Einführung
Sobald Ihre Anwendung in einer Cloud-Server-Umgebung ausgeführt wird, fragen Sie sich möglicherweise, wie Sie Ihre Server-Umgebung verbessern können, um den Sprung von „funktioniert“ zu einer vollwertigen Produktionsumgebung zu schaffen. Dieser Artikel hilft Ihnen beim Einstieg in die Planung und Implementierung einer Produktionsumgebung, indem Sie im Kontext einer Webanwendung in einer Cloud-Server-Umgebung eine lose Definition von „Produktion“ erstellen und einige Komponenten anzeigen, die Sie zu Ihrer vorhandenen hinzufügen können Architektur, um den Übergang zu machen.
Nehmen wir für diese Demonstration an, dass wir mit einem Setup beginnen, das dem unter https://www.digitalocean.com/community/tutorials/5-common-server-setups-for-your-web- beschriebenen ähnelt. application [5 Common Server Setups], wie diese Umgebung mit zwei Servern, die lediglich eine Webanwendung bereitstellt:
image: https://assets.digitalocean.com/articles/architecture/production/it_works.png [Anwendungssetup]
{kind=link}
Ihre eigentliche Einrichtung mag einfacher oder komplexer sein, aber die hier diskutierten allgemeinen Ideen und Komponenten sollten in gewissem Maße für jede Serverumgebung gelten.
Beginnen wir damit, zu definieren, was wir unter „Produktionsumgebung“ verstehen.
Was ist eine Produktionsumgebung?
Eine Serverumgebung für eine Webanwendung besteht im Allgemeinen aus der Hardware, Software, den Daten, den Betriebsplänen und dem Personal, die erforderlich sind, um die Anwendung funktionsfähig zu halten. Eine Produktionsumgebung bezieht sich normalerweise auf eine Serverumgebung, die unter Berücksichtigung der folgenden Faktoren entwickelt und implementiert wurde:
-
* Verfügbarkeit *: Die Möglichkeit, dass die Anwendung von den vorgesehenen Benutzern während der angegebenen Zeiten verwendet werden kann. Die Verfügbarkeit kann durch einen Fehler unterbrochen werden, der eine kritische Komponente stark genug beeinträchtigt (z. Die Anwendung stürzt aufgrund eines Fehlers ab, das Datenbankspeichergerät fällt aus oder der Systemadministrator schaltet den Anwendungsserver versehentlich aus.
Eine Möglichkeit zur Erhöhung der Verfügbarkeit besteht darin, die Anzahl der einzelnen Fehlerquellen in einer Umgebung zu verringern. Die Verwendung einer statischen IP-Adresse und eines Überwachungsfailoverservices stellt beispielsweise sicher, dass Benutzer nur auf funktionsfähige Load Balancer zugreifen. Weitere Informationen finden Sie unter https://www.digitalocean.com/community/tutorials/how-to-use-floating-ips- on-digitalocean # wie-implementiert-man-ein-ha-setup [dieser Abschnitt der Verwendung von Floating IPs] und diese https://www.digitalocean.com/community/tutorials/how-to-set-up-nginx -load-balancing [Artikel zum Load-Balancing].
-
* Wiederherstellbarkeit *: Die Fähigkeit, eine Anwendungsumgebung bei Systemausfall oder Datenverlust wiederherzustellen. Wenn eine kritische Komponente ausfällt und nicht wiederhergestellt werden kann, ist die Verfügbarkeit nicht mehr gegeben. Die Verbesserung der Wartbarkeit, ein verwandtes Konzept, verringert die Zeit, die für die Durchführung eines bestimmten Wiederherstellungsprozesses im Falle eines Fehlers erforderlich ist, und kann daher die Verfügbarkeit im Falle eines Fehlers verbessern
-
* Leistung *: Die Anwendung verhält sich unter Durchschnitts- oder Spitzenlast wie erwartet (z. es reagiert einigermaßen). Obwohl dies für Ihre Benutzer sehr wichtig ist, spielt die Leistung nur eine Rolle, wenn die Anwendung verfügbar ist
Nehmen Sie sich etwas Zeit, um im Kontext Ihrer Anwendung akzeptable Werte für jedes der oben genannten Elemente zu definieren. Dies hängt von der Wichtigkeit und Art der jeweiligen Anwendung ab. Beispielsweise ist es wahrscheinlich akzeptabel, dass ein persönliches Blog, das nur wenigen Besuchern zur Verfügung steht, gelegentlich ausfällt oder eine schlechte Leistung zeigt, solange das Blog wiederhergestellt werden kann. Der Onlineshop eines Unternehmens sollte jedoch durchweg sehr gute Noten erzielen. Natürlich wäre es schön, in jeder Kategorie und für jede Anwendung 100% zu erreichen, aber das ist aus Zeit- und Geldgründen oft nicht machbar.
Beachten Sie, dass wir (a) Hardwarezuverlässigkeit, die Wahrscheinlichkeit, dass eine bestimmte Hardwarekomponente für eine bestimmte Zeit vor dem Ausfall ordnungsgemäß funktioniert, oder (b) Sicherheit nicht als Faktoren erwähnt haben. Dies liegt daran, dass wir davon ausgehen, dass (a) die von Ihnen verwendeten Cloud-Server im Allgemeinen zuverlässig sind, jedoch möglicherweise ausfallen (da sie auf physischen Servern ausgeführt werden), und dass Sie (b) die bewährten Sicherheitsmethoden nach besten Kräften befolgen - Einfach ausgedrückt, sie fallen nicht in den Geltungsbereich dieses Artikels. Sie sollten sich jedoch bewusst sein, dass Zuverlässigkeit und Sicherheit Faktoren sind, die sich direkt auf die Verfügbarkeit auswirken können, und dass beide zur Wiederherstellung beitragen können.
Anstatt Ihnen eine schrittweise Anleitung zum Erstellen einer Produktionsumgebung vorzustellen, die aufgrund der unterschiedlichen Anforderungen und der Art jeder Anwendung nicht möglich ist, werden wir einige konkrete Komponenten vorstellen, mit denen Sie Ihr vorhandenes Setup in eine Produktionsumgebung verwandeln können.
Werfen wir einen Blick auf die Komponenten!
[[1-backup-system]] === 1. Backup System
Ein Backup-System bietet Ihnen die Möglichkeit, regelmäßige Backups Ihrer Daten zu erstellen und Daten aus Backups wiederherzustellen. Backups ermöglichen auch Rollbacks Ihrer Daten in einen früheren Zustand, falls diese versehentlich gelöscht oder ungewollt geändert werden, was unter anderem auf menschliches Versagen zurückzuführen ist. Es besteht die Möglichkeit, dass die gesamte Computerhardware zu einem bestimmten Zeitpunkt ausfällt, was möglicherweise zu Datenverlusten führen kann. Vor diesem Hintergrund sollten Sie aktuelle Sicherungen aller Ihrer wichtigen Daten aufbewahren.
-
Für die Produktion erforderlich? * Ja. Ein Backup-System kann die Auswirkungen von Datenverlusten abschwächen, die zum Erreichen der Wiederherstellbarkeit erforderlich sind, und daher die Verfügbarkeit im Falle eines Datenverlusts verbessern. Es muss jedoch in Verbindung mit soliden Wiederherstellungsplänen verwendet werden, die im nächsten Abschnitt erläutert werden. Beachten Sie, dass die auf Snapshots basierenden Sicherungen von DigitalOcean möglicherweise nicht für alle Ihre Sicherungsanforderungen ausreichen, da sie nicht für Sicherungen aktiver Datenbanken und anderer Anwendungen mit hohem Festplattenschreib-E / A-Aufwand geeignet sind, wenn Sie diese Anwendungstypen ausführen. Wenn Sie mehr Flexibilität bei der Planung von Backups wünschen, sollten Sie ein anderes Backup-System wie Bacula verwenden.
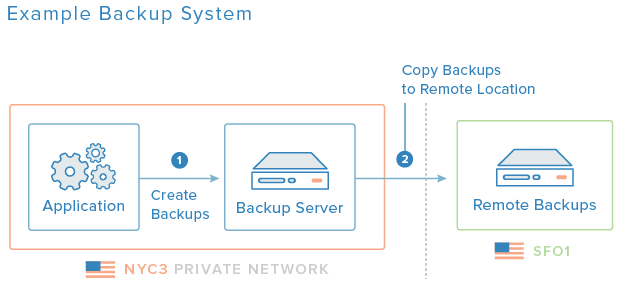
image: https://assets.digitalocean.com/articles/architecture/production/backup_system.png [Beispiel für ein Backup-System]
{kind=link}
Das obige Diagramm ist ein Beispiel für ein grundlegendes Sicherungssystem. Der Sicherungsserver befindet sich im gleichen Rechenzentrum wie die Anwendungsserver, auf denen die ersten Sicherungen erstellt werden. Später werden Kopien der Sicherungen außerhalb des Standorts auf einen Server in einem anderen Rechenzentrum kopiert, um sicherzustellen, dass die Daten beispielsweise im Falle einer Naturkatastrophe erhalten bleiben.
Überlegungen
-
* Sicherungsauswahl: * Die Daten, die Sie sichern werden. Sichern Sie mindestens alle Daten, die Sie nicht zuverlässig von einer alternativen Quelle reproduzieren können
-
* Sicherungszeitplan: * Wann und wie oft werden vollständige oder inkrementelle Sicherungen durchgeführt. Bei Sicherungen bestimmter Datentypen, z. B. aktiver Datenbanken, die sich auf Ihren Sicherungszeitplan auswirken können, müssen besondere Überlegungen getroffen werden
-
* Aufbewahrungszeitraum für Daten: * Wie lange werden Ihre Backups aufbewahrt, bevor sie gelöscht werden
-
* Speicherplatz für Backups: * Die Kombination der drei vorherigen Elemente wirkt sich auf den Speicherplatz aus, den Ihr Backup-System benötigt. Nutzen Sie die Komprimierung und inkrementelle Sicherungen, um den für Ihre Sicherungen erforderlichen Speicherplatz zu verringern
-
Off-Site-Backups: Um Ihre Backups vor lokalen Katastrophen in einem bestimmten Datencenter zu schützen, ist es ratsam, eine Kopie Ihrer Backups an einem geografisch getrennten Ort aufzubewahren. Im obigen Diagramm werden die Sicherungen von NYC3 zu diesem Zweck nach SFO1 kopiert
-
* Backup-Wiederherstellungstests: * Testen Sie regelmäßig Ihren Backup-Wiederherstellungsprozess, um sicherzustellen, dass Ihre Backups ordnungsgemäß funktionieren
Verwandte Tutorials
[[2-recovery-plans]] === 2. Wiederherstellungspläne
Wiederherstellungspläne sind eine Reihe von dokumentierten Verfahren zur Wiederherstellung nach potenziellen Fehlern oder Verwaltungsfehlern in Ihrer Produktionsumgebung. Sie benötigen mindestens einen Wiederherstellungsplan für jedes aus Ihrer Sicht unweigerlich auftretende verkrüppelnde Szenario, z. B. Serverhardwarefehler oder versehentliches Löschen von Daten. Ein sehr grundlegender Wiederherstellungsplan für einen Serverausfall kann beispielsweise aus einer Liste der Schritte bestehen, die Sie zur Durchführung Ihrer ersten Serverbereitstellung ausgeführt haben, einschließlich zusätzlicher Verfahren zum Wiederherstellen von Anwendungsdaten aus Sicherungen. Ein besserer Wiederherstellungsplan kann neben einer guten Dokumentation auch Bereitstellungsskripts und Konfigurationsverwaltungstools wie Ansible, Chef oder Puppet verwenden, um den Wiederherstellungsprozess zu automatisieren und zu beschleunigen.
-
Für die Produktion erforderlich? * Ja. Obwohl Wiederherstellungspläne in Ihrer Serverumgebung nicht als Software vorhanden sind, sind sie eine notwendige Komponente für ein Produktionssetup. Sie ermöglichen es Ihnen, Ihre Backups effektiv zu nutzen und eine Blaupause für die Wiederherstellung Ihrer Umgebung oder das Rollback in einen gewünschten Zustand zu erstellen, wenn dies erforderlich ist.
image: https://assets.digitalocean.com/articles/architecture/production/recovery_plans.png [Beispiel für Wiederherstellungspläne]
{kind=link}
Das obige Diagramm enthält eine Übersicht über einen Wiederherstellungsplan für einen ausgefallenen Datenbankserver. In diesem Fall wird der Datenbankserver durch einen neuen mit der gleichen installierten Software ersetzt, und die letzte ordnungsgemäße Sicherung wird zum Wiederherstellen der Serverkonfiguration und der Daten verwendet. Zuletzt wird der App-Server für die Verwendung des neuen Datenbankservers konfiguriert.
Überlegungen
-
* Verfahrensdokumentation: * Der Satz von Dokumenten, die bei einem Fehlerereignis befolgt werden sollten. Ein guter Ausgangspunkt ist das Erstellen eines schrittweisen Dokuments, anhand dessen Sie einen ausgefallenen Server neu erstellen können. Anschließend werden Schritte zum Wiederherstellen der verschiedenen Anwendungsdaten und der Konfiguration aus Sicherungen hinzugefügt
-
* Automatisierungstools: * Skripts und Konfigurationsverwaltungssoftware bieten Automatisierung, mit der Bereitstellungs- und Wiederherstellungsprozesse verbessert werden können. Schritt-für-Schritt-Anleitungen sind häufig ausreichend, um einen Fehler einfach zu beheben. Sie müssen jedoch von einer Person ausgeführt werden und sind daher nicht so schnell oder konsistent wie ein automatisierter Prozess
-
* Kritische Komponenten: * Die Komponenten, die für die ordnungsgemäße Funktion Ihrer Anwendung erforderlich sind. Im obigen Beispiel sind sowohl der Anwendungsserver als auch der Datenbankserver wichtige Komponenten, da die Anwendung bei einem Ausfall nicht mehr verfügbar ist
-
* Single Points of Failure: * Kritische Komponenten ohne automatischen Failover-Mechanismus gelten als Single Points of Failure. Sie sollten versuchen, einzelne Fehlerquellen so gut wie möglich zu beseitigen, um die Verfügbarkeit zu verbessern
-
* Überarbeitungen: * Aktualisieren Sie Ihre Dokumentation, wenn sich der Bereitstellungs- und Wiederherstellungsprozess verbessert
[[3-load-balancing]] === 3. Lastverteilung
Der Lastenausgleich kann zu einer Serverumgebung hinzugefügt werden, um die Leistung und Verfügbarkeit zu verbessern, indem die Arbeitslast auf mehrere Server verteilt wird. Wenn einer der Server mit Lastenausgleich ausfällt, werden die anderen Server den eingehenden Datenverkehr verarbeiten, bis der ausgefallene Server wieder funktionsfähig ist. In einer Cloud-Server-Umgebung kann der Lastenausgleich normalerweise durch Hinzufügen eines Load-Balancer-Servers implementiert werden, auf dem Load-Balancer-Software (Reverse Proxy) vor mehreren Servern ausgeführt wird, auf denen eine bestimmte Komponente einer Anwendung ausgeführt wird.
-
Für die Produktion erforderlich? * Nicht unbedingt. Der Lastenausgleich ist in einer Produktionsumgebung nicht immer erforderlich, kann jedoch bei korrekter Implementierung eine effektive Möglichkeit sein, die Anzahl der einzelnen Fehlerquellen in einem System zu verringern. Es kann auch die Leistung verbessern, indem durch horizontale Skalierung mehr Kapazität hinzugefügt wird.
image: https://assets.digitalocean.com/articles/architecture/production/load_balancing.png [Lastenausgleich]
{kind=link}
Das obige Diagramm fügt einen zusätzlichen App-Server hinzu, um die Last zu teilen, und einen Load Balancer, um Benutzeranforderungen auf beide App-Server zu verteilen. Dieses Setup kann die Leistung beeinträchtigen, wenn der einzelne App-Server Schwierigkeiten hatte, mit dem Datenverkehr Schritt zu halten, und es kann auch dazu beitragen, die Anwendung verfügbar zu halten, wenn einer der Anwendungsserver ausfällt. Der Datenbankserver und der Lastenausgleichsserver selbst weisen jedoch weiterhin zwei einzelne Fehlerquellen auf.
Überlegungen
-
* Lastenausgleichsfähige Komponenten: * Nicht alle Komponenten in einer Umgebung können problemlos mit Lastenausgleich versehen werden. Bei bestimmten Arten von Software, wie Datenbanken oder statusbehafteten Anwendungen, muss besondere Berücksichtigung gefunden werden
-
* Replikation von Anwendungsdaten: * Wenn ein Anwendungsserver mit Lastenausgleich Anwendungsdaten lokal speichert, z. B. hochgeladene Dateien, müssen diese Daten den anderen Anwendungsservern über Methoden wie Replikation oder gemeinsam genutzte Dateisysteme zur Verfügung gestellt werden. Dies ist erforderlich, um sicherzustellen, dass die Anwendungsdaten verfügbar sind, unabhängig davon, welcher Anwendungsserver für eine Benutzeranforderung ausgewählt wurde
-
* Leistungsengpässe: * Wenn ein Load Balancer nicht über genügend Ressourcen verfügt oder nicht ordnungsgemäß konfiguriert ist, kann dies die Leistung Ihrer Anwendung beeinträchtigen
-
* Single Points of Failure: * Während ein Lastausgleich verwendet werden kann, um Single Points of Failure zu eliminieren, kann ein schlecht geplanter Lastausgleich tatsächlich mehr Single Points of Failure hinzufügen. Der Lastausgleich wird durch die Aufnahme eines zweiten Lastausgleichers mit einer statischen IP vor dem Paar verbessert, der je nach Verfügbarkeit Datenverkehr an das eine oder andere Paar sendet.
Verwandte Tutorials
[[4-monitoring]] === 4. Überwachung
Die Überwachung kann eine Serverumgebung unterstützen, indem der Status von Diensten und die Trends der Serverressourcennutzung verfolgt werden. Auf diese Weise erhalten Sie einen umfassenden Einblick in Ihre Umgebung. Einer der größten Vorteile von Überwachungssystemen besteht darin, dass sie so konfiguriert werden können, dass sie eine Aktion auslösen, z. B. das Ausführen eines Skripts oder das Senden einer Benachrichtigung, wenn ein Dienst oder Server ausfällt oder eine bestimmte Ressource, z. B. CPU, Speicher oder Speicher wird überlastet. Mit diesen Benachrichtigungen können Sie sofort auf Probleme reagieren, um Ausfallzeiten Ihrer Anwendung zu minimieren oder zu verhindern.
-
Erforderlich für die Produktion? * Nicht unbedingt, aber der Überwachungsbedarf steigt mit zunehmender Größe und Komplexität der Produktionsumgebung. Es bietet eine einfache Möglichkeit, Ihre kritischen Dienste und Serverressourcen im Auge zu behalten. Die Überwachung kann wiederum die Wiederherstellbarkeit verbessern und Sie über die Planung und Wartung Ihres Setups informieren.
image: https://assets.digitalocean.com/articles/architecture/production/monitoring.png [Überwachungsbeispiel]
{kind=link}
Das obige Diagramm ist ein Beispiel für ein Überwachungssystem. In der Regel fordert der Überwachungsserver Statusdaten von der Agentensoftware an, die auf den Anwendungs- und Datenbankservern ausgeführt wird, und jeder Agent antwortet mit Software- und Hardwarestatusinformationen. Die Administratoren des Systems können dann über die Überwachungskonsole den Gesamtstatus der Anwendung abrufen und bei Bedarf detailliertere Informationen anzeigen.
Überlegungen
-
* Zu überwachende Dienste: * Die zu überwachenden Dienste und Software. Auf jeden Fall sollten Sie den Status aller Dienste überwachen, die ordnungsgemäß ausgeführt werden müssen, damit Ihre Anwendung ordnungsgemäß funktioniert
-
* Zu überwachende Ressourcen: * Die zu überwachenden Ressourcen. Beispiele für Ressourcen sind CPU, Speicher, Speicher und Netzwerknutzung sowie der Status des Servers insgesamt
-
* Datenaufbewahrung: * Der Zeitraum, in dem Sie Überwachungsdaten aufbewahren, bevor Sie sie verwerfen. Dies wirkt sich zusammen mit der Auswahl der zu überwachenden Elemente auf den Speicherplatz aus, den Ihr Überwachungssystem benötigt
-
* Problemerkennungsregeln: * Die Schwellenwerte und Regeln, die bestimmen, ob sich ein Dienst oder eine Ressource in einem OK-Zustand befindet. Beispielsweise kann ein Dienst oder Server als fehlerfrei angesehen werden, wenn er ausgeführt wird und Anforderungen bedient, während eine Ressource, z. B. ein Speicher, eine Warnung auslösen kann, wenn ihre Auslastung für einen bestimmten Zeitraum einen bestimmten Schwellenwert erreicht
-
* Benachrichtigungsregeln: * Die Schwellenwerte und Regeln, die festlegen, ob eine Benachrichtigung gesendet werden soll. Während Benachrichtigungen wichtig sind, ist es ebenso wichtig, Ihre Benachrichtigungsregeln so anzupassen, dass Sie nicht zu viele erhalten. Ein Posteingang voller Warnungen und Warnungen wird oft ignoriert, was sie fast so nutzlos macht wie gar keine Benachrichtigungen
Verwandte Tutorials
-
Installieren von Nagios 4 und Überwachen Ihrer Server auf Ubuntu 14.04
-
How To Icinga zum Überwachen Ihrer Server verwenden und Dienste auf Ubuntu 14.04
-
How To Install Zabbix on Ubuntu & Configure to Mehrere VPS-Server überwachen
-
Konfigurieren von Sensu Monitoring, RabbitMQ und Redis unter Ubuntu 14,04
[[5-centralized-logging]] === 5. Zentralisierte Protokollierung
Die zentrale Protokollierung kann eine Serverumgebung unterstützen, indem sie eine einfache Möglichkeit bietet, Ihre Protokolle, die normalerweise lokal auf einzelnen Servern in Ihrer gesamten Umgebung gespeichert sind, an einem einzigen Ort anzuzeigen und zu durchsuchen. Abgesehen von der Bequemlichkeit, dass Sie sich nicht bei einzelnen Servern anmelden müssen, um Protokolle zu lesen, können Sie bei der zentralen Protokollierung auch problemlos Probleme identifizieren, die mehrere Server betreffen, indem Sie ihre Protokolle und Metriken während eines bestimmten Zeitrahmens korrelieren. Es bietet außerdem mehr Flexibilität bei der Protokollaufbewahrung, da lokale Protokolle von Anwendungsservern auf einen zentralen Protokollserver ausgelagert werden können, der über einen eigenen, unabhängigen Speicher verfügt.
-
Erforderlich für die Produktion? * Nein, aber genau wie die Überwachung kann die zentralisierte Protokollierung einen unschätzbaren Einblick in Ihre Serverumgebung bieten, da sie an Größe und Komplexität zunimmt. Es ist nicht nur bequemer als die herkömmliche Protokollierung, sondern ermöglicht Ihnen auch die schnelle Überwachung Ihrer Serverprotokolle mit größerer Sichtbarkeit.
image: https://assets.digitalocean.com/articles/architecture/production/centralized_logging.png [Zentralisierte Protokollierung]
{kind=link}
Das obige Diagramm ist ein vereinfachtes Beispiel für ein zentrales Protokollierungssystem. Auf jedem Server ist ein Protokollversandagent installiert, der so konfiguriert ist, dass wichtige App- und Datenbankprotokolle an den zentralen Protokollierungsserver gesendet werden. Die Administratoren des Systems können dann alle wichtigen Protokolle von einer einzigen Konsole aus anzeigen, filtern und durchsuchen.
Überlegungen
-
* Zu sammelnde Protokolle: * Die speziellen Protokolle, die Sie von Ihren Servern an den zentralen Protokollierungsserver senden. Sie sollten die wichtigen Protokolle von all Ihren Servern sammeln
-
* Datenaufbewahrung: * Der Zeitraum, in dem Sie Protokolle aufbewahren, bevor Sie sie verwerfen. Dies wirkt sich zusammen mit der Auswahl der zu sammelnden Protokolle auf den Speicherplatz aus, den Ihr zentrales Protokollierungssystem benötigt
-
* Protokollfilter: * Die Filter, die einfache Protokolle in strukturierte Protokolldaten analysieren. Durch das Filtern von Protokollen können Sie die Daten auf sinnvolle Weise abfragen, analysieren und grafisch darstellen
-
* Server Clocks: * Stellen Sie sicher, dass die Uhren Ihrer Server synchronisiert und auf dieselbe Zeitzone eingestellt sind, damit Ihre Protokollzeitleiste in Ihrer gesamten Umgebung korrekt ist
Fazit
Wenn Sie alle Komponenten zusammenfügen, sieht Ihre Produktionsumgebung möglicherweise folgendermaßen aus:
image: https://assets.digitalocean.com/articles/architecture/production/production.png [Produktion]
{kind=link}
Nachdem Sie mit Komponenten vertraut sind, die zur Unterstützung und Verbesserung einer Produktionsserverkonfiguration verwendet werden können, sollten Sie überlegen, wie Sie diese in Ihre eigenen Serverumgebungen integrieren können. Natürlich haben wir nicht alle Möglichkeiten erörtert, aber dies soll Ihnen eine Vorstellung davon geben, wo Sie anfangen sollen. Denken Sie daran, Ihre Serverumgebung auf der Grundlage Ihrer verfügbaren Ressourcen und Ihrer eigenen Produktionsziele zu entwerfen und zu implementieren.
Wenn Sie eine Umgebung wie die oben beschriebene einrichten möchten, lesen Sie das folgende Tutorial: Building for Production: Web Anwendungen.