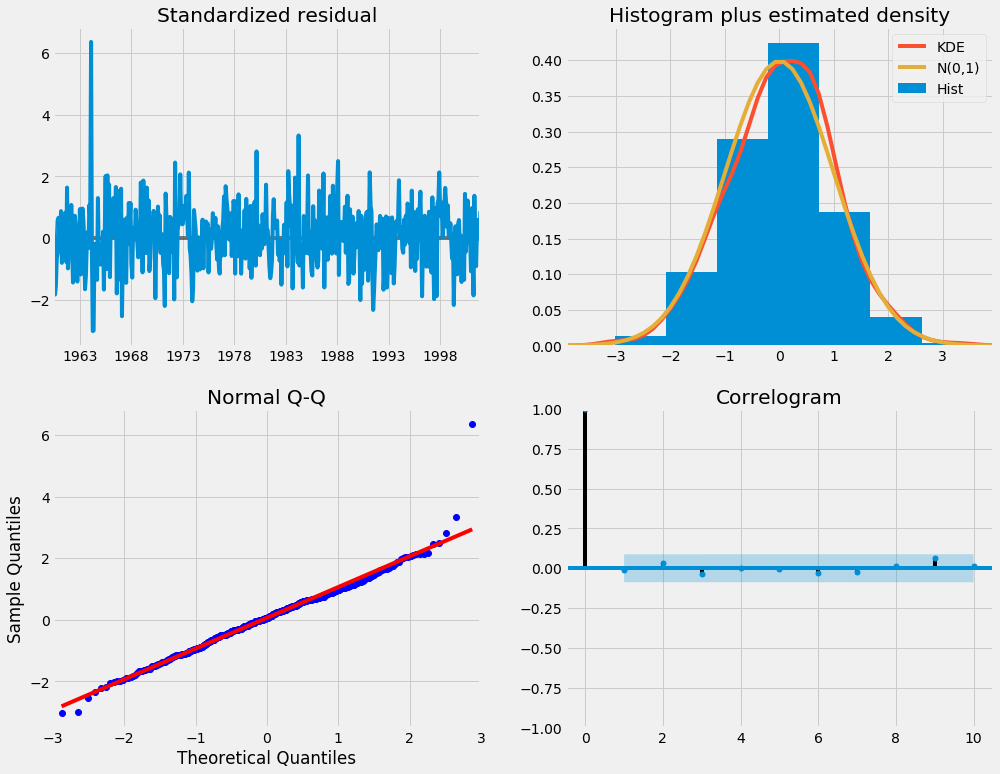
Unser Hauptanliegen ist es, sicherzustellen, dass die Residuen unseres Modells nicht korreliert und normal mit dem Mittelwert Null verteilt sind. Wenn das saisonale ARIMA-Modell diese Eigenschaften nicht erfüllt, ist dies ein guter Hinweis darauf, dass es weiter verbessert werden kann.
In diesem Fall deutet unsere Modelldiagnose darauf hin, dass die Modellreste normalerweise auf der Grundlage der folgenden Faktoren verteilt sind:
-
Im Diagramm oben rechts sehen wir, dass die rote Linie
KDEeng mit der LinieN(0,1)folgt (wobeiN(0,1)) die Standardnotation für eine Normalverteilung mit Mittelwert0ist und Standardabweichung von1). Dies ist ein guter Hinweis darauf, dass die Residuen normal verteilt sind. -
Dieqq-plot unten links zeigen, dass die geordnete Verteilung der Residuen (blaue Punkte) dem linearen Trend der Proben folgt, die aus einer Standardnormalverteilung mit
N(0, 1)entnommen wurden. Dies ist wiederum ein starker Hinweis darauf, dass die Residuen normal verteilt sind. -
Die Residuen im Zeitverlauf (Grafik oben links) zeigen keine offensichtliche Saisonalität und scheinen weißes Rauschen zu sein. Dies wird durch die Autokorrelation (d. H. Korrelogramm) unten rechts, was zeigt, dass die Zeitreihen-Residuen eine geringe Korrelation mit verzögerten Versionen von sich selbst aufweisen.
Diese Beobachtungen lassen uns den Schluss zu, dass unser Modell eine zufriedenstellende Anpassung ergibt, die uns helfen könnte, unsere Zeitreihendaten zu verstehen und zukünftige Werte vorherzusagen.
Obwohl wir eine zufriedenstellende Anpassung haben, können einige Parameter unseres saisonalen ARIMA-Modells geändert werden, um die Modellanpassung zu verbessern. Beispielsweise hat unsere Rastersuche nur eine eingeschränkte Anzahl von Parameterkombinationen berücksichtigt, sodass wir möglicherweise bessere Modelle finden, wenn wir die Rastersuche erweitern.
[[Schritt-6 -—- Validieren von Prognosen]] == Schritt 6 - Validieren von Prognosen
Für unsere Zeitreihen haben wir ein Modell erhalten, mit dem nun Prognosen erstellt werden können. Wir beginnen mit dem Vergleich der vorhergesagten Werte mit den realen Werten der Zeitreihen, um die Genauigkeit unserer Vorhersagen besser verstehen zu können. Mit den Attributenget_prediction() undconf_int() können wir die Werte und zugehörigen Konfidenzintervalle für Vorhersagen der Zeitreihen erhalten.
pred = results.get_prediction(start=pd.to_datetime('1998-01-01'), dynamic=False)
pred_ci = pred.conf_int()Der obige Code erfordert, dass die Prognosen im Januar 1998 beginnen.
Das Argumentdynamic=Falsetellt sicher, dass wir Prognosen mit einem Schritt voraus erstellen. Dies bedeutet, dass Prognosen an jedem Punkt unter Verwendung des vollständigen Verlaufs bis zu diesem Punkt erstellt werden.
Wir können die realen und prognostizierten Werte der CO2-Zeitreihe zeichnen, um zu beurteilen, wie gut wir abgeschnitten haben. Beachten Sie, wie wir das Ende der Zeitreihe durch Schneiden des Datumsindex vergrößert haben.
ax = y['1990':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead Forecast', alpha=.7)
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()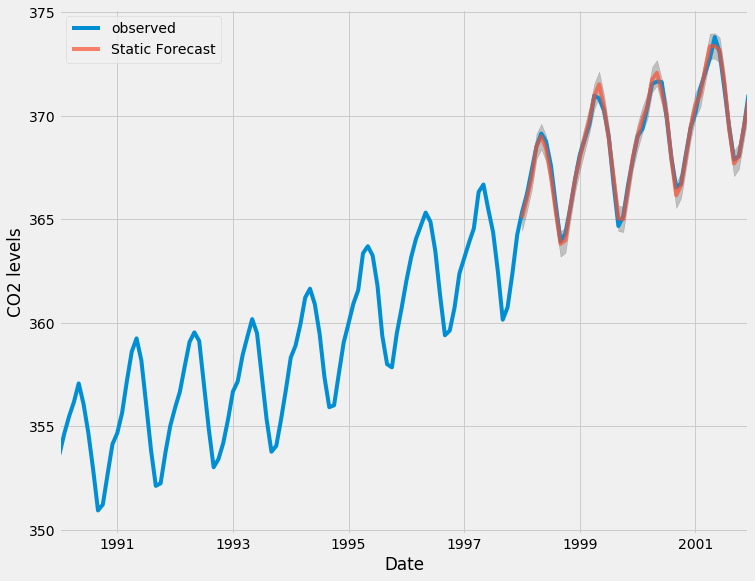
Insgesamt stimmen unsere Prognosen sehr gut mit den wahren Werten überein und zeigen einen allgemeinen Anstiegstrend.
Es ist auch nützlich, die Genauigkeit unserer Prognosen zu quantifizieren. Wir werden den MSE (Mean Squared Error) verwenden, der den durchschnittlichen Fehler unserer Prognosen zusammenfasst. Für jeden vorhergesagten Wert berechnen wir seinen Abstand zum wahren Wert und quadrieren das Ergebnis. Die Ergebnisse müssen quadriert werden, damit sich positive / negative Differenzen bei der Berechnung des Gesamtmittelwerts nicht ausgleichen.
y_forecasted = pred.predicted_mean
y_truth = y['1998-01-01':]
# Compute the mean square error
mse = ((y_forecasted - y_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))OutputThe Mean Squared Error of our forecasts is 0.07Die MSE unserer One-Step-Ahead-Prognosen ergibt einen Wert von0.07, der sehr niedrig ist, da er nahe bei 0 liegt. Ein MSE von 0 würde bedeuten, dass der Schätzer Beobachtungen des Parameters mit perfekter Genauigkeit vorhersagt. Dies wäre ein ideales Szenario, aber normalerweise nicht möglich.
Mit dynamischen Vorhersagen kann jedoch eine bessere Darstellung unserer wahren Vorhersagekraft erzielt werden. In diesem Fall verwenden wir nur Informationen aus der Zeitreihe bis zu einem bestimmten Zeitpunkt. Danach werden Vorhersagen unter Verwendung von Werten aus vorherigen prognostizierten Zeitpunkten erstellt.
Im folgenden Codeabschnitt geben wir an, ab Januar 1998 mit der Berechnung der dynamischen Vorhersagen und Konfidenzintervalle zu beginnen.
pred_dynamic = results.get_prediction(start=pd.to_datetime('1998-01-01'), dynamic=True, full_results=True)
pred_dynamic_ci = pred_dynamic.conf_int()Wenn wir die beobachteten und prognostizierten Werte der Zeitreihen zeichnen, sehen wir, dass die Gesamtprognosen auch bei Verwendung dynamischer Prognosen genau sind. Alle prognostizierten Werte (rote Linie) stimmen ziemlich genau mit der Grundwahrheit (blaue Linie) überein und liegen innerhalb der Konfidenzintervalle unserer Prognose.
ax = y['1990':].plot(label='observed', figsize=(20, 15))
pred_dynamic.predicted_mean.plot(label='Dynamic Forecast', ax=ax)
ax.fill_between(pred_dynamic_ci.index,
pred_dynamic_ci.iloc[:, 0],
pred_dynamic_ci.iloc[:, 1], color='k', alpha=.25)
ax.fill_betweenx(ax.get_ylim(), pd.to_datetime('1998-01-01'), y.index[-1],
alpha=.1, zorder=-1)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()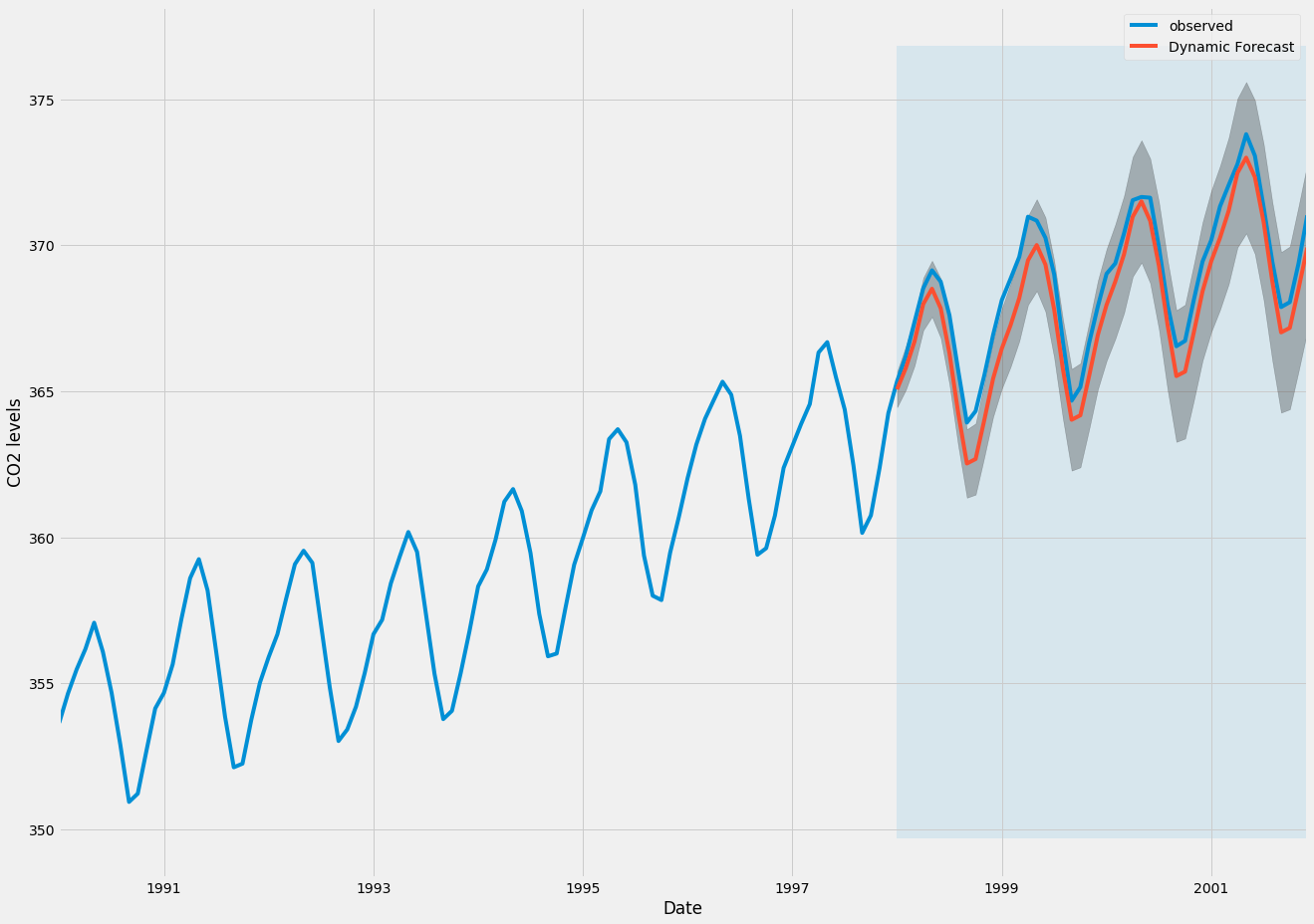
Wieder einmal quantifizieren wir die prädiktive Leistung unserer Prognosen durch Berechnung der MSE:
# Extract the predicted and true values of our time series
y_forecasted = pred_dynamic.predicted_mean
y_truth = y['1998-01-01':]
# Compute the mean square error
mse = ((y_forecasted - y_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))OutputThe Mean Squared Error of our forecasts is 1.01Die vorhergesagten Werte, die aus den dynamischen Vorhersagen erhalten werden, ergeben einen MSE von 1,01. Dies ist etwas höher als der Ein-Schritt-Vorsprung, was zu erwarten ist, da wir uns auf weniger historische Daten aus den Zeitreihen stützen.
Sowohl die einstufige Prognose als auch die dynamische Prognose bestätigen, dass dieses Zeitreihenmodell gültig ist. Das Hauptinteresse bei der Vorhersage von Zeitreihen liegt jedoch in der Möglichkeit, zukünftige Werte rechtzeitig vorherzusagen.
[[Schritt-7 - Erstellen und Visualisieren von Prognosen] == Schritt 7 - Erstellen und Visualisieren von Prognosen
Im letzten Schritt dieses Tutorials beschreiben wir, wie Sie unser saisonales ARIMA-Zeitreihenmodell nutzen können, um zukünftige Werte vorherzusagen. Das Attributget_forecast() unseres Zeitreihenobjekts kann prognostizierte Werte für eine bestimmte Anzahl von Schritten voraus berechnen.
# Get forecast 500 steps ahead in future
pred_uc = results.get_forecast(steps=500)
# Get confidence intervals of forecasts
pred_ci = pred_uc.conf_int()Wir können die Ausgabe dieses Codes verwenden, um die Zeitreihen und Prognosen seiner zukünftigen Werte zu zeichnen.
ax = y.plot(label='observed', figsize=(20, 15))
pred_uc.predicted_mean.plot(ax=ax, label='Forecast')
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.25)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()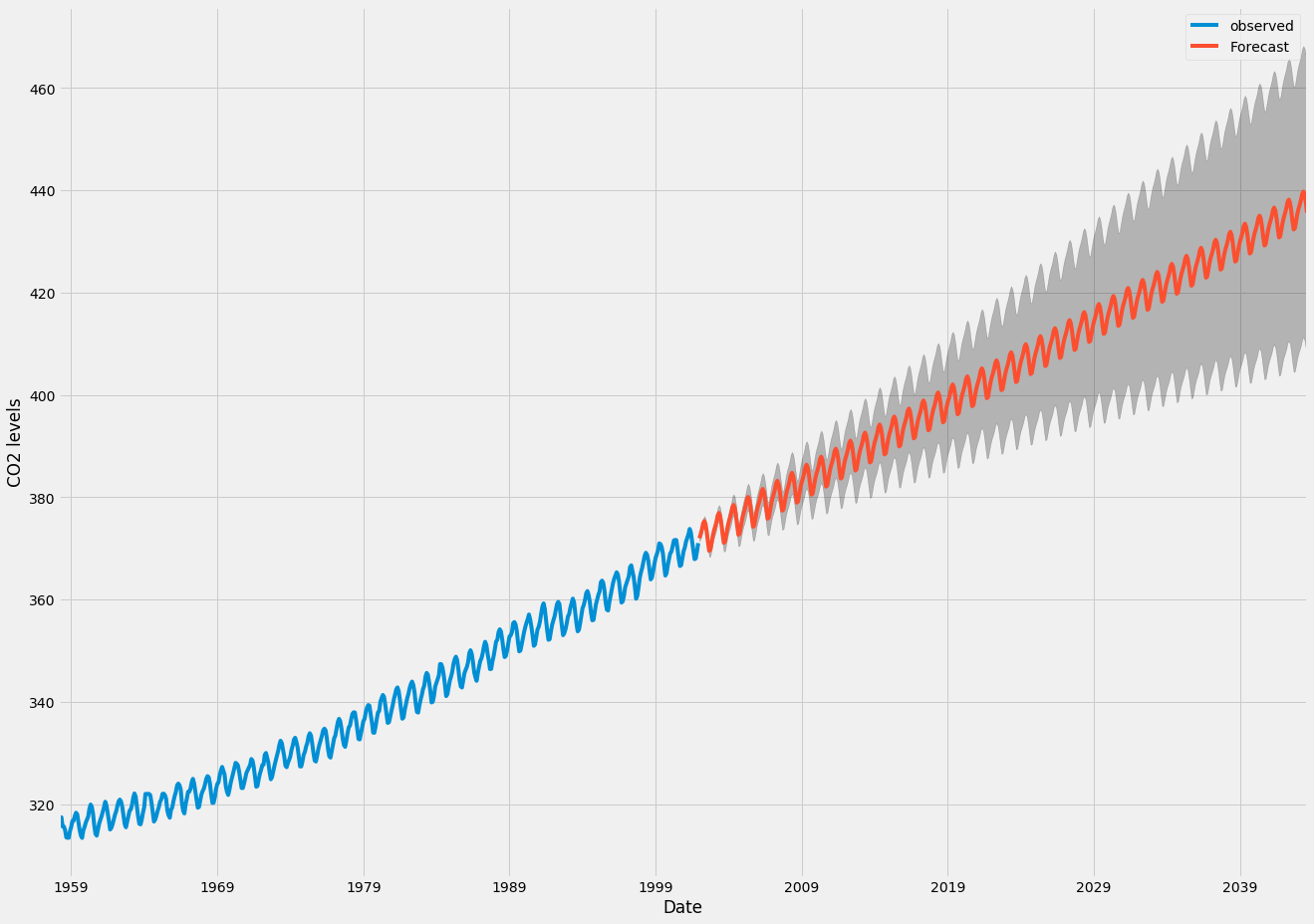
Sowohl die Prognosen als auch das damit verbundene Konfidenzintervall, die wir generiert haben, können nun verwendet werden, um die Zeitreihen besser zu verstehen und vorherzusagen, was zu erwarten ist. Unsere Prognosen zeigen, dass die Zeitreihen voraussichtlich stetig zunehmen werden.
Wenn wir in die Zukunft blicken, ist es für uns selbstverständlich, dass wir unseren Werten weniger vertrauen. Dies spiegelt sich in den Konfidenzintervallen unseres Modells wider, die mit zunehmender Zukunft größer werden.
Fazit
In diesem Tutorial wurde beschrieben, wie Sie ein saisonales ARIMA-Modell in Python implementieren. Wir haben die Bibliothekenpandas undstatsmodels ausgiebig genutzt und gezeigt, wie Modelldiagnosen ausgeführt und Prognosen für die CO2-Zeitreihen erstellt werden.
Hier sind ein paar andere Dinge, die Sie versuchen könnten:
-
Ändern Sie das Startdatum Ihrer dynamischen Prognosen, um festzustellen, wie sich dies auf die Gesamtqualität Ihrer Prognosen auswirkt.
-
Probieren Sie mehrere Parameterkombinationen aus, um festzustellen, ob Sie die Anpassungsgüte Ihres Modells verbessern können.
-
Wählen Sie eine andere Metrik aus, um das beste Modell auszuwählen. Zum Beispiel haben wir das Maß
AICverwendet, um das beste Modell zu finden. Sie können jedoch auch versuchen, den mittleren quadratischen Fehler außerhalb der Stichprobe zu optimieren.
Für mehr Übung können Sie auch versuchen, einen anderen Zeitreihendatensatz zu laden, um Ihre eigenen Prognosen zu erstellen.